The Entire GAN and DCGAN Script
Simple GAN
import torch import torch.nn as nn import torch.optim as optim import torchvision import torchvision.datasets as datasets import torchvision.transforms as transforms from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter class Discriminator (nn.Module): def __init__(self, img_dim): super().__init__() self.disc = nn.Sequential( nn.Linear(img_dim, 128), nn.LeakyReLU(0.1), nn.Linear(128, 1), nn.Sigmoid() ) def forward(self, x): return self.disc(x) class Generator(nn.Module): def __init__(self, z_dim, img_dim): super().__init__() self.gen = nn.Sequential( nn.Linear(z_dim, 256), nn.LeakyReLU(0.1), nn.Linear(256, img_dim), nn.Tanh() ) def forward(self, x): return self.gen(x) device = "cuda" if torch.cuda.is_available() else "cpu" lr = 3e-4 z_dim = 64 img_dim = 28*28*1 batch_size = 32 num_epochs = 50 disc = Discriminator(img_dim).to(device) gen = Generator(z_dim, img_dim).to(device) fixed_noise = torch.randn(batch_size, z_dim).to(device) transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize( (0.5,), (0.5,) ) ]) dataset = datasets.MNIST( root="./dataset/", transform=transform, download=True ) loader= DataLoader(dataset, batch_size, shuffle=True) opt_disc = optim.Adam(disc.parameters(), lr=lr) opt_gen= optim.Adam(gen.parameters(), lr=lr) criterion = nn.BCELoss() writer_fake = SummaryWriter(f"./runs/GAN_MNIST/fake") writer_real = SummaryWriter(f"./runs/GAN_MNIST/real") step = 0 for epoch in range(num_epochs): for batch_idx, (real, _) in enumerate(loader): real = real.view(-1, 784).to(device) batch_size = real.shape[0] noise = torch.randn(batch_size, z_dim).to(device) fake = gen(noise) disc_real = disc(real).view(-1) lossD_real = criterion(disc_real, torch.ones_like(disc_real)) # don't want opt_disc.step() update fake, so create a detached version fake at this point # also the gradient that is used to update disc has nothing to do with gen # as the graph of fake involve gen, we have to detach fake to avoid affecting gen itself disc_fake = disc(fake.detach()).view(-1) lossD_fake = criterion(disc_fake, torch.zeros_like(disc_fake)) lossD = (lossD_real + lossD_fake)/2 disc.zero_grad() lossD.backward() opt_disc.step() output = disc(fake).view(-1) lossG = criterion(output, torch.ones_like(output)) gen.zero_grad() lossG.backward() opt_gen.step() if batch_idx == 0: print( f"Epoch [{epoch}/{num_epochs}] Batch {batch_idx}/{len(loader)} \ Loss D: {lossD:.4f}, loss G: {lossG:.4f}" ) with torch.no_grad(): fake = gen(fixed_noise).reshape(-1, 1, 28, 28) data = real.reshape(-1, 1, 28, 28) img_grid_fake = torchvision.utils.make_grid(fake, normalize=True) img_grid_real = torchvision.utils.make_grid(data, normalize=True) writer_fake.add_image( "Mnist Fake Images", img_grid_fake, global_step=step ) writer_real.add_image( "Mnist Real Images", img_grid_real, global_step=step ) step += 1
DCGAN
import torch import torch.nn as nn import torch.optim as optim import torchvision import torchvision.datasets as datasets import torchvision.transforms as transforms from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter class Discriminator(nn.Module): def __init__(self, channels_img, features_d): super(Discriminator, self).__init__() #Input: N x img_channels x 64 x 64 self.disc = nn.Sequential( nn.Conv2d(channels_img, features_d, kernel_size=4, stride=2, padding=1), # 32 x 32 nn.LeakyReLU(0.2), self._block(features_d, features_d*2, 4, 2, 1), # 16x16 self._block(features_d*2, features_d*4, 4, 2, 1), # 8x8 self._block(features_d*4, features_d*8, 4, 2, 1), # 4x4 nn.Conv2d(features_d * 8, 1, kernel_size=4, stride=2, padding=0), # 1x1 nn.Sigmoid() ) def _block(self, in_channels, out_channels, kernel_size, stride, padding): return nn.Sequential( nn.Conv2d( in_channels, out_channels, kernel_size, stride, padding, bias=False ), nn.BatchNorm2d(out_channels), nn.LeakyReLU(0.2) ) def forward(self, x): return self.disc(x) class Generator(nn.Module): def __init__(self, z_dim, channels_img, features_g): super(Generator, self).__init__() # Input: N x z_dim x 1 x 1 self.gen = nn.Sequential( self._block(z_dim, features_g*16, 4, 1, 0), # N x f_g*16 x 4 x 4 self._block(features_g*16, features_g * 8, 4, 2, 1), # 8 x 8 self._block(features_g*8, features_g * 4, 4, 2, 1), # 16 x 16 self._block(features_g*4, features_g * 2, 4, 2, 1), # 32 x 32 nn.ConvTranspose2d( features_g*2, channels_img, 4,2,1 ), # 64 x 64 nn.Tanh() ) def _block(self, in_channels, out_channels, kernel_size, stride, padding): return nn.Sequential( nn.ConvTranspose2d( in_channels, out_channels, kernel_size, stride, padding, bias=False ), nn.BatchNorm2d(out_channels), nn.ReLU() ) def forward(self, x): return self.gen(x) def initialize_weights(model): for m in model.modules(): if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.BatchNorm2d)): nn.init.normal_(m.weight.data, 0.0, 0.02) device = torch.device("cuda") if torch.cuda.is_available() else "cpu" LEARNING_RATE=2e-4 BATCH_SIZE = 128 IMAGE_SIZE = 64 CHANNELS_IMG = 1 Z_DIM = 100 NUM_EPOCHS = 5 FEATURES_DISC = 64 FEATURES_GEN = 64 transform = transforms.Compose( [ transforms.Resize(IMAGE_SIZE), transforms.ToTensor(), transforms.Normalize( [0.5 for _ in range(CHANNELS_IMG)], [0.5 for _ in range(CHANNELS_IMG)] ) ] ) dataset=datasets.MNIST( root="./dataset/", train=True, transform=transform, download=True ) loader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True) gen = Generator(Z_DIM, CHANNELS_IMG, FEATURES_GEN).to(device) disc = Discriminator(CHANNELS_IMG, FEATURES_DISC).to(device) initialize_weights(gen) initialize_weights(disc) opt_gen = optim.Adam(gen.parameters(), lr=LEARNING_RATE, betas=(0.5,0.999)) opt_disc = optim.Adam(disc.parameters(), lr=LEARNING_RATE, betas=(0.5,0.999)) criterion = nn.BCELoss() fixed_noise = torch.randn(32, Z_DIM, 1, 1).to(device) writer_real = SummaryWriter(f"./logs/real") writer_fake = SummaryWriter(f"./logs/fake") step = 0 gen.train() disc.train() for epoch in range(NUM_EPOCHS): for batch_idx, (real, _) in enumerate(loader): real = real.to(device) noise = torch.randn((BATCH_SIZE, Z_DIM, 1, 1)).to(device) fake = gen(noise) disc_real = disc(real).reshape(-1) disc_fake = disc(fake.detach()).reshape(-1) loss_disc_real = criterion(disc_real, torch.ones_like(disc_real)) loss_disc_fake = criterion(disc_fake, torch.zeros_like(disc_fake)) loss_disc = (loss_disc_fake + loss_disc_real)/2 disc.zero_grad() loss_disc.backward() opt_disc.step() output = disc(fake).reshape(-1) loss_gen = criterion(output, torch.ones_like(output)) gen.zero_grad() loss_gen.backward() opt_gen.step() if batch_idx % 100 == 0: print( f"Epoch [{epoch}/{NUM_EPOCHS}] Batch {batch_idx}/{len(loader)} \ Loss D: {loss_disc:.4f}, loss G: {loss_gen:.4f}" ) with torch.no_grad(): fake = gen(fixed_noise) img_grid_fake = torchvision.utils.make_grid(fake[:32], normalize=True) img_grid_real = torchvision.utils.make_grid(real[:32], normalize=True) writer_fake.add_image( "Mnist Fake Images", img_grid_fake, global_step=step ) writer_real.add_image( "Mnist Real Images", img_grid_real, global_step=step ) step += 1
What Happens in the Train Loop
fake.detach()
In the train loop of our simple GAN:
1disc = Discriminator(img_dim).to(device) 2gen = Generator(z_dim, img_dim).to(device) 3 4opt_disc = optim.Adam(disc.parameters(), lr=lr) 5opt_gen = optim.Adam(gen.parameters(), lr=lr) 6 7criterion = nn.BCELoss() 8 9for epoch in range(num_epoch): 10 for batch_index, (real, _) in enumerate(loader): 11 real = real.reivew(-1, 784).to(device) 12 batch_size = real.shape[0] 13 14 noise = torch.randn(batch_size, z_dim).to(device) 15 fake = gen(noise) 16 17 disc_real = disc(real).view(-1) 18 lossD_real = criterion(disc_real, torch.ones_like(disc_real)) 19 20 disc_fake = disc(fake.detach()).view(-1) 21 lossD_fake = criterion(disc_fake, torch.zeros_like(disc_fake)) 22 23 lossD = (lossD_real + lossD_fake)/2
-
Note that we have used
fake.detach()here. After detaching our parameter/tensorfakewill not have.gradandrequires_grad=False. Also note thatfake.detach()is a new variable, it will not mutatefake. -
The main reason for
detach()is that whenopt_disc.step()get executed, it will update every parameter in the graph for whichrequires_grad=True. Asfakeis going to be reused, plus the gradient that is used to updatedischas nothing to do withgen, we therefore create a detached version offakeat this point to avoid affectinggenitself.
disc.zero_grad(), lossD.backward(), opt_disc.step()
And we want to discuss the following 3 lines:
24 disc.zero_grad() 25 lossD.backward() 26 opt_disc.step()
-
disc.zero_grad(): It sets the.gradof alldisc.parameters()to0. -
lossD.backward(): whenbackward()is executed, every tensor (variable/parameter) that is involved in the calculation oflossDwill be assigned a computed derivative. SincelossDis at the top of the computation graph,lossD.gradwill beNone.What's more,
lossD_real.gradandlossD_fake.gradare the derivativesrespectively. Similarly for a parameter/tensor,
param_1, involved inlossD_realwill have an assigned valueparam_1.gradwhich is and so on and so forth. -
opt_disc.step(): When this line is executed, the parameters'.gradattribute will be used to update the parameter indisc.Recall that since
opt_disc = optim.Adam(disc.parameters(), lr=lr),opt_discpossses the references to those parameters.
Stackoverflow's Comments on module.zero_grad(), loss.backward() and optimizer.step()
-
Post 1 is a numerical explanation of the what're happening in
.backward()and.step().details
Some answers explained well, but I'd like to give a specific example to explain the mechanism.
Suppose we have a function . The updating gradient formula of w.r.t and is:
Initial values are and .
x = torch.tensor([1.0], requires_grad=True) y = torch.tensor([2.0], requires_grad=True) z = 3*x**2+y**3 print("x.grad: ", x.grad) print("y.grad: ", y.grad) print("z.grad: ", z.grad) # print result should be: x.grad: None y.grad: None z.grad: NoneThen calculating the gradient of and in current value (, )
# calculate the gradient z.backward() print("x.grad: ", x.grad) print("y.grad: ", y.grad) print("z.grad: ", z.grad) # print result should be: x.grad: tensor([6.]) y.grad: tensor([12.]) z.grad: NoneFinally, using SGD optimizer to update the value of
xandyaccording the formula:# create an optimizer, pass x,y as the paramaters to be update, setting the learning rate lr=0.1 optimizer = optim.SGD([x, y], lr=0.1) # executing an update step optimizer.step() # print the updated values of x and y print("x:", x) print("y:", y) # print result should be: x: tensor([0.4000], requires_grad=True) y: tensor([0.8000], requires_grad=True)
-
Post 2 discusses how to avoid updating parameter by using
.detach().details
Let's say we defined a model:
model, and loss function:criterionand we have the following sequence of steps:pred = model(input) loss = criterion(pred, true_labels) loss.backward()predwill have angrad_fnattribute, that references a function that created it, and ties it back to the model. Therefore,loss.backward()will have information about the model it is working with.Try removing
grad_fnattribute, for example with:pred = pred.clone().detach()Then the model gradients will be
Noneand consequently weights will not get updated.And the optimizer is tied to the model because we pass
model.parameters()when we create the optimizer.
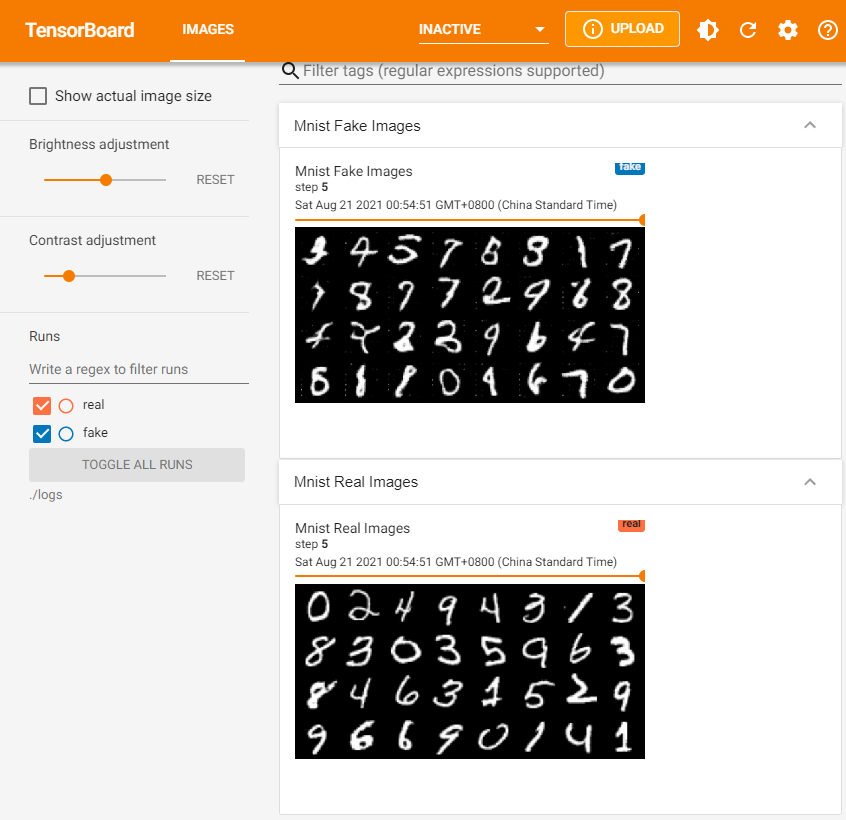
Tensorboard
Command to Look at logs Directory
tensorboard --logdir ./logs
Where do logs Come From?
We have imported SummaryWriter:
from torch.utils.tensorboard import SummaryWriter
We have also defined separate writers:
writer_real = SummaryWriter(f"./logs/real") writer_fake = SummaryWriter(f"./logs/fake")
We have run add_image method when batch_idx % 100 == 0:
for batch_idx, (real, _) in enumerate(loader): ... if batch_idx % 100 == 0: fake = gen(fixed_noise) with torch.no_grad(): img_grid_fake = torchvision.utils.make_grid(fake[:32], normalize=True) img_grid_real = torchvision.utils.make_grid(real[:32], normalize=True) writer_fake.add_image( "Mnist Fake Images", img_grid_fake, global_step=step ) writer_real.add_image( "Mnist Real Images", img_grid_real, global_step=step ) step += 1
Result:
Using 1.65 GB Celebrities Dataset of 202,599 Images
We can download the dataset from kaggle: https://www.kaggle.com/dataset/504743cb487a5aed565ce14238c6343b7d650ffd28c071f03f2fd9b25819e6c9
Now replace our MNIST dataset by:
# dataset=datasets.MNIST(root="./dataset/",train=True,transform=transform,download=True) dataset = datasets.ImageFolder(root="dataset/celeb_dataset/", transform=transform) loader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
and set CHANNELS_IMG = 3.