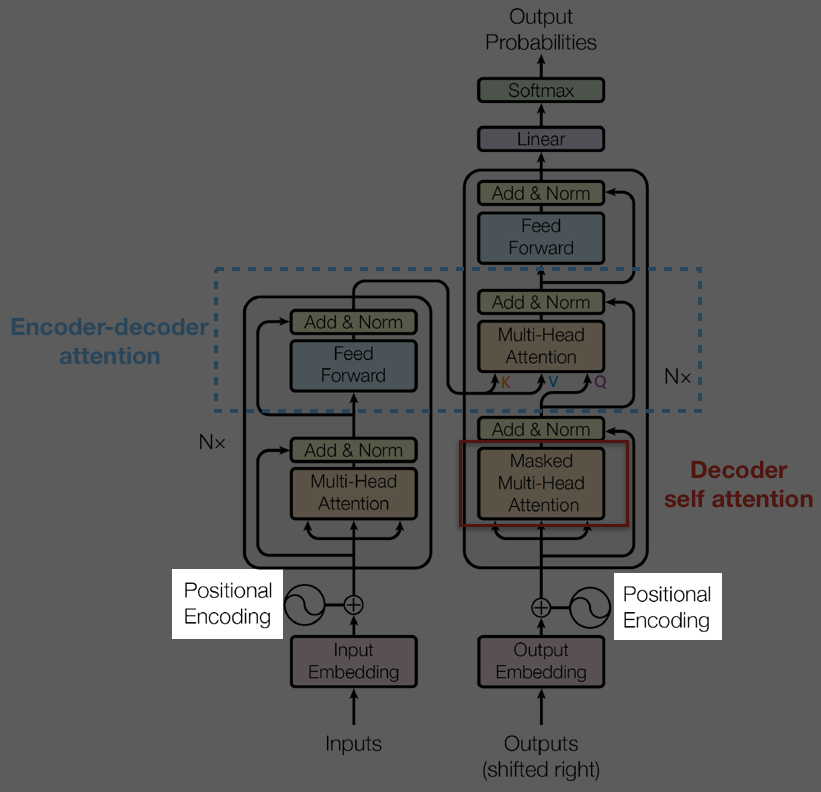
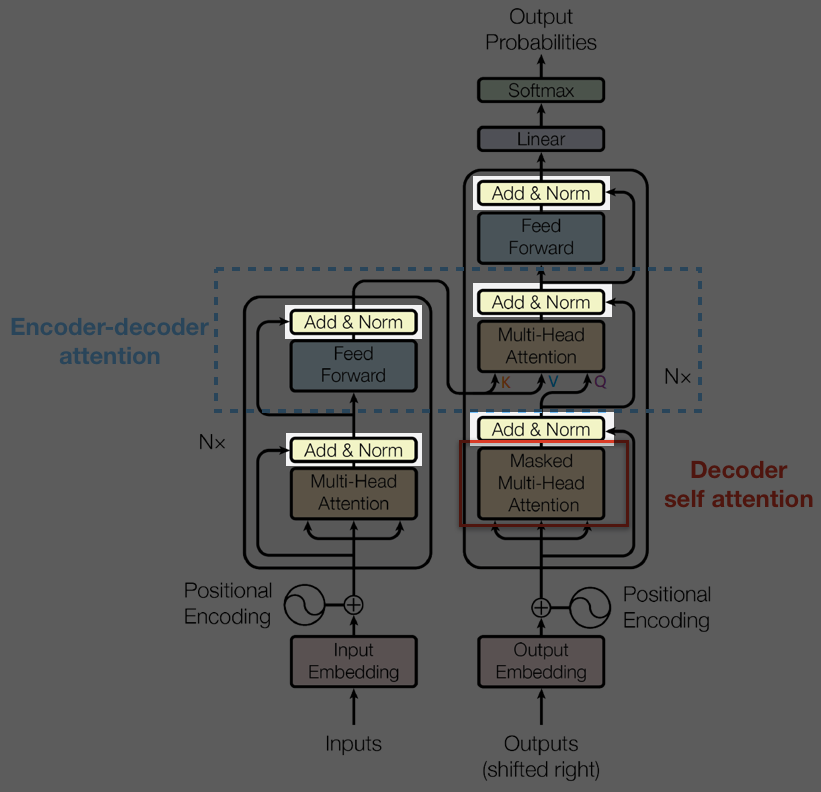
Grahpical Structure of Transformer
Constants in the Config
d_model = 512 # Embedding Size d_ff = 2048 # FeedForward dimension d_k = d_v = 64 # dimension of K(=Q), V n_layers = 6 # number of Encoder of Decoder Layer n_heads = 8 # number of heads in Multi-Head Attention
Positional Encoding
A positional encoding
is a mapping that takes a positional index to a vector of word embedding dimension. In terms of -array,
where and .
class PositionalEncoding(nn.Module): def __init__(self, d_model, dropout=0.1, max_len=5000): super(PositionalEncoding, self).__init__() self.dropout = nn.Dropout(p=dropout) pe = torch.zeros(max_len, d_model) position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) div_term = torch.exp( torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model) ) pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) # unfreeze to prepare for batches of word embeddings pe = pe.unsqueeze(0).transpose(0, 1) self.register_buffer('pe', pe) def forward(self, x): ''' x: [seq_len, batch_size, d_model] ''' x = x + self.pe[:x.size(0), :] return self.dropout(x)
PoswiseFeedForwardNet
class PoswiseFeedForwardNet(nn.Module): def __init__(self): super(PoswiseFeedForwardNet, self).__init__() self.fc = nn.Sequential( nn.Linear(d_model, d_ff, bias=False), nn.ReLU(), nn.Linear(d_ff, d_model, bias=False) ) def forward(self, inputs): ''' inputs: [batch_size, seq_len, d_model] ''' residual = inputs output = self.fc(inputs) # [batch_size, seq_len, d_model] return nn.LayerNorm(d_model).to(device)(output + residual)
Attentions
Scaled Dot Product Attention
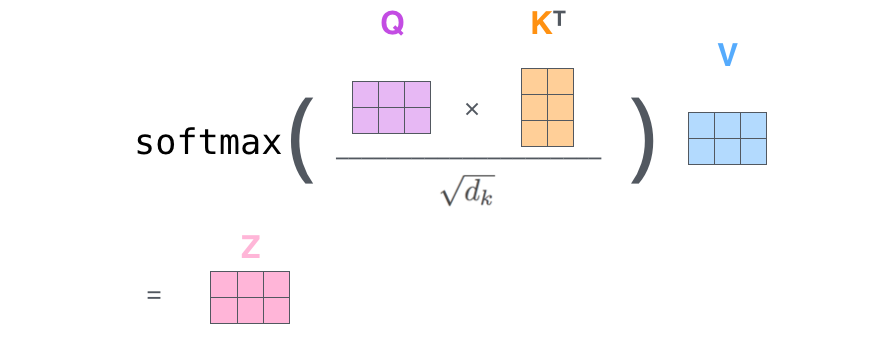
class ScaledDotProductAttention(nn.Module): def __init__(self): super(ScaledDotProductAttention, self).__init__() def forward(self, Q, K, V, attn_mask): ''' Q: [batch_size, n_heads, len_q, d_k] K: [batch_size, n_heads, len_k, d_k] V: [batch_size, n_heads, len_v(=len_k), d_v] attn_mask: [batch_size, n_heads, seq_len, seq_len] ''' # scores : [batch_size, n_heads, len_q, len_k] scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # Fills elements of self tensor with value where mask is True. scores.masked_fill_(attn_mask, -1e9) attn = nn.Softmax(dim=-1)(scores) # [batch_size, n_heads, len_q, d_v]: context = torch.matmul(attn, V) return context, attn
attn_mask is used to mask out value of undesired position such as
- those from padding or
- those from "future word" in self-attention module of decoder.
Repeated Use of ScaledDotProductAttention: Multi-head Attention
class MultiHeadAttention(nn.Module): def __init__(self): super(MultiHeadAttention, self).__init__() self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False) self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False) self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False) self.fc = nn.Linear(n_heads * d_v, d_model, bias=False) def forward(self, input_Q, input_K, input_V, attn_mask): ''' input_Q: [batch_size, len_q, d_model] input_K: [batch_size, len_k, d_model] input_V: [batch_size, len_v(=len_k), d_model] attn_mask: [batch_size, seq_len, seq_len] ''' residual, batch_size = input_Q, input_Q.size(0) # (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W) # Q: [batch_size, n_heads, len_q, d_k] Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # K: [batch_size, n_heads, len_k, d_k] K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # V: [batch_size, n_heads, len_v(=len_k), d_v] V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1, 2) # attn_mask : [batch_size, n_heads, seq_len, seq_len] attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k] context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask) # context: [batch_size, len_q, n_heads * d_v] context = context.transpose(1, 2).reshape( batch_size, -1, n_heads * d_v) output = self.fc(context) # [batch_size, len_q, d_model] return nn.LayerNorm(d_model).to(device)(output + residual), attn
Mask Creation
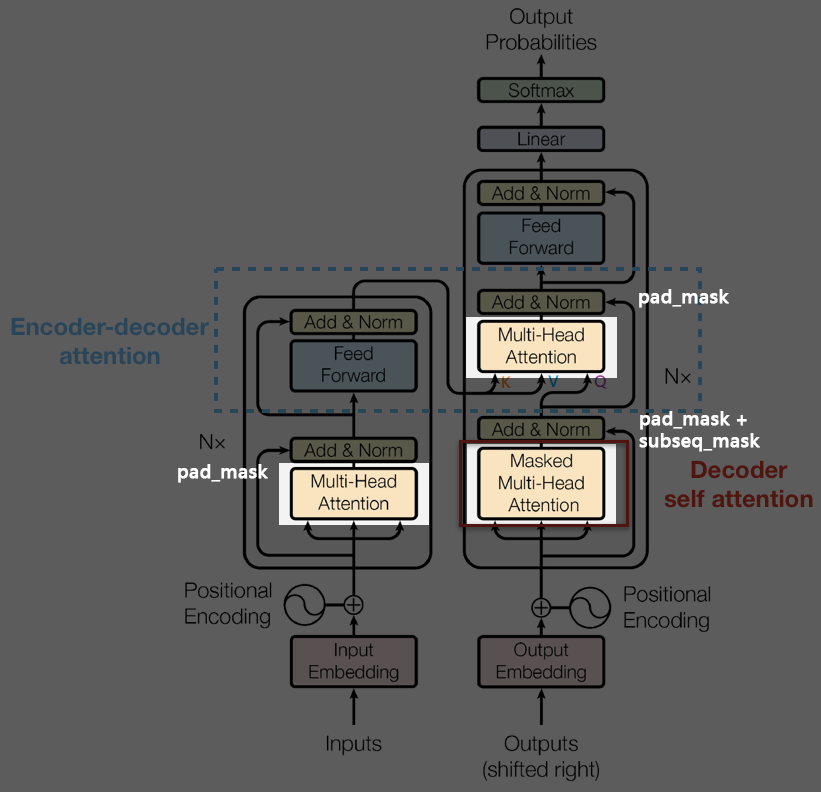
get_attn_pad_mask
1def get_attn_pad_mask(seq_q, seq_k, pad=0): 2 ''' 3 seq_q: [batch_size, seq_len] 4 seq_k: [batch_size, seq_len] 5 seq_len could be src_len or it could be tgt_len 6 seq_len in seq_q and seq_len in seq_k maybe not equal 7 ''' 8 batch_size, len_q = seq_q.size() 9 batch_size, len_k = seq_k.size() 10 # eq(pad) is PAD token 11 # [batch_size, 1, len_k], True is masked 12 pad_attn_mask = seq_k.eq(pad).unsqueeze(1) 13 # [batch_size, len_q, len_k] 14 return pad_attn_mask.expand(batch_size, len_q, len_k)
To apply get_attn_pad_mask, input that we want to mask will be fed into the second argument.
get_attn_subsequence_mask
def get_attn_subsequence_mask(seq): ''' seq: [batch_size, tgt_len] ''' attn_shape = [seq.size(0), seq.size(1), seq.size(1)] # Upper triangular matrix subsequence_mask = np.triu(np.ones(attn_shape), k=1) subsequence_mask = torch.from_numpy(subsequence_mask).byte() return subsequence_mask # [batch_size, tgt_len, tgt_len]
How will Attention Mask be Used
In get_attn_pad_mask, seq_q means a sequence of indexes, i.e, , which is to be embedded into and form queries , the same is true for seq_k and , they will be multiplied together to get
for scaled dot-product attention.
On Padding Logic
Note that our padding logic just depends on seq_k and pad (see line 12), seq_q is only used to expand the number of rows to match the dimension of (see line 14) in order to apply the mask.
Our mask will be applied right before applying softmax, i.e., we eventually get scores in rows.
Denote the dimension in attention module, where
We get the scores (the attention) by soft-maxing along the last dimension:
The matrix can be decomposed as for some and , where with being the number of paddings counted from the end of the sentence. Our attention will be the linear span of values (the rows) in :
The last few rows of ( for ) has no contribution to the context.
Note that in each flow of computation we are focusing on one sentence with multiple indexes. The last few 's are value from the padding position that we are not concerned about.
Encoder Layer and Encoder
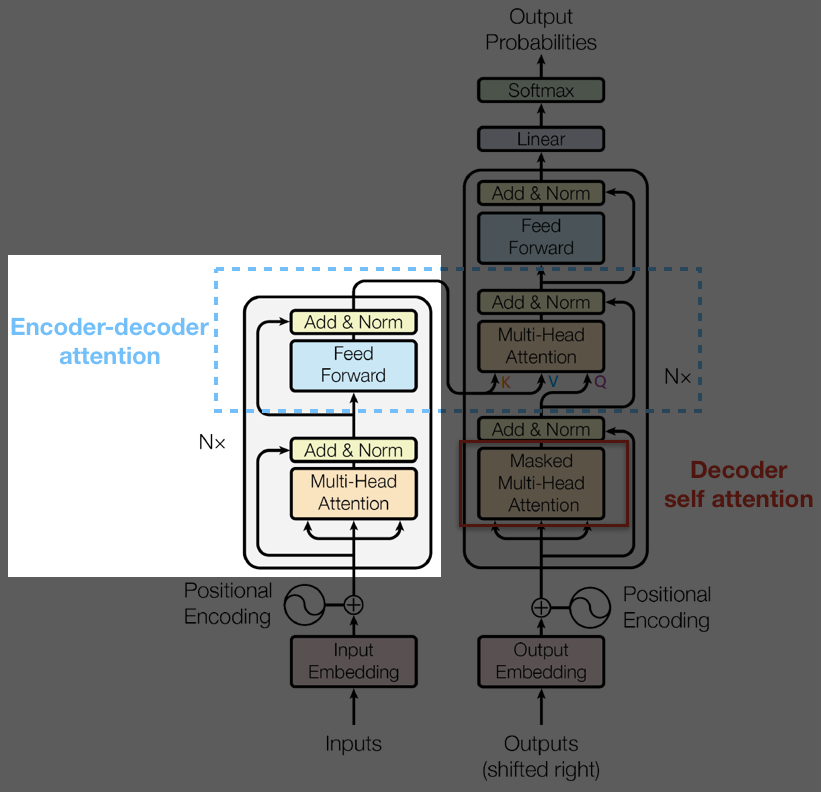
In transformer an Encoder is a iteration of several EncoderLayer:
EncoderLayer
class EncoderLayer(nn.Module): def __init__(self): super(EncoderLayer, self).__init__() self.enc_self_attn = MultiHeadAttention() self.pos_ffn = PoswiseFeedForwardNet() def forward(self, enc_inputs, enc_self_attn_mask): ''' enc_inputs: [batch_size, src_len, d_model] enc_self_attn_mask: [batch_size, src_len, src_len] ''' # enc_outputs: [batch_size, src_len, d_model], # attn: [batch_size, n_heads, src_len, src_len] enc_outputs, attn = self.enc_self_attn( # enc_inputs to same Q,K,V enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask ) # enc_outputs: [batch_size, src_len, d_model] enc_outputs = self.pos_ffn(enc_outputs) return enc_outputs, attn
Here the enc_self_attn_mask is usually just a mask that masks out the value contributed from padding (prevent the value from padding from joining the calculation).
Encoder
class Encoder(nn.Module): def __init__(self): super(Encoder, self).__init__() self.src_emb = nn.Embedding(src_vocab_size, d_model) self.pos_emb = PositionalEncoding(d_model) self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)]) def forward(self, enc_inputs): ''' enc_inputs: [batch_size, src_len] ''' # [batch_size, src_len, d_model]: enc_outputs = self.src_emb(enc_inputs) # [batch_size, src_len, d_model]: enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, src_len, src_len]: enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) enc_self_attns = [] for layer in self.layers: # enc_outputs: [batch_size, src_len, d_model], # enc_self_attn: [batch_size, n_heads, src_len, src_len] enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask) enc_self_attns.append(enc_self_attn) # enc_self_attns is only for graph-plotting purpose: return enc_outputs, enc_self_attns
Decoder Layer and Decoder
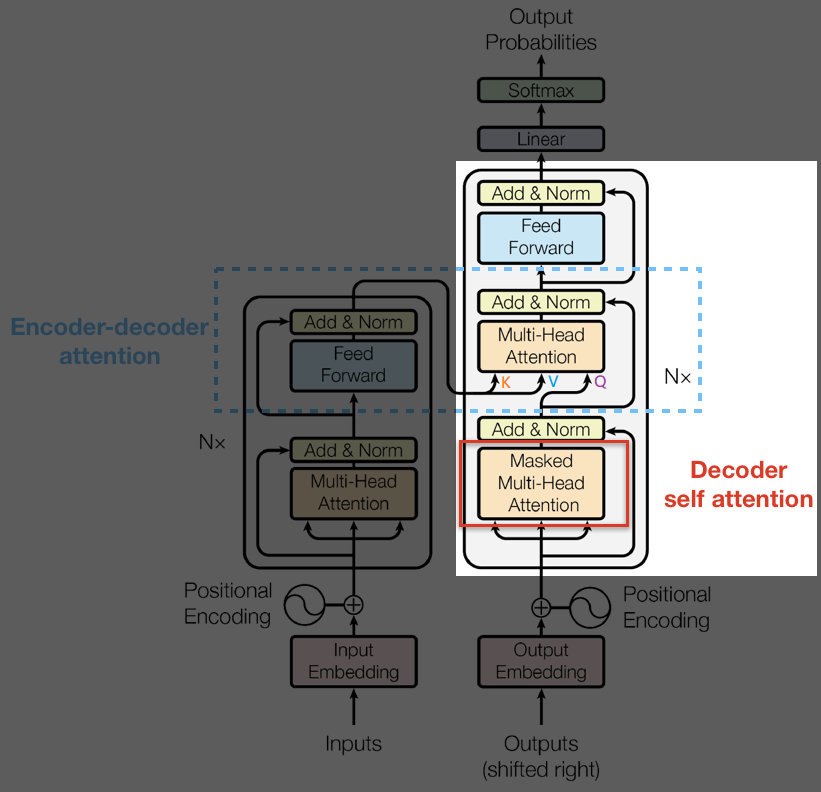
DecoderLayer
class DecoderLayer(nn.Module): def __init__(self): super(DecoderLayer, self).__init__() self.dec_self_attn = MultiHeadAttention() self.dec_enc_attn = MultiHeadAttention() self.pos_ffn = PoswiseFeedForwardNet() def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask): ''' dec_inputs: [batch_size, tgt_len, d_model] enc_outputs: [batch_size, src_len, d_model] dec_self_attn_mask: [batch_size, tgt_len, tgt_len] dec_enc_attn_mask: [batch_size, tgt_len, src_len] ''' # dec_outputs: [batch_size, tgt_len, d_model], # dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len] dec_outputs, dec_self_attn = self.dec_self_attn( dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask ) # dec_outputs: [batch_size, tgt_len, d_model], # dec_enc_attn: [batch_size, h_heads, tgt_len, src_len] dec_outputs, dec_enc_attn = self.dec_enc_attn( dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask ) # [batch_size, tgt_len, d_model] dec_outputs = self.pos_ffn(dec_outputs) return dec_outputs, dec_self_attn, dec_enc_attn
Decoder
1class Decoder(nn.Module): 2 def __init__(self): 3 super(Decoder, self).__init__() 4 self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model) 5 self.pos_emb = PositionalEncoding(d_model) 6 self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) 7 8 def forward(self, dec_inputs, enc_inputs, enc_outputs): 9 ''' 10 dec_inputs: [batch_size, tgt_len] 11 enc_intpus: [batch_size, src_len] 12 enc_outputs: [batch_size, src_len, d_model] 13 ''' 14 15 # [batch_size, tgt_len, d_model]: 16 dec_outputs = self.tgt_emb(dec_inputs) 17 # [batch_size, tgt_len, d_model]: 18 dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1))\ 19 .transpose(0, 1)\ 20 .to(device) 21 22 # [batch_size, tgt_len, tgt_len]: 23 dec_self_attn_pad_mask = get_attn_pad_mask( 24 dec_inputs, 25 dec_inputs 26 ).to(device) 27 28 # [batch_size, tgt_len, tgt_len]: 29 dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).to(device) 30 # [batch_size, tgt_len, tgt_len]: 31 dec_self_attn_mask = torch.gt( 32 (dec_self_attn_pad_mask + dec_self_attn_subsequence_mask), 33 0 34 ).to(device) 35 36 # [batc_size, tgt_len, src_len]: 37 dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) 38 39 dec_self_attns, dec_enc_attns = [], [] 40 for layer in self.layers: 41 # dec_outputs: [batch_size, tgt_len, d_model], 42 # dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], 43 # dec_enc_attn: [batch_size, h_heads, tgt_len, src_len] 44 dec_outputs, dec_self_attn, dec_enc_attn = layer( 45 dec_outputs, 46 enc_outputs, 47 dec_self_attn_mask, 48 dec_enc_attn_mask 49 ) 50 dec_self_attns.append(dec_self_attn) 51 dec_enc_attns.append(dec_enc_attn) 52 return dec_outputs, dec_self_attns, dec_enc_attns
Why Feed enc_inputs into Decoder?
-
From the structural graph of transformer it may seem weird to also feed
enc_inputsinto theDecoder. -
In fact,
enc_inputsis only used in the creation of padding mask (see line 37 of theDecodercode block) which help ignore the last few rows of the context value matrix in theenc_outputs(think of it as another form of embedding from the original sequence of word indexes).
The Transformer
class Transformer(nn.Module): def __init__(self): super(Transformer, self).__init__() self.encoder = Encoder().to(device) self.decoder = Decoder().to(device) self.projection = nn.Linear( d_model, tgt_vocab_size, bias=False ).to(device) def forward(self, enc_inputs, dec_inputs): ''' enc_inputs: [batch_size, src_len] dec_inputs: [batch_size, tgt_len] ''' # tensor to store decoder outputs # outputs = torch.zeros(batch_size, tgt_len, tgt_vocab_size).to(self.device) # enc_outputs: [batch_size, src_len, d_model] # enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len] enc_outputs, enc_self_attns = self.encoder(enc_inputs) # dec_outpus: [batch_size, tgt_len, d_model] # dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len] # dec_enc_attn: [n_layers, batch_size, tgt_len, src_len] dec_outputs, dec_self_attns, dec_enc_attns = self.decoder( dec_inputs, enc_inputs, enc_outputs ) # dec_logits: [batch_size, tgt_len, tgt_vocab_size] dec_logits = self.projection(dec_outputs) return ( dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns )
- Note that
dec_logitswill be of shape[batch_size, tgt_max_len, tgt_vocab_size]. dec_logits.view(-1, dec_logits.size(-1))will be of shape[batch_size*tgt_max_len, tgt_vocab_size]
Training: Naive Dataset
Dataset and data_loader
Let's get a rough feeling from a naive dataset:
sentences = [ # enc_input dec_input dec_output ['ich mochte ein bier <P>', '<sos> i want a beer .', 'i want a beer . <eos>'], ['ich mochte ein cola <P>', '<sos> i want a coke .', 'i want a coke . <eos>'] ]
It is not necessary to write <P> in the dataset, we can pad our sequence of word indexes by 0's in our dataset pipeline.
Next we define our data_loader:
src_word_index = {'<P>': 0, 'ich': 1, 'mochte': 2, 'ein': 3, 'bier': 4, 'cola': 5} src_vocab_size = len(src_word_index) tgt_word_index = {'<P>': 0, 'i': 1, 'want': 2, 'a': 3, 'beer': 4, 'coke': 5, '<sos>': 6, '<eos>': 7, '.': 8} src_index_word = {i: w for i, w in enumerate(src_word_index)} tgt_index_word = {i: w for i, w in enumerate(tgt_word_index)} tgt_vocab_size = len(tgt_word_index) src_len = 5 # enc_input max sequence length tgt_len = 6 # dec_input(=dec_output) max sequence length def make_data(sentences): enc_inputs, dec_inputs, dec_outputs = [], [], [] for i in range(len(sentences)): enc_input_, dec_input_, dec_output_ = sentences[i] enc_input = [src_word_index[n] for n in enc_input_.split()] # ^^^^ [[1, 2, 3, 4, 0], [1, 2, 3, 5, 0]] dec_input = [tgt_word_index[n] for n in dec_input_.split()] # ^^^^ [[6, 1, 2, 3, 4, 8], [6, 1, 2, 3, 5, 8]] dec_output = [tgt_word_index[n] for n in dec_output_.split()] # ^^^^ [[1, 2, 3, 4, 8, 7], [1, 2, 3, 5, 8, 7]] enc_inputs.append(enc_input) dec_inputs.append(dec_input) dec_outputs.append(dec_output) return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs) class MyDataSet(Data.Dataset): def __init__(self): super(MyDataSet, self).__init__() enc_inputs, dec_inputs, dec_outputs = make_data(sentences) self.enc_inputs = enc_inputs self.dec_inputs = dec_inputs self.dec_outputs = dec_outputs def __len__(self): return self.enc_inputs.shape[0] def __getitem__(self, idx): return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx] data_loader = Data.DataLoader(MyDataSet(), batch_size=2, shuffle=True)
Train to see if the Model can Overfit
def train(): transformer = Transformer().to(device) criterion = nn.CrossEntropyLoss(ignore_index=0) optimizer = optim.SGD(transformer.parameters(), lr=1e-3, momentum=0.99) epochs = 30 for epoch in range(epochs): for enc_inputs, dec_inputs, dec_outputs in data_loader: ''' enc_inputs: [batch_size, src_len] dec_inputs: [batch_size, tgt_len] dec_outputs: [batch_size, tgt_len] ''' enc_inputs = enc_inputs.to(device) dec_inputs = dec_inputs.to(device) dec_outputs = dec_outputs.to(device) outputs, enc_self_attns, dec_self_attns, dec_enc_attns = transformer( enc_inputs, dec_inputs ) loss = criterion(outputs, dec_outputs.view(-1)) print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss)) optimizer.zero_grad() loss.backward() optimizer.step() state_dict = transformer.state_dict() torch.save(state_dict, os.path.join("pths", f"model_epoch_{epochs}.pth"))
Upon executing the training script, our model can indeed overfit the naive dataset:
Epoch: 0001 loss = 2.579853 Epoch: 0002 loss = 2.416333 Epoch: 0003 loss = 2.135146 Epoch: 0004 loss = 1.839263 Epoch: 0005 loss = 1.538042 Epoch: 0006 loss = 1.303803 Epoch: 0007 loss = 1.134294 Epoch: 0008 loss = 0.898169 Epoch: 0009 loss = 0.751822 Epoch: 0010 loss = 0.609819 Epoch: 0011 loss = 0.477917 Epoch: 0012 loss = 0.374170 Epoch: 0013 loss = 0.280897 Epoch: 0014 loss = 0.225249 Epoch: 0015 loss = 0.175177 Epoch: 0016 loss = 0.143766 Epoch: 0017 loss = 0.139490 Epoch: 0018 loss = 0.114785 Epoch: 0019 loss = 0.090137 Epoch: 0020 loss = 0.087496 Epoch: 0021 loss = 0.076527 Epoch: 0022 loss = 0.069732 Epoch: 0023 loss = 0.061058 Epoch: 0024 loss = 0.055305 Epoch: 0025 loss = 0.042023 Epoch: 0026 loss = 0.040661 Epoch: 0027 loss = 0.039919 Epoch: 0028 loss = 0.023459 Epoch: 0029 loss = 0.022219 Epoch: 0030 loss = 0.027067
Define Translator
We predict the target result word by word as in the teacher forcing approach in our training process.
class Translator(): def __init__(self, transformer: Transformer): self.transformer = transformer def translate(self, enc_input, start_index): dec_input = torch.zeros(1, 0).type_as(enc_input) terminated = False next_tgt_word_index = start_index while not terminated: dec_input = torch.cat( [ dec_input.detach(), torch.tensor([[next_tgt_word_index]],dtype=enc_input.dtype).to(device) ], -1 ) dec_output_logits, _, _, _= self.transformer(enc_input, dec_input) next_tgt_word_index = torch.argmax(dec_output_logits[-1]) if next_tgt_word_index == tgt_word_index["."]: terminated = True print("next_word", tgt_index_word[next_tgt_word_index.item()]) # remove batch, remove <sos> return dec_input.squeeze(0)[1:]
Translation Script
Now we test our function by using the script:
transformer = Transformer().to(device) model_path = "pths/model_epoch_30.pth" if model_path is not None: transformer.load_state_dict(torch.load(model_path)) translator = Translator(transformer) enc_inputs, _, _ = next(iter(data_loader)) enc_inputs = enc_inputs.to(device) # e.g. enc_inputs = tensor([ # [1, 2, 3, 4, 0], [1, 2, 3, 5, 0] # ], device='cuda:0') for i in range(len(enc_inputs)): enc_input = enc_inputs[i] sentence = " ".join([src_index_word[i.item()] for i in enc_input]) print("source sentence:", sentence) predict = translator.translate( enc_input.unsqueeze(0), # expand as batch start_index=tgt_word_index["<sos>"] ) print(enc_input, '->', [tgt_index_word[n.item()] for n in predict.squeeze()])
yields
source sentence: ich mochte ein bier <P> next_word i next_word want next_word a next_word beer next_word . tensor([1, 2, 3, 4, 0], device='cuda:0') -> ['i', 'want', 'a', 'beer'] source sentence: ich mochte ein cola <P> next_word i next_word want next_word a next_word coke next_word . tensor([1, 2, 3, 5, 0], device='cuda:0') -> ['i', 'want', 'a', 'coke']