About this Article
The main objective of this article is to understand every function of YOLO-v3 implemented in tensorfow. We will understand the algorithm by examining the shape of every output.
The sections below are named by module_name::{ function_1, function_2, ... }, where module_name means we are studying the file module_name.py.
The link of source code are provided at the beginning of each of such sections.
dataset::{ parse_annotation, bbox_iou }
def parse_annotation(self, annotation): line = annotation.split() image_path = line[0] if not os.path.exists(image_path): raise KeyError("%s does not exist ... " % imagparse_annotation e_path) image = cv2.imread(image_path) bboxes = np.array([list(map(int, box.split(','))) for box in line[1:]]) if self.data_aug: image, bboxes = self.random_horizontal_flip(np.copy(image), np.copy(bboxes)) image, bboxes = self.random_crop(np.copy(image), np.copy(bboxes)) image, bboxes = self.random_translate(np.copy(image), np.copy(bboxes)) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image, bboxes = utils.image_preporcess(np.copy(image), [self.train_input_size, self.train_input_size], np.copy(bboxes)) return image, bboxes line = annotation.split() image_path = line[0] if not os.path.exists(image_path): raise KeyError("%s does not exist ... " % image_path) image = cv2.imread(image_path) bboxes = np.array([list(map(int, box.split(','))) for box in line[1:]]) if self.data_aug: image, bboxes = self.random_horizontal_flip(np.copy(image), np.copy(bboxes)) image, bboxes = self.random_crop(np.copy(image), np.copy(bboxes)) image, bboxes = self.random_translate(np.copy(image), np.copy(bboxes)) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) image, bboxes = utils.image_preporcess(np.copy(image), [self.train_input_size, self.train_input_size], np.copy(bboxes)) return image, bboxes
This part is straightforward.
1def bbox_iou(self, boxes1, boxes2): 2 3 boxes1 = np.array(boxes1) 4 boxes2 = np.array(boxes2) 5 6 boxes1_area = boxes1[..., 2] * boxes1[..., 3] 7 boxes2_area = boxes2[..., 2] * boxes2[..., 3] 8 9 boxes1 = np.concatenate([boxes1[..., :2] - boxes1[..., 2:] * 0.5, 10 boxes1[..., :2] + boxes1[..., 2:] * 0.5], axis=-1) 11 boxes2 = np.concatenate([boxes2[..., :2] - boxes2[..., 2:] * 0.5, 12 boxes2[..., :2] + boxes2[..., 2:] * 0.5], axis=-1)
From the function we can deduce that , therefore
and
while concatenating np-array along the last axis simpliy means combing them into one np-array. Numerically in training and are like:
[[0.59375 3.78125 0.5 0.625 ]]
and
[[ 0.5 3.5 3.625 2.8125 ] [ 0.5 3.5 4.875 6.1875 ] [ 0.5 3.5 11.65625 10.1875 ]]
respectively,
13 left_up = np.maximum(boxes1[..., :2], boxes2[..., :2]) 14 right_down = np.minimum(boxes1[..., 2:], boxes2[..., 2:])
Think of the above as entrywise comparisons that give an array of maximum, which yields the coordinates of intersection rectangle for each fixed to boxes in .
15 inter_section = np.maximum(right_down - left_up, 0.0)
The entries in are the and of the intersection, the (broadcasted) is just a tricky way to handle empty intersection.
16 inter_area = inter_section[..., 0] * inter_section[..., 1] 17 union_area = boxes1_area + boxes2_area - inter_area 18 19 return inter_area / union_area
1def preprocess_true_boxes(self, bboxes):
Here are the boxes from annotation file in which each line takes the form:
2 label = [np.zeros((self.train_output_sizes[i], 3 self.train_output_sizes[i], 4 self.anchor_per_scale, 5 5 + self.num_classes)) for i in range(3)] 6 bboxes_xywh = [np.zeros((self.max_bbox_per_scale, 4)) for _ in range(3)] 7 bbox_count = np.zeros((3,)) 8 9 for bbox in bboxes: 10 bbox_coor = bbox[:4] 11 bbox_class_ind = bbox[4] 12 13 onehot = np.zeros(self.num_classes, dtype=np.float) 14 onehot[bbox_class_ind] = 1.0 15 uniform_distribution = np.full(self.num_classes, 1.0 / self.num_classes) 16 deta = 0.01 17 smooth_onehot = onehot * (1 - deta) + deta * uniform_distribution 18 # bbox_xywh is ground truth 19 bbox_xywh = np.concatenate([(bbox_coor[2:] + bbox_coor[:2]) * 0.5, bbox_coor[2:] - bbox_coor[:2]], axis=-1) 20 # bbox_xywh_scaled is scaled ground truth relative to stride (13, 26, 52, as a unit) 21 bbox_xywh_scaled = 1.0 * bbox_xywh[np.newaxis, :] / self.strides[:, np.newaxis]
Note that
is of shape and
is of shape , their multiplication will be conducted by "broadcasting'' in numpy, which yields a dimensional numpy array. The product consists of which use "stride" as a unit, so 1 means "1 grid" (recall there are , , grids predictions from Darknet backbone).
22 iou = [] 23 exist_positive = False 24 for i in range(3): 25 anchors_xywh = np.zeros((self.anchor_per_scale, 4)) 26 anchors_xywh[:, 0:2] = np.floor(bbox_xywh_scaled[i, 0:2]).astype(np.int32) + 0.5 27 anchors_xywh[:, 2:4] = self.anchors[i]
essentially moves centers of to the middle of the grid where the original center lies in, then the anchor boxes' width and height are assigned, replacing the original width, height of .
28 iou_scale = self.bbox_iou(bbox_xywh_scaled[i][np.newaxis, :], anchors_xywh)
The presence of is simply because multiplication between and array does not make sense. The additional dimension expand array into array, which is broadcasted and multiplied to array to give another array, and therefore, .
29 iou.append(iou_scale) 30 iou_mask = iou_scale > 0.3 # a boolean list of length 3 31 32 if np.any(iou_mask): # if one of them is True 33 xind, yind = np.floor(bbox_xywh_scaled[i, 0:2]).astype(np.int32) 34 label[i][yind, xind, iou_mask, :] = 0 35 label[i][yind, xind, iou_mask, 0:4] = bbox_xywh 36 label[i][yind, xind, iou_mask, 4:5] = 1.0 37 label[i][yind, xind, iou_mask, 5:] = smooth_onehot
is initialized at the beginning which is of size
for each , where or .
38 bbox_ind = int(bbox_count[i] % self.max_bbox_per_scale) 39 bboxes_xywh[i][bbox_ind, :4] = bbox_xywh
is initialized (with zeros) at the beginning, .
40 bbox_count[i] += 1 41 42 exist_positive = True 43 44 if not exist_positive: 45 best_anchor_ind = np.argmax(np.array(iou).reshape(-1), axis=-1) # flatten and take max 46 # best_detect belongs to which "i", namely, best "i" 47 best_detect = int(best_anchor_ind / self.anchor_per_scale) 48 # for this i, which index it is: 49 best_anchor = int(best_anchor_ind % self.anchor_per_scale) 50 # get the grid point in our 13x13, 26x26, 52x52 grid: 51 xind, yind = np.floor(bbox_xywh_scaled[best_detect, 0:2]).astype(np.int32) 52 53 label[best_detect][yind, xind, best_anchor, :] = 0 54 label[best_detect][yind, xind, best_anchor, 0:4] = bbox_xywh 55 label[best_detect][yind, xind, best_anchor, 4:5] = 1.0 56 label[best_detect][yind, xind, best_anchor, 5:] = smooth_onehot 57 58 bbox_ind = int(bbox_count[best_detect] % self.max_bbox_per_scale) 59 bboxes_xywh[best_detect][bbox_ind, :4] = bbox_xywh 60 # assign bbox_xywh into the list instead of append, 61 # this is to make sure there are at most 150 boxes within all 3 scales. 62 63 bbox_count[best_detect] += 1 64 label_sbbox, label_mbbox, label_lbbox = label 65 sbboxes, mbboxes, lbboxes = bboxes_xywh 66 return label_sbbox, label_mbbox, label_lbbox, sbboxes, mbboxes, lbboxes
In short,
are just ground truth bounding boxes (center, width and height), while
are ground truth bounding boxes with objectiveness and probabilities of each grid.
Model Structure of YOLOv3
In after a bunch of residue modules we get 3 branches , and , where route_1, route_2, conv = backbone.darknet53(input_layer) in YOLOv3 function. Moreover,
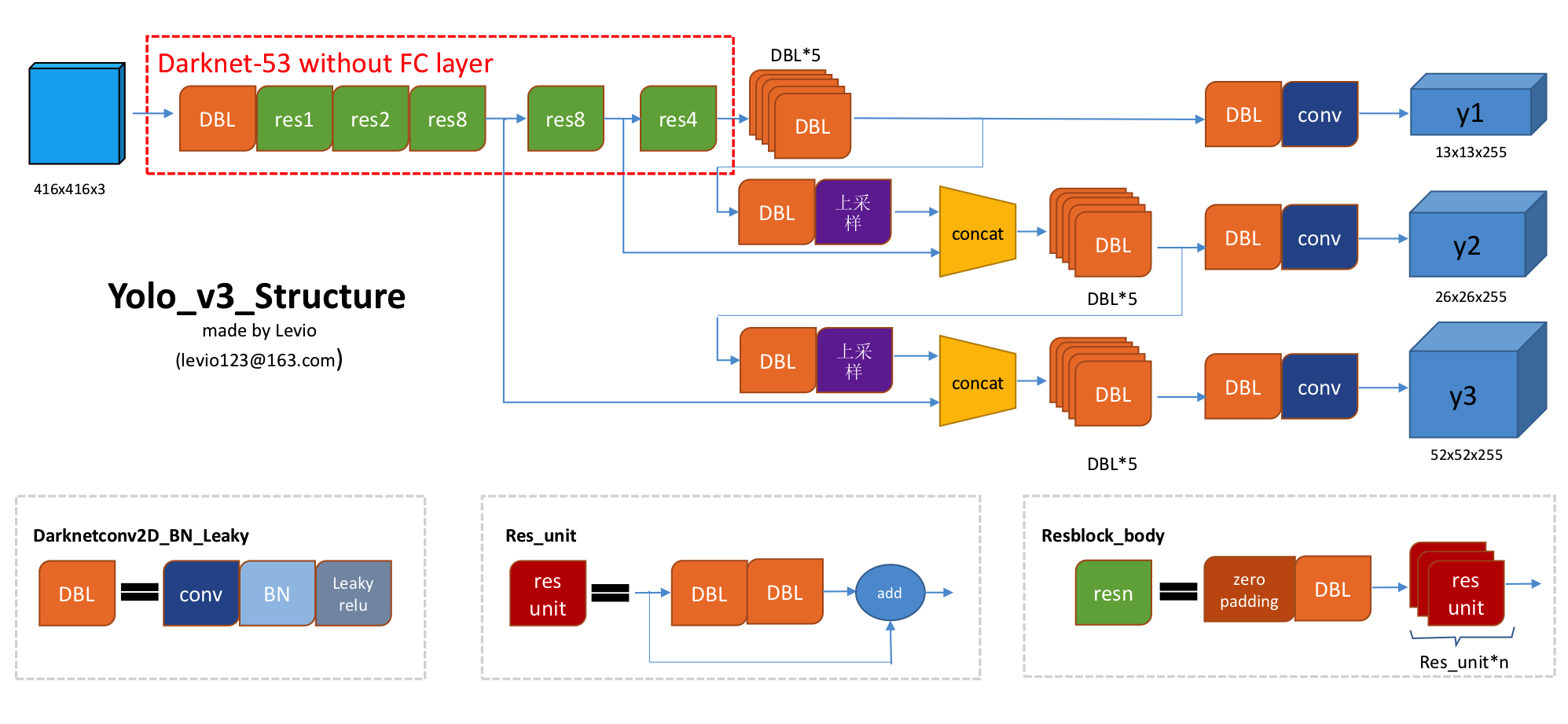
Each branch then jumps into several stages of feature extractions, the whole process finally gives another 3 branches of undecoded/raw data of features, and they are endowed with the meaning of "grid-based detection" after reshaping into
dimensional array in decode function (see conv_output in the body).
yolov3::{ YOLOv3, decode }
1def YOLOv3(input_layer): 2 route_1, route_2, conv = backbone.darknet53(input_layer) 3 4 conv = common.convolutional(conv, (1, 1, 1024, 512)) 5 conv = common.convolutional(conv, (3, 3, 512, 1024)) 6 conv = common.convolutional(conv, (1, 1, 1024, 512)) 7 conv = common.convolutional(conv, (3, 3, 512, 1024)) 8 conv = common.convolutional(conv, (1, 1, 1024, 512))
As padding="same" is being used along the chain of conv nets, there is no spatial dimension change.
9 conv_lobj_branch = common.convolutional(conv, (3, 3, 512, 1024)) 10 conv_lbbox = common.convolutional(conv_lobj_branch, (1, 1, 1024, 3*(NUM_CLASS + 5)), activate=False, bn=False) 11 12 conv = common.convolutional(conv, (1, 1, 512, 256)) 13 conv = common.upsample(conv) 14 15 conv = tf.concat([conv, route_2], axis=-1) 16 17 conv = common.convolutional(conv, (1, 1, 768, 256)) 18 conv = common.convolutional(conv, (3, 3, 256, 512)) 19 conv = common.convolutional(conv, (1, 1, 512, 256)) 20 conv = common.convolutional(conv, (3, 3, 256, 512)) 21 conv = common.convolutional(conv, (1, 1, 512, 256)) 22 23 conv_mobj_branch = common.convolutional(conv, (3, 3, 256, 512)) 24 conv_mbbox = common.convolutional(conv_mobj_branch, (1, 1, 512, 3*(NUM_CLASS + 5)), activate=False, bn=False) 25 26 conv = common.convolutional(conv, (1, 1, 256, 128)) 27 conv = common.upsample(conv) 28 29 conv = tf.concat([conv, route_1], axis=-1) 30 31 conv = common.convolutional(conv, (1, 1, 384, 128)) 32 conv = common.convolutional(conv, (3, 3, 128, 256)) 33 conv = common.convolutional(conv, (1, 1, 256, 128)) 34 conv = common.convolutional(conv, (3, 3, 128, 256)) 35 conv = common.convolutional(conv, (1, 1, 256, 128)) 36 37 conv_sobj_branch = common.convolutional(conv, (3, 3, 128, 256)) 38 conv_sbbox = common.convolutional(conv_sobj_branch, (1, 1, 256, 3*(NUM_CLASS +5)), activate=False, bn=False) 39 40 return [conv_sbbox, conv_mbbox, conv_lbbox]
1def decode(conv_output, i=0): 2 """ 3 return tensor of shape [batch_size, output_size, output_size, anchor_per_scale, 5 + num_classes] 4 contains (x, y, w, h, score, probability) 5 """
is the output of (i.e., , or ).
6 conv_shape = tf.shape(conv_output) 7 batch_size = conv_shape[0] 8 output_size = conv_shape[1] 9 10 conv_output = tf.reshape(conv_output, (batch_size, output_size, output_size, 3, 5 + NUM_CLASS)) 11 12 conv_raw_dxdy = conv_output[:, :, :, :, 0:2] 13 conv_raw_dwdh = conv_output[:, :, :, :, 2:4] 14 conv_raw_conf = conv_output[:, :, :, :, 4:5] 15 conv_raw_prob = conv_output[:, :, :, :, 5: ] 16 17 y = tf.tile(tf.range(output_size, dtype=tf.int32)[:, tf.newaxis], [1, output_size]) 18 x = tf.tile(tf.range(output_size, dtype=tf.int32)[tf.newaxis, :], [output_size, 1])
For example, let's take , then
and
are respectively:
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0] [[ 0 1 2 3 4 5 6 7 8 9 10 11 12] [ 1 1 1 1 1 1 1 1 1 1 1 1 1] [ 0 1 2 3 4 5 6 7 8 9 10 11 12] [ 2 2 2 2 2 2 2 2 2 2 2 2 2] [ 0 1 2 3 4 5 6 7 8 9 10 11 12] [ 3 3 3 3 3 3 3 3 3 3 3 3 3] [ 0 1 2 3 4 5 6 7 8 9 10 11 12] [ 4 4 4 4 4 4 4 4 4 4 4 4 4] [ 0 1 2 3 4 5 6 7 8 9 10 11 12] [ 5 5 5 5 5 5 5 5 5 5 5 5 5] [ 0 1 2 3 4 5 6 7 8 9 10 11 12] [ 6 6 6 6 6 6 6 6 6 6 6 6 6] [ 0 1 2 3 4 5 6 7 8 9 10 11 12] [ 7 7 7 7 7 7 7 7 7 7 7 7 7] [ 0 1 2 3 4 5 6 7 8 9 10 11 12] [ 8 8 8 8 8 8 8 8 8 8 8 8 8] [ 0 1 2 3 4 5 6 7 8 9 10 11 12] [ 9 9 9 9 9 9 9 9 9 9 9 9 9] [ 0 1 2 3 4 5 6 7 8 9 10 11 12] [10 10 10 10 10 10 10 10 10 10 10 10 10] [ 0 1 2 3 4 5 6 7 8 9 10 11 12] [11 11 11 11 11 11 11 11 11 11 11 11 11] [ 0 1 2 3 4 5 6 7 8 9 10 11 12] [12 12 12 12 12 12 12 12 12 12 12 12 12]] [ 0 1 2 3 4 5 6 7 8 9 10 11 12]]
For and we expand dimension again along the last axis (break every single element into a bracketed element) before concatenation:
19 xy_grid = tf.concat([x[:, :, tf.newaxis], y[:, :, tf.newaxis]], axis=-1)
At this point, is dimensional.
20 xy_grid = tf.tile(xy_grid[tf.newaxis, :, :, tf.newaxis, :], [batch_size, 1, 1, 3, 1]) 21 xy_grid = tf.cast(xy_grid, tf.float32)
Now is dimensional. Recall that
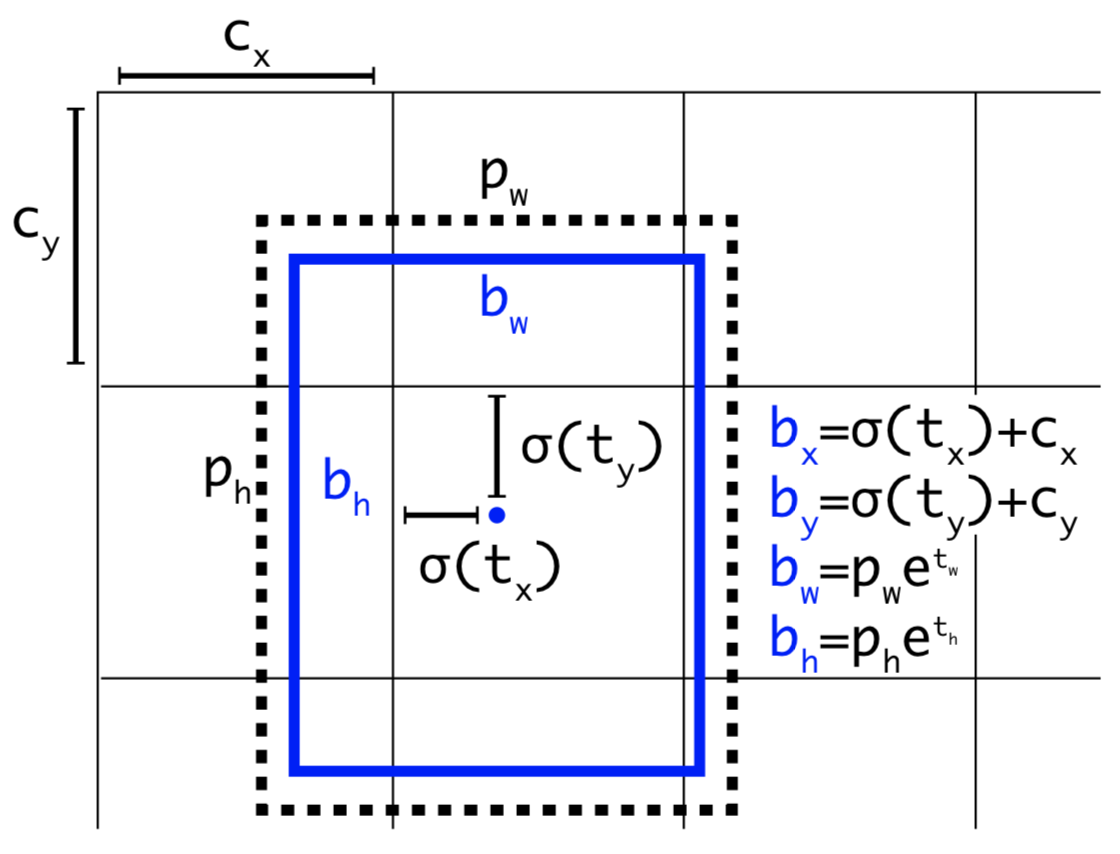
22 pred_xy = (tf.sigmoid(conv_raw_dxdy) + xy_grid) * STRIDES[i] 23 pred_wh = (tf.exp(conv_raw_dwdh) * ANCHORS[i]) * STRIDES[i] 24 pred_xywh = tf.concat([pred_xy, pred_wh], axis=-1) 25 26 pred_conf = tf.sigmoid(conv_raw_conf) 27 pred_prob = tf.sigmoid(conv_raw_prob) 28 29 return tf.concat([pred_xywh, pred_conf, pred_prob], axis=-1)
Bear in mind that decoded , in denote the center of prediction rectangle, as is the output of the function .
yolov3::{ compute_loss }
def bbox_giou(boxes1, boxes2): boxes1 = tf.concat([boxes1[..., :2] - boxes1[..., 2:] * 0.5, boxes1[..., :2] + boxes1[..., 2:] * 0.5], axis=-1) boxes2 = tf.concat([boxes2[..., :2] - boxes2[..., 2:] * 0.5, boxes2[..., :2] + boxes2[..., 2:] * 0.5], axis=-1) boxes1 = tf.concat([tf.minimum(boxes1[..., :2], boxes1[..., 2:]), tf.maximum(boxes1[..., :2], boxes1[..., 2:])], axis=-1) boxes2 = tf.concat([tf.minimum(boxes2[..., :2], boxes2[..., 2:]), tf.maximum(boxes2[..., :2], boxes2[..., 2:])], axis=-1) boxes1_area = (boxes1[..., 2] - boxes1[..., 0]) * (boxes1[..., 3] - boxes1[..., 1]) boxes2_area = (boxes2[..., 2] - boxes2[..., 0]) * (boxes2[..., 3] - boxes2[..., 1]) left_up = tf.maximum(boxes1[..., :2], boxes2[..., :2]) right_down = tf.minimum(boxes1[..., 2:], boxes2[..., 2:]) inter_section = tf.maximum(right_down - left_up, 0.0) inter_area = inter_section[..., 0] * inter_section[..., 1] union_area = boxes1_area + boxes2_area - inter_area iou = inter_area / union_area enclose_left_up = tf.minimum(boxes1[..., :2], boxes2[..., :2]) enclose_right_down = tf.maximum(boxes1[..., 2:], boxes2[..., 2:]) enclose = tf.maximum(enclose_right_down - enclose_left_up, 0.0) enclose_area = enclose[..., 0] * enclose[..., 1] giou = iou - 1.0 * (enclose_area - union_area) / enclose_area return giou
1def compute_loss(pred, conv, label, bboxes, i=0): 2 3 conv_shape = tf.shape(conv) 4 batch_size = conv_shape[0] 5 output_size = conv_shape[1] 6 input_size = STRIDES[i] * output_size 7 conv = tf.reshape(conv, (batch_size, output_size, output_size, 3, 5 + NUM_CLASS)) 8 9 conv_raw_conf = conv[:, :, :, :, 4:5] 10 conv_raw_prob = conv[:, :, :, :, 5:] 11 12 pred_xywh = pred[:, :, :, :, 0:4] 13 pred_conf = pred[:, :, :, :, 4:5] 14 15 label_xywh = label[:, :, :, :, 0:4] 16 respond_bbox = label[:, :, :, :, 4:5] # objectiveness 17 label_prob = label[:, :, :, :, 5:] 18 19 giou = tf.expand_dims(bbox_giou(pred_xywh, label_xywh), axis=-1) 20 input_size = tf.cast(input_size, tf.float32) 21 22 bbox_loss_scale = 2.0 - 1.0 * label_xywh[:, :, :, :, 2:3] * label_xywh[:, :, :, :, 3:4] / (input_size ** 2) 23 giou_loss = respond_bbox * bbox_loss_scale * (1 - giou)
Note that for two sets , where , the function defines a metric, so makes sense.
24 iou = bbox_iou(pred_xywh[:, :, :, :, np.newaxis, :], bboxes[:, np.newaxis, np.newaxis, np.newaxis, :, :])
are batched inside Dataset("train").__next__ before passing into (in a while loop until image count reaches batch size). Therefore , where is the maximal number of anchors (most of them are zeros due to initialization), so we see 3 :'s in .
Finally
and
where computation gets rid of the last dimension. is copied to every grid for computation because from the original paper of YOLOv3:
"the confidence prediction represents the IOU between the predicted box and any ground truth box"
25 max_iou = tf.expand_dims(tf.reduce_max(iou, axis=-1), axis=-1) 26 respond_bgd = (1.0 - respond_bbox) * tf.cast( max_iou < IOU_LOSS_THRESH, tf.float32 )
In the internet some people call as . determines whether to penalize a prediction
- that overlaps too few with ground truth anchors (i.e., detected wrong location) and
- that makes false positive error.
27 conf_focal = tf.pow(respond_bbox - pred_conf, 2)
The concept of focal loss with was introduced in [TY], which down-weights the loss contributed by well-classificed (high confidence) examples.
28 conf_loss = conf_focal * 29 ( 30 respond_bbox * tf.nn.sigmoid_cross_entropy_with_logits(labels=respond_bbox, logits=conv_raw_conf) 31 + 32 respond_bgd * tf.nn.sigmoid_cross_entropy_with_logits(labels=respond_bbox, logits=conv_raw_conf) 33 )
Where is
therefore has to be a raw prediction data (i.e., without signmoid).
34 prob_loss = respond_bbox * tf.nn.sigmoid_cross_entropy_with_logits(labels=label_prob, logits=conv_raw_prob) 35 36 giou_loss = tf.reduce_mean(tf.reduce_sum(giou_loss, axis=[1,2,3,4])) 37 conf_loss = tf.reduce_mean(tf.reduce_sum(conf_loss, axis=[1,2,3,4])) 38 prob_loss = tf.reduce_mean(tf.reduce_sum(prob_loss, axis=[1,2,3,4])) 39 40 return giou_loss, conf_loss, prob_loss
Training
Recap of Customized Training Loop with tf.GradientTape
Apart from predefined loss functions (such as for classfication, for regression, etc), it is ocassional to come across non-standard loss functions from other repository with the use of .
Such implementation usually involves 4 components:
-
Component 1. The model architecture
-
Component 2. The loss function used when computing the model loss
-
Component 3. The optimizer used to update the model weights
-
Component 4. The step function that encapsulates the forward and backward pass of the network
Now the code below is self-explanatory:
Start Training
def train_step(image_data, target, epoch): # image_data = batch of images with tf.GradientTape() as tape: pred_result = model(image_data, training=True) giou_loss = conf_loss = prob_loss = 0 # optimizing process for i in range(3): conv, pred = pred_result[i*2], pred_result[i*2+1] batch_label, batch_bboxes = target[i] loss_items = compute_loss(pred, conv, batch_label, batch_bboxes, i) giou_loss += loss_items[0] conf_loss += loss_items[1] prob_loss += loss_items[2] total_loss = giou_loss + conf_loss + prob_loss gradients = tape.gradient(total_loss, model.trainable_variables) optimizer.apply_gradients(zip(gradients, model.trainable_variables)) # update learning rate global_steps.assign_add(1) if global_steps < warmup_steps: lr = global_steps / warmup_steps * cfg.TRAIN.LR_INIT else: lr = cfg.TRAIN.LR_END + 0.5 * (cfg.TRAIN.LR_INIT - cfg.TRAIN.LR_END) * ( (1 + tf.cos((global_steps - warmup_steps) / (total_steps - warmup_steps) * np.pi)) ) optimizer.lr.assign(lr.numpy()) # writing summary data with writer.as_default(): tf.summary.scalar("lr", optimizer.lr, step=global_steps) tf.summary.scalar("loss/total_loss", total_loss, step=global_steps) tf.summary.scalar("loss/giou_loss", giou_loss, step=global_steps) tf.summary.scalar("loss/conf_loss", conf_loss, step=global_steps) tf.summary.scalar("loss/prob_loss", prob_loss, step=global_steps) writer.flush() for epoch in range(cfg.TRAIN.EPOCHS): for index, (image_data, target) in enumerate(trainset): train_step(image_data, target, epoch) model.save_weights("./checkpoints/yolov3-{}-{}.h5".format(cfg.WEIGHT_NAME_TO_SAVE, epoch))
Reference
-
YOLOv3 源码解析 1-5, https://blog.csdn.net/sxlsxl119/article/details/103028021
-
YOLOv3 算法的一点理解, https://yunyang1994.gitee.io/2018/12/28/YOLOv3/
-
Joseph Redmon, Ali Farhadi, YOLOv3: An Incremental Improvement
-
[TY] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He and Piotr Dollar, Focal Loss for Dense Object Detection
-
Adrian Rosebrock, Using TensorFlow and GradientTape to train a Keras model