Package Needed
Package Needed
pip install boto3
Python Script to Download top n Log-streams of a Log-group
Python Script to Download top n Log-streams of a Log-group
# cloudwatch.py import boto3 import os import argparse import locale from datetime import datetime locale.setlocale(locale.LC_CTYPE, "chinese") def text_transform(text): try: return text.encode().decode("unicode_escape").replace("\t"," ") except Exception as e: print(f"{e}") def timestamp_transform(timestamp): return datetime.fromtimestamp(timestamp/1000).strftime("%Y-%m-%d %H:%M:%S") def main(): parser = argparse.ArgumentParser() parser.add_argument('--log_group', action='store',type=str) parser.add_argument('--start', type=str) parser.add_argument('--end', type=str) parser.add_argument('--region', type=str, help='region', default="ap-southeast-2") parser.add_argument('-n', type=int, help='Number of logstreams', default=1) args = parser.parse_args() LOG_GROUP = args.log_group FROM_TIMESTAMP = args.start END_TIMESTAMP = args.end REGION_NAME = args.region N = args.n client = boto3.client('logs', region_name=REGION_NAME) print("----- LogGroup Availables -----") for desc in client.describe_log_groups()["logGroups"]: print(desc["logGroupName"]) print("-----") should_end = False if LOG_GROUP is None: print("Argument: --log_group= \tFor example: //ecs/billie-chat-prod, ('/' will be resolved into local file system in git-bash)") should_end = True else: LOG_GROUP = args.log_group.replace("//", "/") if FROM_TIMESTAMP is None: print("Argument: --start= \texample: \"2024-05-09 12:00:00\" in your local time") print("Argument: --end= \tis optional and the default is set to be current" ) should_end = True else: FROM = datetime.strptime(FROM_TIMESTAMP, '%Y-%m-%d %H:%M:%S').strftime('%Y-%m-%d_%H時%M分%S秒') FROM_TIMESTAMP = int(datetime.strptime(FROM_TIMESTAMP, '%Y-%m-%d %H:%M:%S').timestamp()*1000) END_TIMESTAMP = int(datetime.strptime(END_TIMESTAMP, '%Y-%m-%d %H:%M:%S').timestamp()*1000) \ if END_TIMESTAMP is not None \ else int(datetime.now().timestamp()*1000) if should_end is True: return print("LOG_GROUP\t",LOG_GROUP) print("TIMESTAMP\t", FROM_TIMESTAMP, ">>", END_TIMESTAMP) LOG_DIR = "./cloudwatch-logs" LOG_GROUP_ = LOG_GROUP.replace("/","-") FILE_NAME = f"log{LOG_GROUP_}-from-{FROM}" if not os.path.exists(LOG_DIR): os.makedirs(LOG_DIR) log_group_name=LOG_GROUP log_streams = client.describe_log_streams( logGroupName=log_group_name, orderBy="LastEventTime", descending=True ) log_stream_names = [desc["logStreamName"] for desc in log_streams["logStreams"]][0: N][::-1] i = 0 SAVE_DESTINIATION=f"{LOG_DIR}/{FILE_NAME}.log" if os.path.exists(SAVE_DESTINIATION): os.unlink(SAVE_DESTINIATION) with open(SAVE_DESTINIATION, "a+", encoding="utf8") as file: for log_stream_name in log_stream_names: i += 1 print() print(f"Downloading [{i}-th stream: {log_stream_name}] ...") response = {"nextForwardToken": None} started = False page = 0 n_lines = 0 while started is False or response['nextForwardToken'] is not None: started = True page += 1 karg = {} if response['nextForwardToken'] is None else {"nextToken": response['nextForwardToken']} response = client.get_log_events( startTime=FROM_TIMESTAMP, endTime=END_TIMESTAMP, logGroupName=log_group_name, logStreamName=log_stream_name, startFromHead=True, **karg ) data = response["events"] data = sorted(data, key=lambda datum: datum["timestamp"]) data_ = [{"timestamp": timestamp_transform(datum["timestamp"]), "message": text_transform(datum["message"]) } for datum in data] if len(data_) == 0: if page > 1: print() print("No more data for the current stream") break n_lines += len(data_) print(f"Loading Page {page}, accumulated: {n_lines} lines ", end="\r") for datum in data_: line = datum["timestamp"] +" |" + "\t" + datum["message"] +"\n" file.write(line) if __name__ == "__main__": main()
Usage
Usage
Log all Available Log-groups
Log all Available Log-groups
By running
python cloudwatch.py
yields
----- LogGroup Availables ----- /aws/lambda/google-auth-billi-web-dev-api /aws/lambda/google-auth-billi-web-poc-api /aws/lambda/google-auth-billi-web-poc-uat-api /aws/lambda/google-auth-billi-web-prod-api /aws/lambda/google-auth-billi-web-uat-api /aws/lambda/node-google-auth-lambda-dev-api /aws/lambda/nodejs-billie-report-excel-lambda-dev-api /aws/lambda/wb-backend-python-dev-api /ecs/billie-chat-poc /ecs/billie-chat-prod /ecs/billie-chat-uat /ecs/wb-platform-prod ----- Argument: --log_group For example: //ecs/billie-chat-prod, ('/' will be resolved into local file system in git-bash) Argument: --start example: "2024-05-09 12:00:00" in your local time Argument: --end is optional and the default is set to be current
Log n Logstreams of a Log-group Started from a Timestamp
Log n Logstreams of a Log-group Started from a Timestamp
python cloudwatch.py \ --log_group="//ecs/billie-chat-prod" \ --start="2024-05-09 20:00:00" \ --end="2024-05-09 23:59:59" \ -n=10
where n is the number of log_stream's counted from the top:
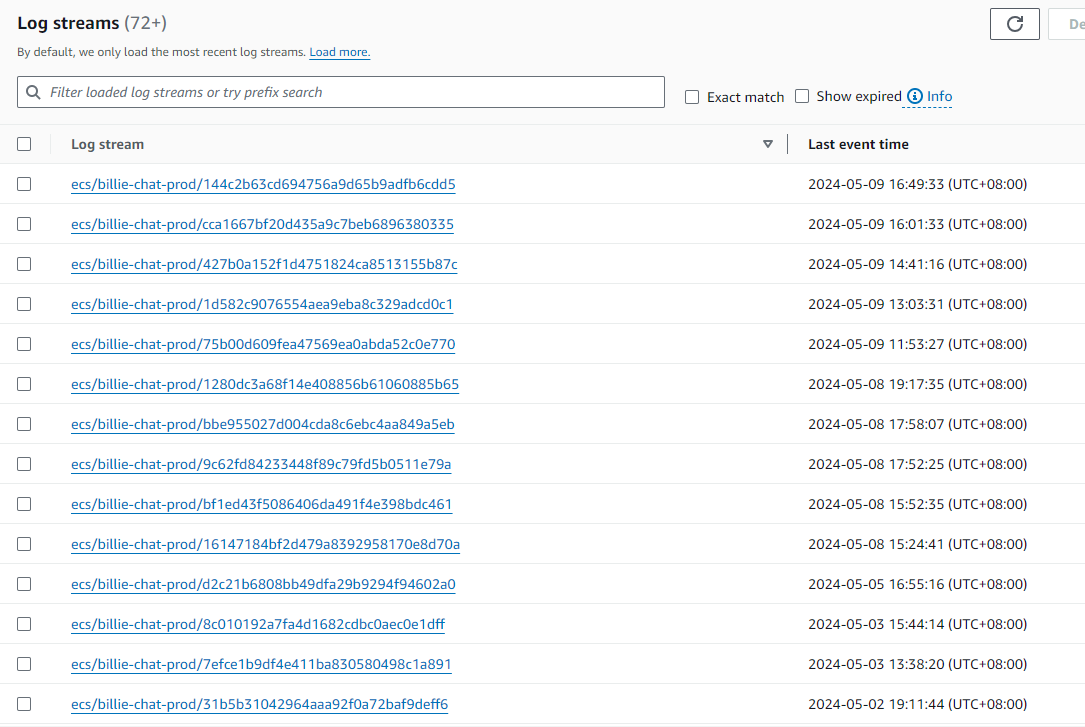
Downloaded Result
Downloaded Result
The file will be saved in cloudwatch-logs/

which looks
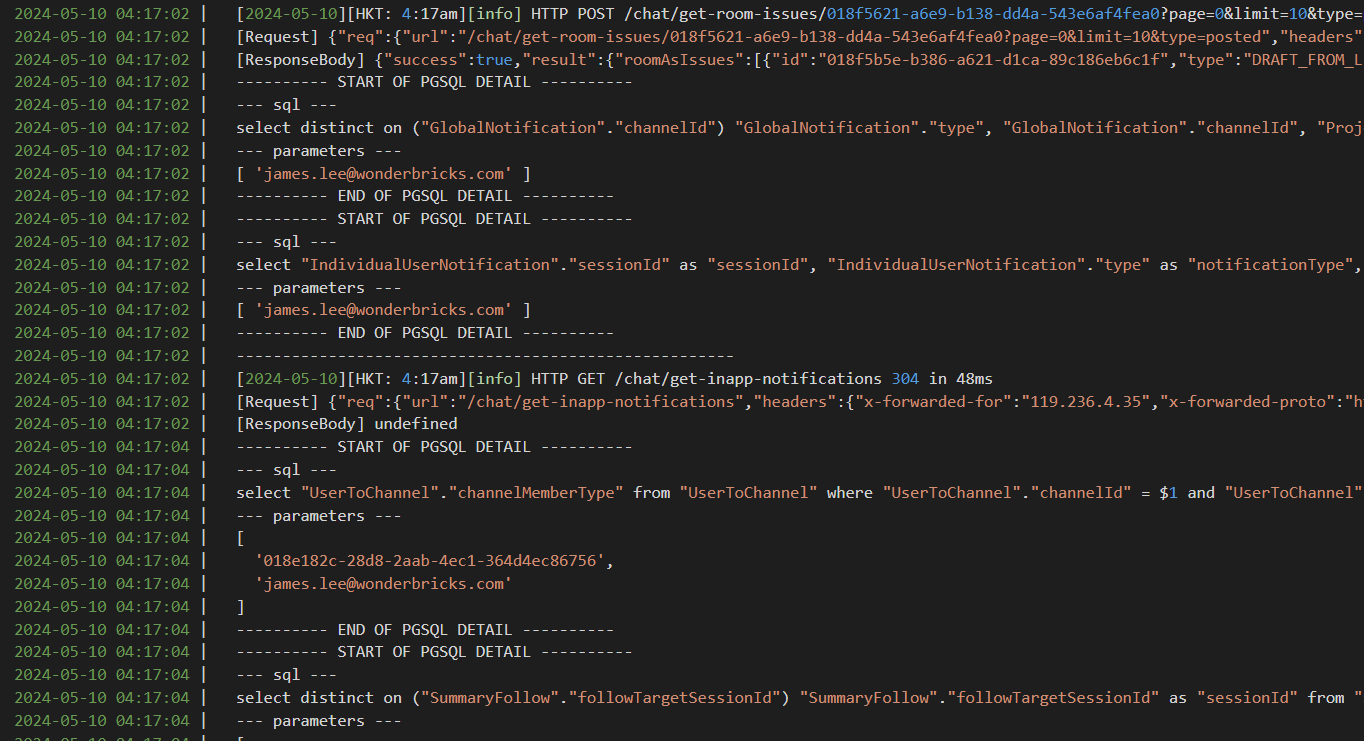
A complete txt log in a whole day can exceed 200Mb.