The Result
WIDTH_BUCKET
The Definition
According to this page:
WIDTH_BUCKET(expr, minExpr, maxExpr, numBuckets)
Arguments
exprAn expression to be bucketed.minExprAn expression providing a lower bound for the buckets.maxExprAn expression providing an upper bound for the buckets.numBucketsAnINTEGERexpression greater than 0 specifying the number of buckets.
If expr is numeric, minExpr and maxExpr must also be numeric.
SQL Experiment and Explanation
SQL Explains
Consider the following SQL which basically calculates the daily usage of our voice recognition API whose cost is calculated directly by the total length of the audioes:
We approximate the length of the audio by the start time and end time from frontend application:
WITH tmp AS (SELECT WIDTH_BUCKET( "Message"."createdAt", 1716825599999, 1719417599999, 30 ) AS "width_bucket", ( ( "Voice"."frontendEndTime"::DECIMAL(20, 2) - "Voice"."frontendStartTime"::DECIMAL(20, 2) ) / 1000 )::real AS "length" FROM "MessagesSession" LEFT JOIN "Message" ON "Message"."messagesSessionId" = "MessagesSession"."id" LEFT JOIN "Voice" ON "Voice"."messageId" = "Message"."id" WHERE "Message"."userId" = '018def77-4dad-aa93-80fd-3319ceb44c68' AND "Message"."type" = 'Voice' AND "MessagesSession"."type" = 'PUBLIC_CHATROOM' AND "Message"."createdAt" < 1719417599999 ) SELECT * FROM tmp
SQL Query Result
Click to see Complete Query Result
width_bucket length 0 11.785 0 16.954 0 21.115 0 34.537 0 18.55 0 13.543 0 19.559 0 22.307 0 18.976 0 12.467 0 7.16 0 23.645 0 4.442 0 11.936 0 21.565 0 9.852 0 8.956 0 16.138 0 6.208 0 9.371 0 4.86 0 17.677 0 14.063 0 13.619 0 18.487 0 6.896 0 24.246 0 14.214 0 16.658 0 23.565 0 16.193 0 24.727 0 24.221 0 16.344 0 7.417 0 23.225 0 18.854 0 17.89 0 25.549 0 5.436 0 33.023 0 26.496 0 14.875 0 25.761 0 8.783 0 6.146 0 11.108 0 3.314 0 19.699 0 15.869 0 4.193 0 25.001 0 11.013 0 5.78 0 30.151 0 41.247 0 16.357 0 20.049 0 6.636 0 28.666 0 12.218 0 3.203 0 6.773 0 6.97 0 6.072 0 3.037 0 3.136 0 8.258 0 3.68 0 2.622 0 3.594 0 4.505 0 4.379 0 3.897 0 2.672 0 7.482 0 3.431 0 5.205 0 3.959 0 6.849 0 4.372 0 2.674 0 3.444 0 8.118 0 8.827 0 5.014 0 4.047 0 7.055 0 6.206 0 5.153 0 8.194 0 8.163 0 11.244 0 16.88 0 4.976 0 17.886 0 5.801 0 17.981 0 6.654 0 7.832 0 11.301 0 4.093 0 11.067 0 5.641 0 24.228 0 7.949 0 13.995 0 14.606 0 21.563 0 13.28 0 20.835 0 11.264 0 23.612 0 35.813 0 16.002 0 11.376 0 21.865 0 18.859 0 5.154 0 25.375 0 21.526 0 14.447 0 9.907 0 5.006 0 22.379 0 15.99 0 17.917 0 19.319 0 15.077 0 12.523 0 5.919 0 6.089 0 21.034 0 17.065 0 10.542 0 6.173 0 9.128 0 6.491 0 12.566 0 9.723 0 10.421 0 11.108 0 10.925 0 11.373 0 11.552 0 2.179 0 3.59 0 1.889 0 3.572 0 4.812 0 2.323 0 2.47 0 15.459 0 3.735 0 3.216 0 2.474 0 4.299 0 3.821 0 1.53 0 1.519 0 6.953 0 3.845 0 3.491 0 6.577 0 5.372 0 9.613 0 3.314 0 2.865 0 5.737 0 5.546 0 5.349 0 2.424 0 4.067 0 6.518 0 2.376 0 3.459 0 6.545 0 2.001 0 1.784 0 1.652 0 2.97 0 10.225 0 2.774 0 9.55 0 2.912 0 2.301 0 2.024 0 2.885 0 2.245 0 1.628 0 1.809 0 2.182 0 1.534 0 1.653 0 1.768 0 1.703 0 1.546 0 3.098 0 1.977 0 3.01 0 1.826 0 1.932 0 1.326 0 3.204 0 2.052 0 2.066 0 2.195 0 1.68 0 1.868 0 2.406 0 1.99 0 1.948 0 1.908 0 1.879 0 1.657 0 1.827 0 1.841 0 1.656 0 2.084 0 1.971 0 1.974 0 2.305 0 2.155 0 2.942 0 2.858 0 3.263 0 5.071 0 2.951 0 8.79 0 5.114 0 6.789 0 2.755 0 2.736 0 2.021 0 7.034 0 6.536 0 7.118 0 5.195 0 8.177 0 3.06 0 3.708 0 5.823 0 5.751 0 2.444 0 2.352 0 2.51 0 1.55 0 8.241 0 8.205 0 3.365 0 6.093 0 3.043 0 2.002 0 3.322 0 2.421 0 2.686 0 4.471 0 4.992 0 4.263 0 3.279 13 1.539 13 2.153 13 1.542 11 5.65 11 4.096 13 1.733 13 3.111 13 1.659 13 1.56 10 8.173 17 3.16 17 7.23 18 3.607 18 4.426 25 2.892 25 4.879 25 6.658 25 3.542 29 3.659 30 4.741 30 12.218
For the query only the highlighted part is important, the rest is just a business logic.
Wait ..., WIDTH_BUCKET(..., 30) but there are 31 values?!
WIDTH_BUCKET(..., 30) but there are 31 values?!When we look at the query result it is natural to think of the following problems
-
Problem 1. We want to partition the range into 30 buckets but there are 0, 1, ..., 30, a total of 31 values from the query result.
-
Problem 2. There are so many
width_bucketindexed by 0.
Investigation
Let's explain:
-
Here the upper value
1719417599999is the unix timestamp of the end time of the day:Wed Jun 26 2024 23:59:59 -
The lower value
1716825599999isand it is approximately a start day as well.
-
This line
SELECT WIDTH_BUCKET( "Message"."createdAt", 1716825599999, 1719417599999, 30 ) as "width_bucket"hashes the value
"Message"."createdAt"into one of theindex's as follows:where with the end-day and the day-length:
The closeness and openness of the ends in are referred from this page.
-
Note also that from our
WHEREclause our data is strictly less than . Therefore the partition above completely covers the range of our possible values.
Conclusion
In general the expression
SELECT WIDTH_BUCKET(expr, min, max, n)
produces indexes given that .
Multi-Column Bar-Chart
Adjust the SQL Using With temp AS (...)
With temp AS (...)Let's slightly adjust the SQL to completely give summed values in each partition:
WITH tmp AS (SELECT WIDTH_BUCKET( "Message"."createdAt", 1716825599999, 1719417599999, 30 ) AS "width_bucket", ( ( "Voice"."frontendEndTime"::DECIMAL(20, 2) - "Voice"."frontendStartTime"::DECIMAL(20, 2) ) / 1000 )::real AS "length" FROM "MessagesSession" LEFT JOIN "Message" ON "Message"."messagesSessionId" = "MessagesSession"."id" LEFT JOIN "Voice" ON "Voice"."messageId" = "Message"."id" WHERE "Message"."userId" = '018def77-4dad-aa93-80fd-3319ceb44c68' AND "Message"."type" = 'Voice' AND "MessagesSession"."type" = 'PUBLIC_CHATROOM' AND "Message"."createdAt" < 1719417599999 ) SELECT "width_bucket", SUM("length") AS "length" from tmp GROUP BY "width_bucket"
Which reduces our query result into:
width_bucket length 0 2306.765 <-- to be discarded 10 8.173 11 9.746 13 13.297 17 10.39 18 8.033 25 17.971 29 3.659 30 16.959
From typescript this data is further reduced into the interface
// day is the millisecond of an end-day. { day: number, total: number }[]
by
1const lengthByDay = Array(numOfDays).fill(null) 2 .map((_, bucket) => (bucket + 1)) 3 .map(bucket => { 4 const total = sum(lengthByBucket.filter(v => v.width_bucket === bucket).map(v => v.length)); 5 const day = (startDay as Dayjs).add(bucket, "day").valueOf(); 6 return { day, total } 7 })
Note that in line 2 we have +1 to map {0, 1, ..., numOfDays} to {1, ..., numOfDays + 1} because we realize index 0 is meaningless (it is the sum of values that are out of range)
The JS part Using ag-charts-react
ag-charts-reactSuppose that we have queried 3 sets of data having the same interface (for emphasis let's define again):
type DailyUsage = { day: number, total: number }[] issueData: DailyUsage = [] session: DailyUsage = [] reply: DailyUsage = []
Our chart is produced by:
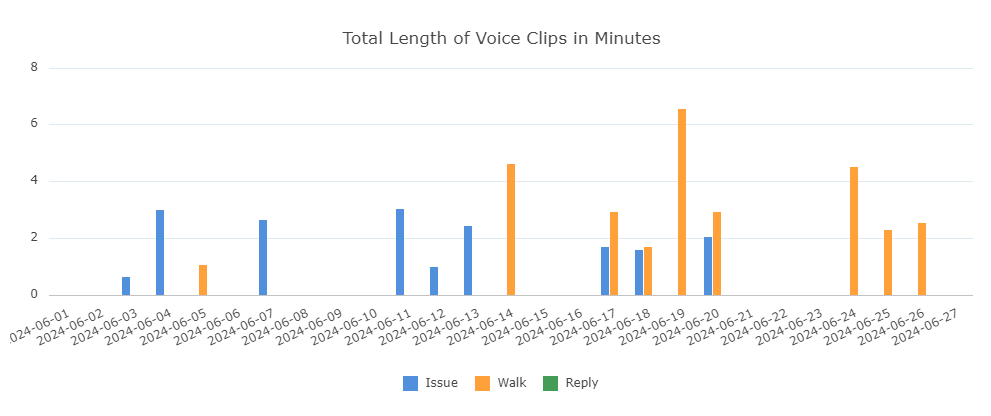
import { AgChartsReact } from "ag-charts-react"; export default () => { ... const voiceLengthsData = const voiceLengthsData = Array(numOfDaysForVoices).fill(null).map((_, index) => { const issue = issueData[index]; const session = sessionData[index]; const reply = replyData[index]; const day = dayjs(issue?.day).format("YYYY-MM-DD"); return { day, Issue: (issue?.total || 0) / 60, Walk: (session?.total || 0) / 60, Reply: (reply?.total || 0) / 60 } }) const voiceSeries = [ { type: "bar", xKey: "day", yKey: "Issue", }, { type: "bar", xKey: "day", yKey: "Walk", }, { type: "bar", xKey: "day", yKey: "Reply", }, ] return ( ... <AgChartsReact options={{ title: { text: "Total Length of Voice Clips in Minutes" }, type: "bar", data: voiceLengthsData, // @ts-ignore series: voiceSeries }} /> ) }
Again the result:
In conclusion:
-
We define an array of
serieswhich configues what is shown onx-axis and that ony-axis, by specifying whichkeywe want to map in thedata. -
The display data,
data, is represented by an array of object with interface{x: string, y1: number, y2: number, y3: number}[]
More from Documentation
https://charts.ag-grid.com/react/axes-secondary/
Example: