Imports for Eninops
import torch import torch.nn.functional as F import matplotlib.pyplot as plt from torch import nn from torch import Tensor from PIL import Image from torchvision.transforms import Compose, Resize, ToTensor from einops import rearrange, reduce, repeat from einops.layers.torch import Rearrange, Reduce
Patch Embedding
Objective
Given an image of shape (3, 224, 224) we perform the following steps in order to produce an output whose shape is the same as what we feed into a transformer (the input should be of shape (batches, seq_len, embed_size))
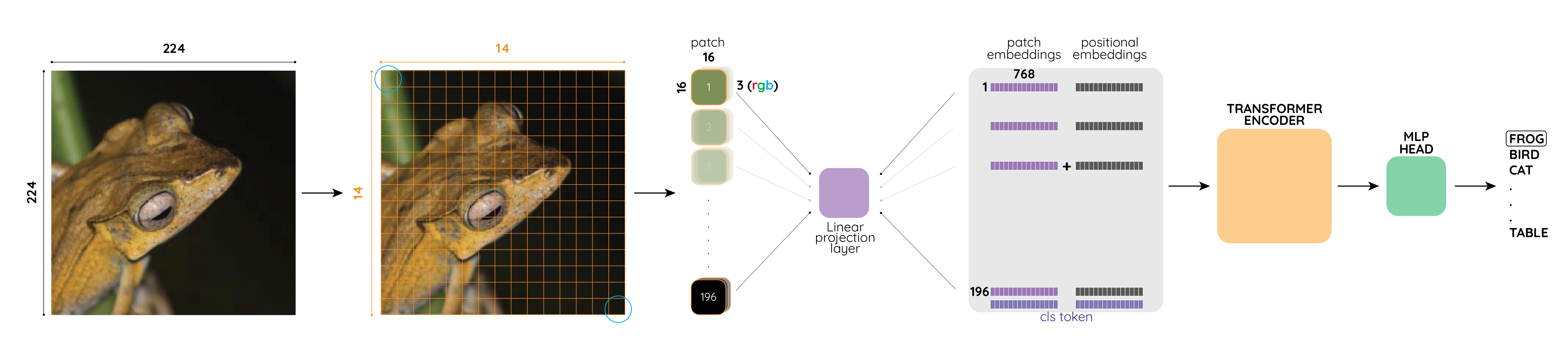
- We first divide an image into patches by squares of size
16x16(i.e.,patch_size=16); - Each of these patches (there are of them) will be mapped into a 1-d feature vector of size .
The two steps above are achieved by a single convolution layer (with kernel size and stride size being equal to patch_size).
Eventually after the patch embedding our feature vector will be of shape:
[batches, 14, 14, 768]
cls Token
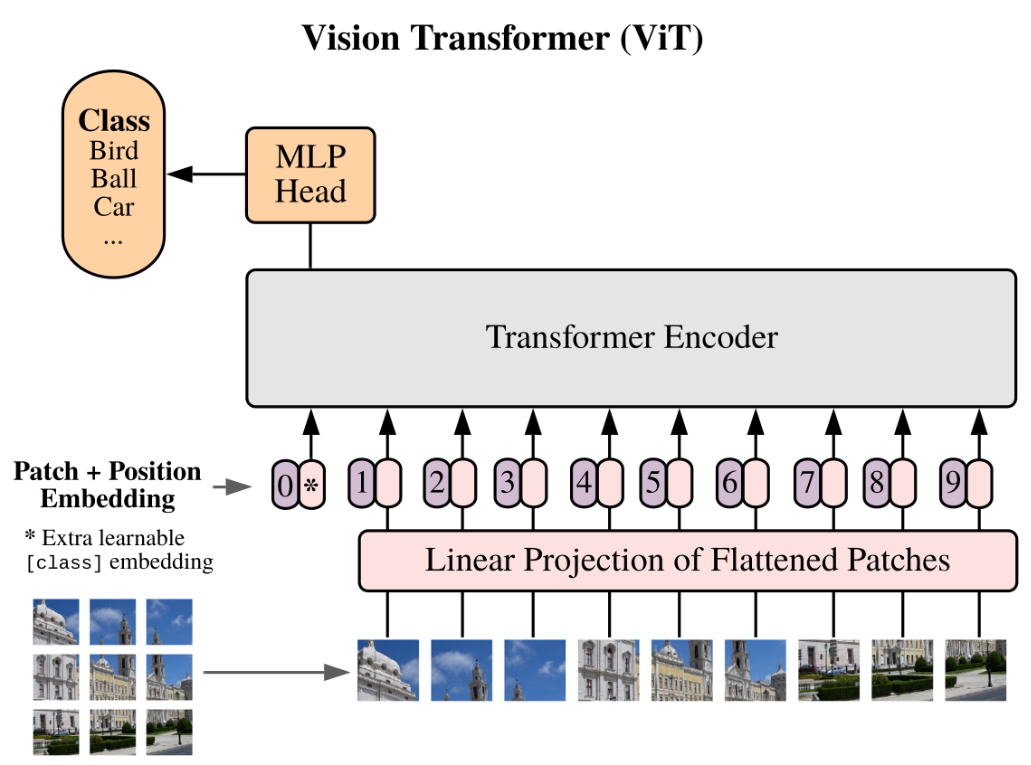
The picture above is taken from the original paper of ViT, we can notice there are 10 "tokens" insteand of 9. The additional one called cls token is added at the beginning as a learning parameter which has the same embedding size as our patched embedding feature vectors.
At the first iteration of transformer encoder block, the cls token already learned the information of all patches due to the self-attention mechanism. We will be doing 12 iterations, and the resulting cls token will be fed into classification head for final prediction.
Another prediction approch can be done without cls token, instead, we keep doing iteration of transformer encoder blocks and take an average along the sequential dimension (see Reduce('b n e -> b e', reduction='mean') in ClassificationHead below). This process can be thought of as a global average pooling.
PatchEmbedding
Step 1: Divide Images into Patches and Map them into 1-d features
class PatchEmbedding(nn.Module): def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768): self.patch_size = patch_size super().__init__() self.projection = nn.Sequential( # the conv layer can be replaced by # Rearrange('b c (h s1) (w s2) -> b (h w) (s1 s2 c)', s1=patch_size, s2=patch_size), nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size), Rearrange('b e (h) (w) -> b (h w) e'), ) def forward(self, x: Tensor) -> Tensor: x = self.projection(x) return x
Step 2: Add cls Token
class PatchEmbedding(nn.Module): def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768): self.patch_size = patch_size super().__init__() self.projection = nn.Sequential( # using a conv layer instead of a linear one -> performance gains nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size), Rearrange('b e (h) (w) -> b (h w) e'), ) self.cls_token = nn.Parameter(torch.randn(1, 1, emb_size)) def forward(self, x: Tensor) -> Tensor: b, _, _, _ = x.shape x = self.projection(x) cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b) # prepend the cls token to the input x = torch.cat([cls_tokens, x], dim=1) return x
Step 3: Add PositionEmbedding
class PatchEmbedding(nn.Module): def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 224): self.patch_size = patch_size super().__init__() self.projection = nn.Sequential( # using a conv layer instead of a linear one -> performance gains nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size), Rearrange('b e (h) (w) -> b (h w) e'), ) self.cls_token = nn.Parameter(torch.randn(1, 1, emb_size)) self.positions = nn.Parameter(torch.randn((img_size // patch_size) **2 + 1, emb_size)) def forward(self, x: Tensor) -> Tensor: b, _, _, _ = x.shape x = self.projection(x) cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b) # prepend the cls token to the input x = torch.cat([cls_tokens, x], dim=1) # add position embedding x += self.positions return x
Transformer Encoder
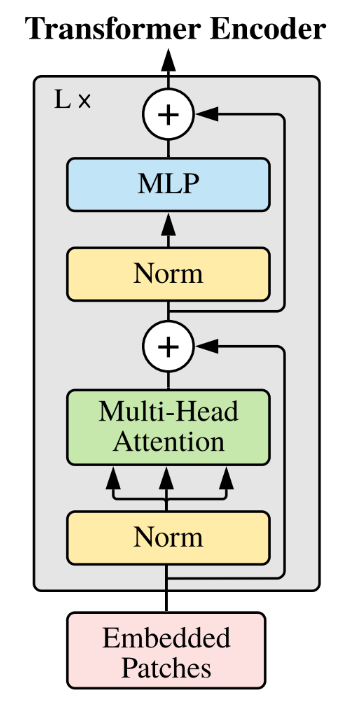
MultiheadAttention
Unlike transformer in machine translation, we only need the encoder part without any masking before softmax.
Version 1
class MultiHeadAttention(nn.Module): def __init__(self, emb_size: int = 768, num_heads: int = 8, dropout: float = 0): super().__init__() self.emb_size = emb_size self.num_heads = num_heads self.keys = nn.Linear(emb_size, emb_size) self.queries = nn.Linear(emb_size, emb_size) self.values = nn.Linear(emb_size, emb_size) self.att_drop = nn.Dropout(dropout) self.projection = nn.Linear(emb_size, emb_size) self.scaling = (self.emb_size // num_heads) ** -0.5 def forward(self, x : Tensor, mask: Tensor = None) -> Tensor: # split keys, queries and values in num_heads queries = rearrange(self.queries(x), "b n (h d) -> b h n d", h=self.num_heads) keys = rearrange(self.keys(x), "b n (h d) -> b h n d", h=self.num_heads) values = rearrange(self.values(x), "b n (h d) -> b h n d", h=self.num_heads) # sum up over the last axis energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys) # batch, num_heads, query_len, key_len if mask is not None: fill_value = torch.finfo(torch.float32).min energy.mask_fill(~mask, fill_value) att = F.softmax(energy, dim=-1) * self.scaling att = self.att_drop(att) # sum up over the third axis out = torch.einsum('bhal, bhlv -> bhav ', att, values) out = rearrange(out, "b h n d -> b n (h d)") out = self.projection(out) return out
Version 2
class MultiHeadAttention(nn.Module): def __init__(self, emb_size: int = 768, num_heads: int = 8, dropout: float = 0): super().__init__() self.emb_size = emb_size self.num_heads = num_heads # fuse the queries, keys and values in one matrix self.qkv = nn.Linear(emb_size, emb_size * 3) self.att_drop = nn.Dropout(dropout) self.projection = nn.Linear(emb_size, emb_size) def forward(self, x : Tensor, mask: Tensor = None) -> Tensor: # split keys, queries and values in num_heads qkv = rearrange(self.qkv(x), "b n (h d qkv) -> (qkv) b h n d", h=self.num_heads, qkv=3) queries, keys, values = qkv[0], qkv[1], qkv[2] # sum up over the last axis energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys) # batch, num_heads, query_len, key_len if mask is not None: fill_value = torch.finfo(torch.float32).min energy.mask_fill(~mask, fill_value) scaling = self.emb_size ** (1/2) att = F.softmax(energy, dim=-1) / scaling att = self.att_drop(att) # sum up over the third axis out = torch.einsum('bhal, bhlv -> bhav ', att, values) out = rearrange(out, "b h n d -> b n (h d)") out = self.projection(out) return out
MLP
class FeedForwardBlock(nn.Sequential): def __init__(self, emb_size: int, expansion: int = 4, drop_p: float = 0.): super().__init__( nn.Linear(emb_size, expansion * emb_size), nn.GELU(), nn.Dropout(drop_p), nn.Linear(expansion * emb_size, emb_size), )
ResidualAdd
class (nn.Module): def __init__(self, fn): super().__init__() self.fn = fn def forward(self, x, **kwargs): res = x x = self.fn(x, **kwargs) x += res return x
TransformerEncoderBlock
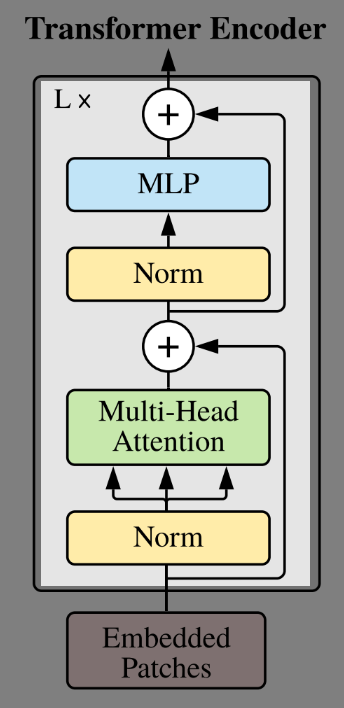
class TransformerEncoderBlock(nn.Sequential): def __init__(self, emb_size: int = 768, drop_p: float = 0., forward_expansion: int = 4, forward_drop_p: float = 0., ** kwargs): super().__init__( ResidualAdd(nn.Sequential( nn.LayerNorm(emb_size), MultiHeadAttention(emb_size, **kwargs), nn.Dropout(drop_p) )), ResidualAdd(nn.Sequential( nn.LayerNorm(emb_size), FeedForwardBlock( emb_size, expansion=forward_expansion, drop_p=forward_drop_p), nn.Dropout(drop_p) )) )
TransformerEncoder
class TransformerEncoder(nn.Sequential): def __init__(self, depth: int = 12, **kwargs): super().__init__(*[TransformerEncoderBlock(**kwargs) for _ in range(depth)])
ClassificationHead
class ClassificationHead(nn.Sequential): def __init__(self, emb_size: int = 768, n_classes: int = 1000): super().__init__( # It is also possible to just take the first entry in the last dimension Reduce('b n e -> b e', reduction='mean'), nn.LayerNorm(emb_size), nn.Linear(emb_size, n_classes) )
Vi-sual T-ransformer
class ViT(nn.Sequential): def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 224, depth: int = 12, n_classes: int = 1000, **kwargs): super().__init__( PatchEmbedding(in_channels, patch_size, emb_size, img_size), TransformerEncoder(depth, emb_size=emb_size, **kwargs), ClassificationHead(emb_size, n_classes) )