Backend Migration
Resource needed
- Resources need to be created manually
We need to create
- S3 Bucket
Transit the State from Terraform Cloud to S3-Bucket
For existing state in HCP terrraform
Unforturnately there is no simple migration from HCL terraform cloud to s3 bucket. When running terraform init -migrate-state we will get:
Please use the API to do this: https://www.terraform.io/docs/cloud/api/state-versions.html /state-versions API reference for HCP Terraform | Terraform | HashiCorp Developer (https://developer.hashicorp.com/terraform/cloud-docs/api-docs/state-versions)
So when we have stored our terraform state in terraform cloud, the easiest migration is to directly replicate the infrastructure with s3-bucket as the store.
Create the s3_backend.tf
s3_backend.tfThe new s3_backend.tf:
terraform { backend "s3" { bucket = "some-state-bucket" key = "my-application-prod-v5/state.tfstate" region = "ap-southeast-2" encrypt = true use_lockfile = true } }
Note that now we control our workspace by key.
Unlike old documentation:
-
Nowadays latest terraform does not need the
dynamodb_table. -
Terraform does not rely on dynamodb as a distributive state lock, it simply uses conditional PUT operation to create a
.lockfile.The conditional header used by terraform is:
If-None-Match: *
Which only succeeds if the object doesn't already exist.
-
The presence of
.lockfile indicates there is currently a infra-migration process, and the operations will fail until the lock is released.
Terragrunt
Installation
For mac we can directly execute
brew install terragrunt
Application Module
Structure
Recall that this article we have been in this intermediate step:
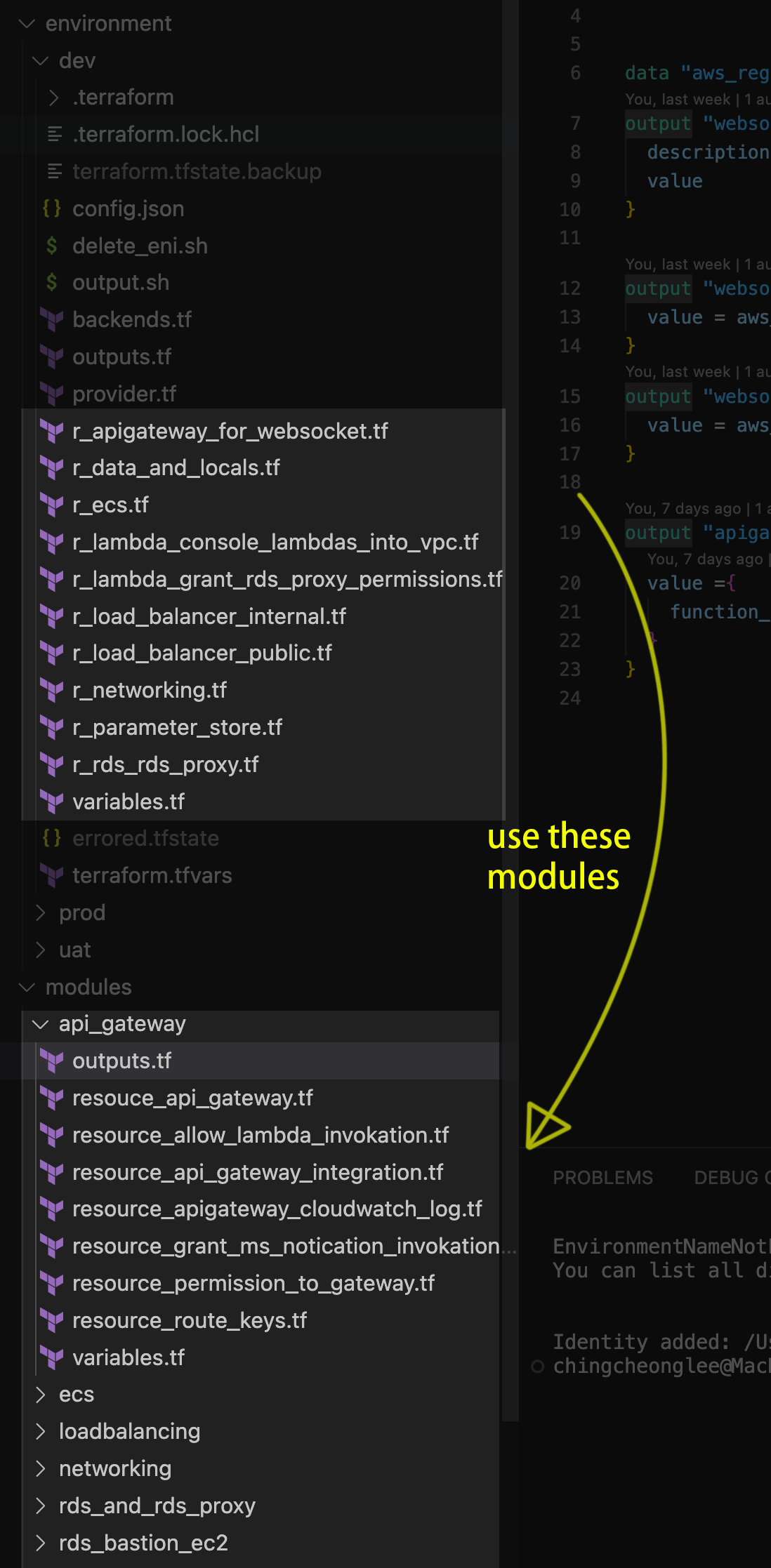
Instead of creating our custom application module that wraps the r_xxx files, let's try to use terragrunt to generate code which works like a wrapped module.
For the sake of study let's use the following much simpler project:
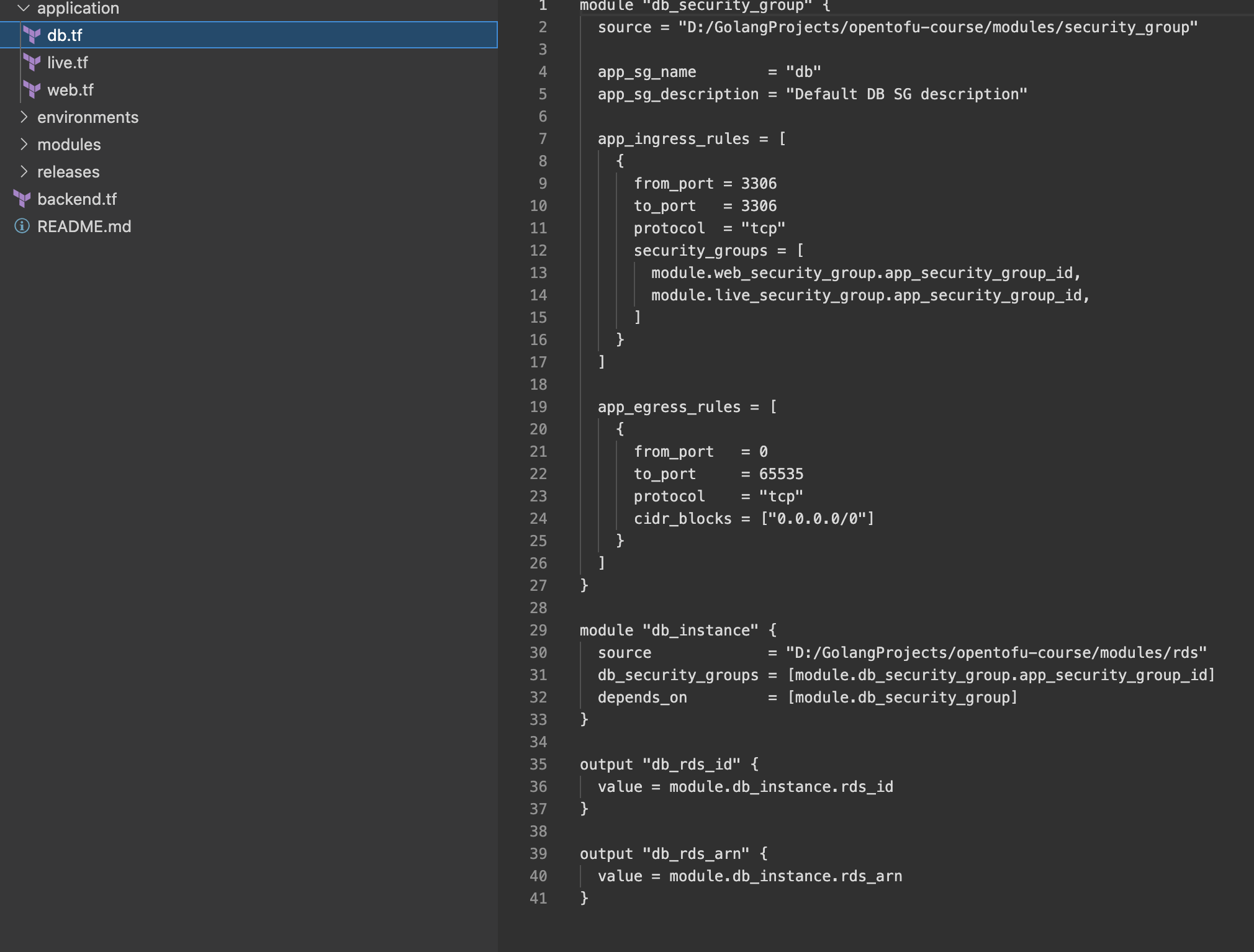
Now we wrap the resource tf files into a single module:
Shared variables
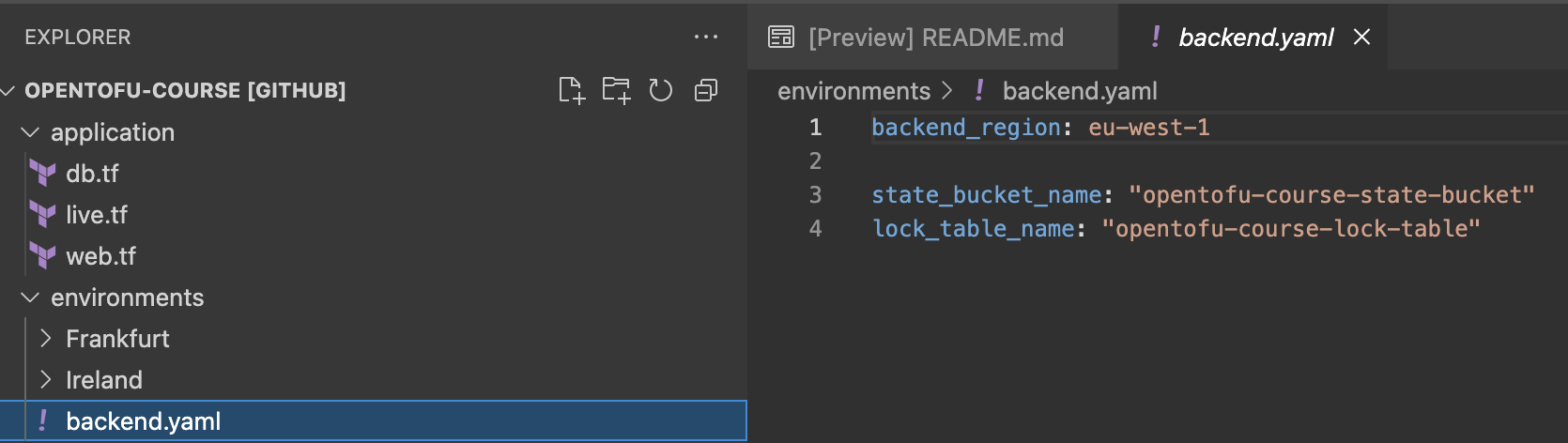
For shaded variables (which are always constant among different deployment stages) we define a yml file at the outmost level:
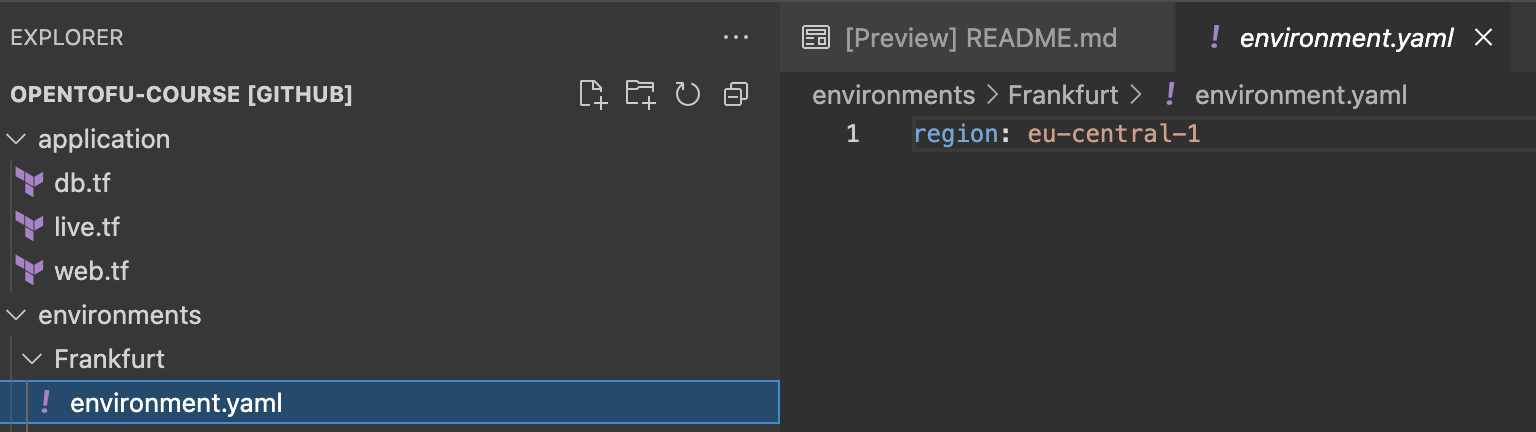
Stage-specific variables
Load the variables
Create terragrunt.hcl

and write
1# terragrunt.hcl 2 3locals { 4 backend_data = yamldecode(file(find_in_parent_folders("backend.yaml"))) 5 environment_data = yamldecode(file("environment.yaml")) 6} 7 8inputs = merge( 9 local.backend_data, 10 local.environment_data 11)
At this point the modules refereneced in terraform block in terragrunt.hcl can access variables such as var.backend_region becuase
- it is defined in
local.backend_dataand - it is inside
mergefunction.
Load the Application Module
This is the module that we would like to "duplicate" by terragrunt.
12terraform { 13 source = "../../application" 14 15 # before_hook "notification" { 16 # commands = ["apply", "plan"] 17 # execute = ["cmd", "/C", "echo", "Running application on ${local.environment_data["region"]} region."] 18 # } 19}
Files to generate before terraform execution
20generate "providers" { 21 path = "providers.tf" 22 if_exists = "overwrite" 23 contents = <<EOF 24provider "aws" { 25 region = "${local.environment_data["region"]}" 26} 27EOF 28}
Note that line-21 is the path of the file that is to be generated.
Generate backend before terraform execution
29remote_state { 30 backend = "s3" 31 generate = { 32 path = "backend.tf" 33 if_exists = "overwrite" 34 } 35 config = { 36 bucket = local.backend_data["state_bucket_name"] 37 key = "${local.environment_data["region"]}/terraform.tfstate" 38 region = local.backend_data["backend_region"] 39 encrypt = true 40 dynamodb_table = local.backend_data["lock_table_name"] 41 } 42}
line 33 is also the file that is to be generated.
Should we use terragrunt?
There are two stands towards if we should use terragrunt. I personally wouldn't use terragrunt because I have already moduliarized my own infra structure, which is already a "DRY" implementation.
Without terragrunt there would also be code duplication of:
- variables.tf
- backends.tf
- provider.tf
but to me the code duplication comes with clarity on the configuration of each environment, which do me more good than harm.