Callbacks
Both callbacks below accept a startAt and step as keyword arguments. I will adjust when I start to adjust the training process (step=2 when I adjust the learning the first time, startAt will be the epoch that I want to base on).
EpochCheckpoint
This is to save the model on every end of epoch (modulo some constant, say 5).
from tensorflow.keras.callbacks import Callback class EpochCheckpoint(Callback): def __init__(self, output_dir, step=1 , every=1, startAt=0, model_title="prediction-model"): super(Callback, self).__init__() self.step = step self.output_dir = output_dir self.every = every self.intEpoch = startAt self.model_title = model_title def on_epoch_end(self, epoch, logs={}): if (self.intEpoch + 1) % self.every == 0: p = os.path.sep.join([self.output_dir, self.model_title + "epoch-{}-{}.hdf5".format(self.step, self.intEpoch + 1)]) self.model.save(p, overwrite=True) self.intEpoch += 1
TrainingMonitorCallback
tensorboard would be more helpful, but one cannot use tensorboard if the training process is held in colab. For me I would generalize the approach by using this monitor callback.
Two functionalities for this callback:
- In this callback we will save a figure for each epoch to track how
acc,val_acc,lossandval_lossdiffers whenepochincreases. - A complete log of this values will be stored in a
jsonfile stored injsonPath.
from tensorflow.keras.callbacks import BaseLogger import matplotlib.pyplot as plt import numpy as np import json import os import tensorflow.keras.backend as K class TrainingMonitorCallback(BaseLogger): def __init__(self, fig_dir, step=1, jsonPath=None, startAt=0): super(TrainingMonitorCallback, self).__init__() self.fig_dir = fig_dir self.jsonPath = jsonPath self.startAt = startAt self.step=step def on_train_begin(self, logs={}): self.H = {} if self.jsonPath is not None: if os.path.exists(self.jsonPath): self.H = json.loads(open(self.jsonPath).read()) if self.startAt > 0: for k in self.H.keys(): self.H[k] = self.H[k][:self.startAt] def on_epoch_end(self, epoch, logs={}): print("[INFO] learning rate: {}".format(K.get_value(self.model.optimizer.lr))) for (k, v) in logs.items(): l = self.H.get(k, []) l.append(float(v)) self.H[k] = l if self.jsonPath is not None: f = open(self.jsonPath, "w") f.write(json.dumps(self.H, indent=4)) f.close() if len(self.H["loss"]) > 0: epoch = len(self.H["loss"]) N = np.arange(0, len(self.H["loss"])) plt.style.use("ggplot") plt.figure() _, ax1 = plt.subplots() l1, = ax1.plot(N, self.H["loss"], label="train_loss", color="olive") l2, = ax1.plot(N, self.H["val_loss"], label="val_loss", color="red") ax2 = ax1.twinx() l3, = ax2.plot(N, self.H["accuracy"], label="train_acc", color="royalblue") l4, = ax2.plot(N, self.H["val_accuracy"], label="val_acc", color="midnightblue") plt.title("Training Loss and Accuracy [Epoch {}]".format(len(self.H["loss"]))) plt.xlabel("Epoch #") plt.ylabel("Loss/Accuracy") plt.legend([l1,l2,l3,l4], ["train_loss", "val_loss", "train_acc", "val_acc"], loc='lower left') # save the figure plt.savefig(f"{self.fig_dir}/epoch-{self.step}-{epoch}.png") plt.close()
Usage
We define
callbacks = [ EpochCheckpoint(output_dir="./checkpoints"), TrainingMonitorCallback( fig_dir="./checkpoints-figure", jsonPath="./checkpoints-json/loss.json" ) ]
and plug it in the model.fit's keyward argument, callbacks.
For example:
model.fit( train_dataset, steps_per_epoch=len(train_dataset), epochs=50, validation_data=val_dataset, validation_steps=len(val_dataset), callbacks=callbacks )
Result on every end of epoches:
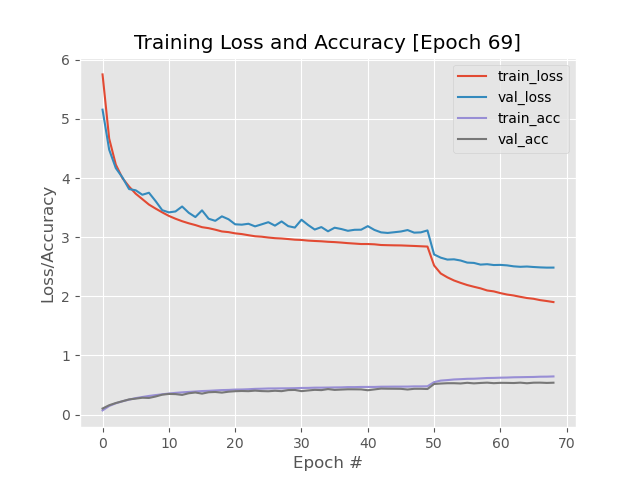
Restart Training Based on Past Epoch
When monitoring our training process, at some point the loss and val_loss will diverge or both do not decrease. Then we can interrupt the process by control + c.
We load our model/model_weight using a specific path (that is stored by using our checkpoint callback). We also adjust the learning rate when we find our training becomes stagnant.
Both mentioned callbacks accept step and startAt as their kwargs in the constructor. For example, my prev_model_path below means (manual adjustment) step=3 and epoch=35 accumulatively (this is the total number of epoches in the training, never reset to 0 for new step).
So when our next epoch is completed, the new saved model will be 4-36.hdf5.
from tensorflow.keras.models import load_model prev_model_path = "./checkpoints/prediction-modelepoch-3-35.hdf5" start_at_epoch = 35 new_lr = 1e-4 step = 4 model = load_model(prev_model_path) print("[INFO] step: {}, start at epoch: {}".format(step, start_at_epoch)) print("[INFO] old learning rate: {}".format(K.get_value(model.optimizer.lr))) K.set_value(model.optimizer.lr, new_lr) print("[INFO] new learning rate: {}".format(K.get_value(model.optimizer.lr))) callbacks = [ EpochCheckpoint(output_dir="./checkpoints", step=step, startAt=start_at_epoch), TrainingMonitorCallback( fig_dir="./checkpoints-figure", jsonPath="./checkpoints-json/loss.json", startAt=start_at_epoch, step=step ) ] model.fit( train_dataset, steps_per_epoch=len(train_dataset), epochs=50, validation_data=val_dataset, validation_steps=len(val_dataset), callbacks=callbacks )