






1.Overview
Overview
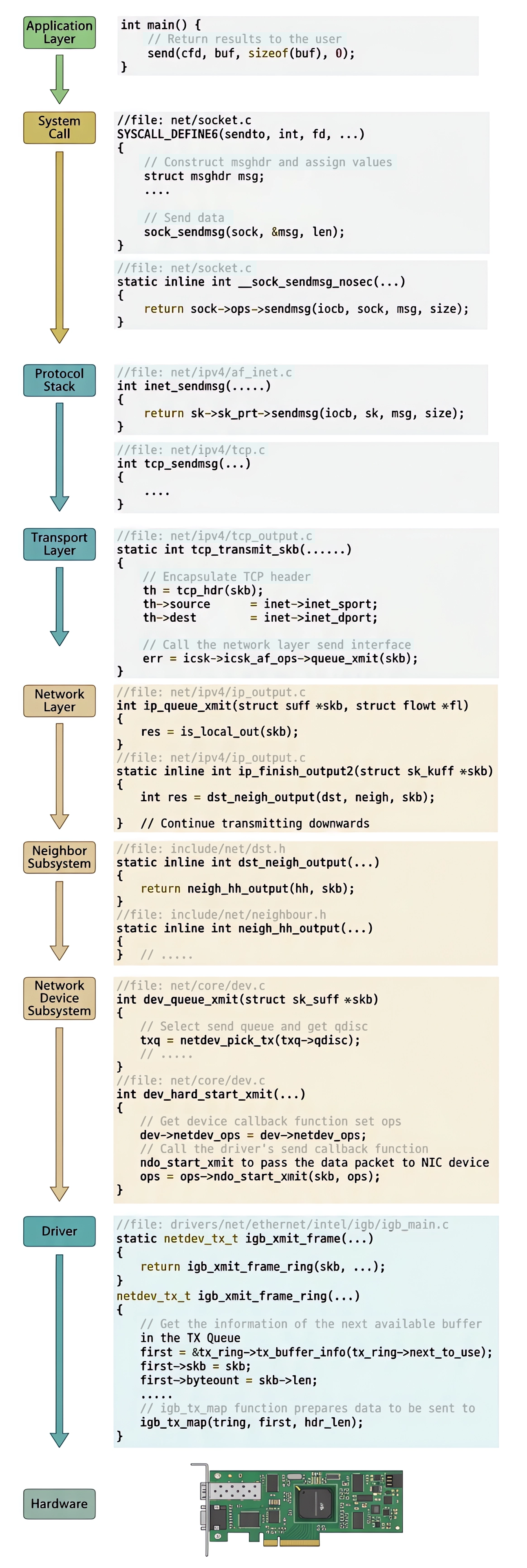
When a packet is sent from user space, it must traverse multiple layers of the Linux kernel before it actually reaches the network wire. In this article, we follow the journey of a packet from the moment user code calls send() all the way down to the NIC driver writing into the ring buffer and the DMA transfer completing.
The main stages are:
- NIC initialization — how ring buffers are allocated
- System call entry — from
send()to the protocol stack - Transport layer —
tcp_sendmsgandtcp_write_xmit - Network layer — IP header construction, routing, and fragmentation
- Neighbor subsystem — ARP resolution and MAC header preparation
- Network device subsystem — qdisc,
dev_hard_start_xmit - NIC driver — mapping
skbinto the DMA ring buffer and final transmission - Cleanup — releasing
skbmemory after the NIC confirms transmission
2.NIC Initialization and Ring Buffer Allocation
NIC Initialization and Ring Buffer Allocation
An NIC has both a receive queue and a transmit queue, and each queue is represented by a ring buffer. During NIC initialization, one critical task is setting up and allocating these ring buffers.
2.1.__igb_open
__igb_open
When NIC is opened, __igb_open is invoked:
-
netdev_priv(netdev)retrieves the private adapter structure associated with the network device. -
igb_setup_all_tx_resources- sets up all transmit ring buffers and;
- creates all receive ring buffers
-
Finally,
netif_tx_start_all_queues(...)starts all transmit queues so the system can begin sending packets. -
The hard-interrupt handler
igb_msix_ringis also registered inside__igb_open(we refer the reader to this link for more detail in Chinese).
igb_adapter is the driver's private data structure allocated immediately after the net_device struct in memory. It holds all Intel-specific hardware state for a single NIC instance. The key fields are:
-
net_deviceis the kernel's generic, protocol-agnostic view of any network interface. -
igb_adapteris the vendor-specific view of the same physical card. -
netdev_priv(...)simply returns the pointer to this private block, letting driver code go from the genericnetdevhandle to all the Intel-specific hardware details stored inadapter. -
adapter->tx_ring[i]is not itself the ring buffer — it is a pointer to anigb_ringstruct, which is the management struct for one transmit queue. The two parallel arrays inside it are the actual ring buffer:
The full ownership hierarchy is:
-
skblives intx_buffer_info[i].skb, not in the descriptor array. -
The descriptor array's job is to store the DMA-mapped addresses of those
skbdata buffers so the NIC can fetch the packet payload directly from RAM without CPU involvement. -
We discuss more on dma descriptor in section 〈2.4. DMA Descriptor〉.
2.2.igb_setup_all_tx_resources
igb_setup_all_tx_resources
igb_setup_all_tx_resources loops through each queue and calls igb_setup_tx_resources for each one:
2.3.igb_setup_tx_resources
igb_setup_tx_resources
Let's continue from the call chain inside of __igb_open. The actual ring buffer creation happens in igb_setup_tx_resources:
A ring buffer is not merely a circular array, it is actually two parallel arrays working together:
-
igb_tx_buffer[]— used by the kernel, allocated withvzalloc -
e1000_adv_tx_desc[]— used by the NIC hardware, allocated viadma_alloc_coherentso the hardware can access it directly through DMA
When a packet is eventually queued for transmission, entries at the same index in both arrays will refer to the same skb.
-
tx_ring->next_to_usetracks where the next packet will be placed, and -
tx_ring->next_to_cleantracks where cleanup should continue after transmission completes.
2.4.DMA Descriptor
DMA Descriptor
A DMA descriptor (e1000_adv_tx_desc) is a small, fixed-size hardware-facing struct that tells the NIC where a packet's data lives in RAM and how to transmit it — it does not contain the packet bytes itself:
The workflow when a packet is transmitted:
- CPU calls
dma_map_single()onskb->data, obtaining a physical DMA address. - CPU writes that address into
desc[i].buffer_addr, along with the length and flags. - CPU updates the NIC's tail register to signal "new descriptors are ready."
- NIC hardware reads
desc[i], fetches the packet bytes from RAM via DMA (no CPU involvement), and puts them on the wire. - NIC writes a completion status back into
olinfo_statusand raises a hard interrupt.
This is fundamentally different from a file descriptor (fd) in Linux — a file descriptor is merely an integer index (e.g. 0, 1, 3) into a per-process table that references an open file or socket in software.
A DMA descriptor is a hardware-level struct living in DMA-coherent memory that both the CPU and the NIC can access directly. They share the word "descriptor" only in the generic sense of "something that describes something else."
3.System Call: from send() to the Protocol Stack
System Call: from send() to the Protocol Stack
The user-space send() call can be found in net/socket.c. It is mapped to sys_sendto as follows:
sys_sendto is defined as:
sendto in the syscall layer is responsible for two things:
-
Find the socket in the kernel, and package the user's
buff,len,flags, etc. into astruct msghdr. -
It then invokes
sock_sendmsg→__sock_sendmsg→__sock_sendmsg_nosec. Inside__sock_sendmsg_nosec, we enter the protocol stack:
The call dispatches to inet_sendmsg through the socket's ops pointer.
4.Transport Layer: tcp_sendmsg
Transport Layer: tcp_sendmsg
4.1.inet_sendmsg (1st Clone of Data)
inet_sendmsg (1st Clone of Data)
In net/ipv4/af_inet.c, inet_sendmsg delegates to tcp_sendmsg via:
sk->sk_prot->sendmsg resolves to tcp_sendmsg.
tcp_sendmsg is quite lengthy. At its core it repeatedly pulls an skb from the tail of the socket's write queue. The helper for that is:
-
sk_write_queueis a doubly-linked list ofsk_buffobjects. -
tcp_write_queue_tailfetches the lastskbin that list so the kernel can append data to it before allocating a new one. -
More precisely, each
sk_buffcarries a data buffer with a reserved tail region. The key fields that track what space is left are:
The reader may wish to review struct socket thoroughly in How Socket Receive Data from NIC.
Now skb_availroom(skb) computes
i.e., how many bytes are still free at the tail of the current skb. If room is available, skb_add_data_nocache copies bytes from the user buffer directly into skb->tail and advances skb->tail by the number of bytes copied:
Only when skb_availroom(skb) == 0 (the current skb is full) does the kernel allocate a fresh skb via sk_stream_alloc_skb and append it to the write queue with skb_entail. This way the kernel packs as much data as possible into each skb before moving to the next, minimising the number of skb allocations and the overhead of per-segment headers.
4.2.tcp_sendmsg
tcp_sendmsg
Looking at the body of tcp_sendmsg (found in net/ipv4/tcp.c):
msg->msg_iov holds the user-space buffer being transmitted. The kernel allocates an skb, copies the user buffer into it — incurring one or more memory copies — and appends the skb to the write queue via skb_entail.
The kernel does not immediately transmit every skb it builds. The decision is made as follows (also in net/ipv4/tcp.c):
-
Transmission begins only when
forced_push(tp)returns true — meaning- The pending data exceeds half the maximum window or
- When the
skbis the first unsent segment at the head of the write queue.
-
If neither condition holds, the call chain simply accumulates data into the write queue without transmitting.
Regardless of which path triggers transmission, both __tcp_push_pending_frames and tcp_push_one ultimately call tcp_write_xmit (found in net/ipv4/tcp_output.c):
4.3.tcp_write_xmit (2nd Clone of Data, Shallow copy of skb)
tcp_write_xmit (2nd Clone of Data, Shallow copy of skb)
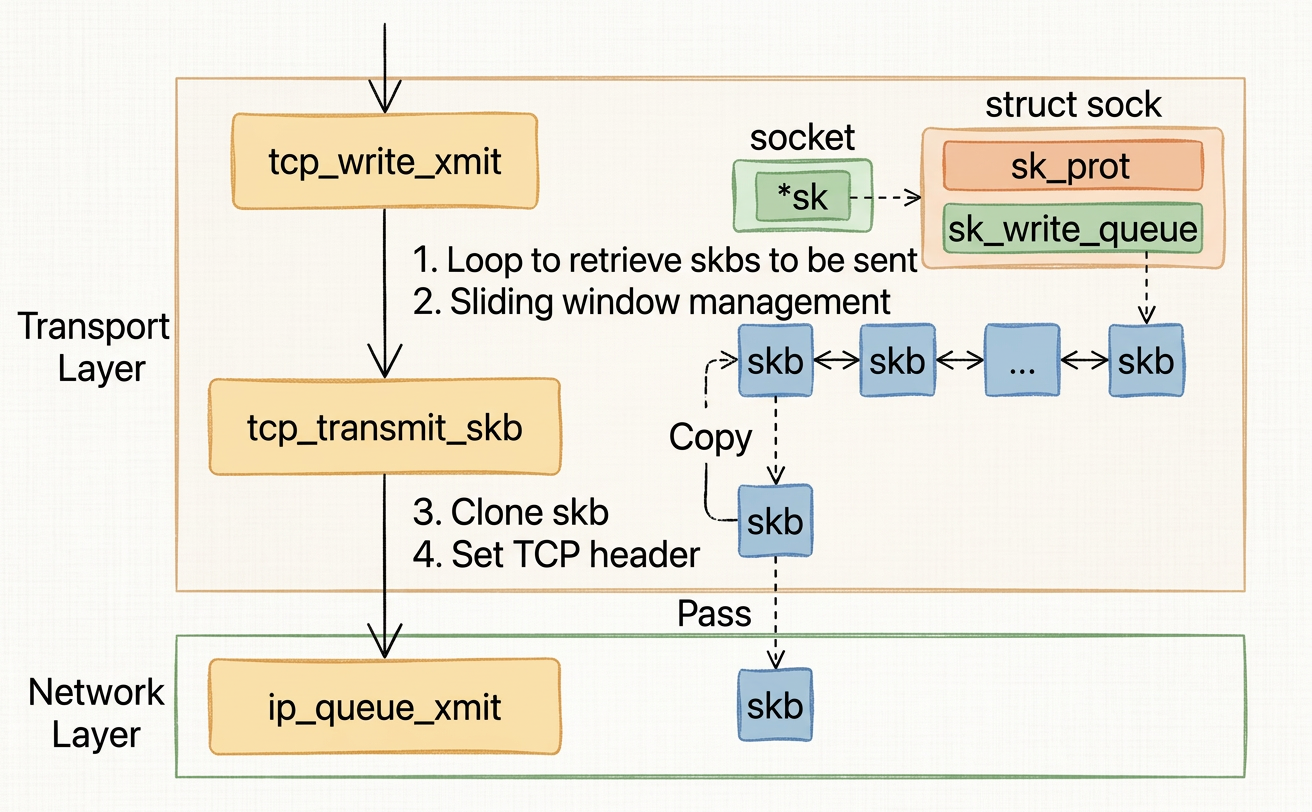
tcp_write_xmit pulls each pending skb from the head of the write queue, checks sliding window constraints (congestion window quota via tcp_cwnd_test and send window via tcp_snd_wnd_test), optionally splits or fragments the segment, and passes it to tcp_transmit_skb.
tcp_transmit_skb is the last step in the transport layer (also in net/ipv4/tcp_output.c):
-
The first thing
tcp_transmit_skbdoes is clone theskb.skb_cloneperforms a shallow copy — it allocates a newsk_buffheader struct but does not copy the underlying packet data buffer. Both the original and the clone point at the sameskb->datamemory, protected by a reference count (skb_shinfo(skb)->dataref). This is intentional and cheap: we only need a separate header so each copy can carry its own state (e.g. which layer has already processed it), while the actual bytes are shared. -
The original
skbmust remain insk_write_queuebecause TCP is a reliable protocol — if the remote peer does not acknowledge the segment within a timeout, the kernel needs to retransmit it. Because the data buffer is shared, the original still has access to the full packet payload for retransmission without any extra copy. -
The clone is what gets handed down to lower layers and eventually freed at the network device layer once the NIC confirms transmission. When the clone is freed, the reference count on the shared data buffer is decremented; the data is only truly released when the count reaches zero, which happens after the original
skbis also freed. -
The original
skbis only removed fromsk_write_queueonce the corresponding ACK is received at the transport layer.
After stamping the TCP header, the function dispatches to the network layer via
which eventually resolves to ip_queue_xmit in net/ipv4/tcp_ipv4.c.
5.Network Layer: IP Header and Routing
Network Layer: IP Header and Routing
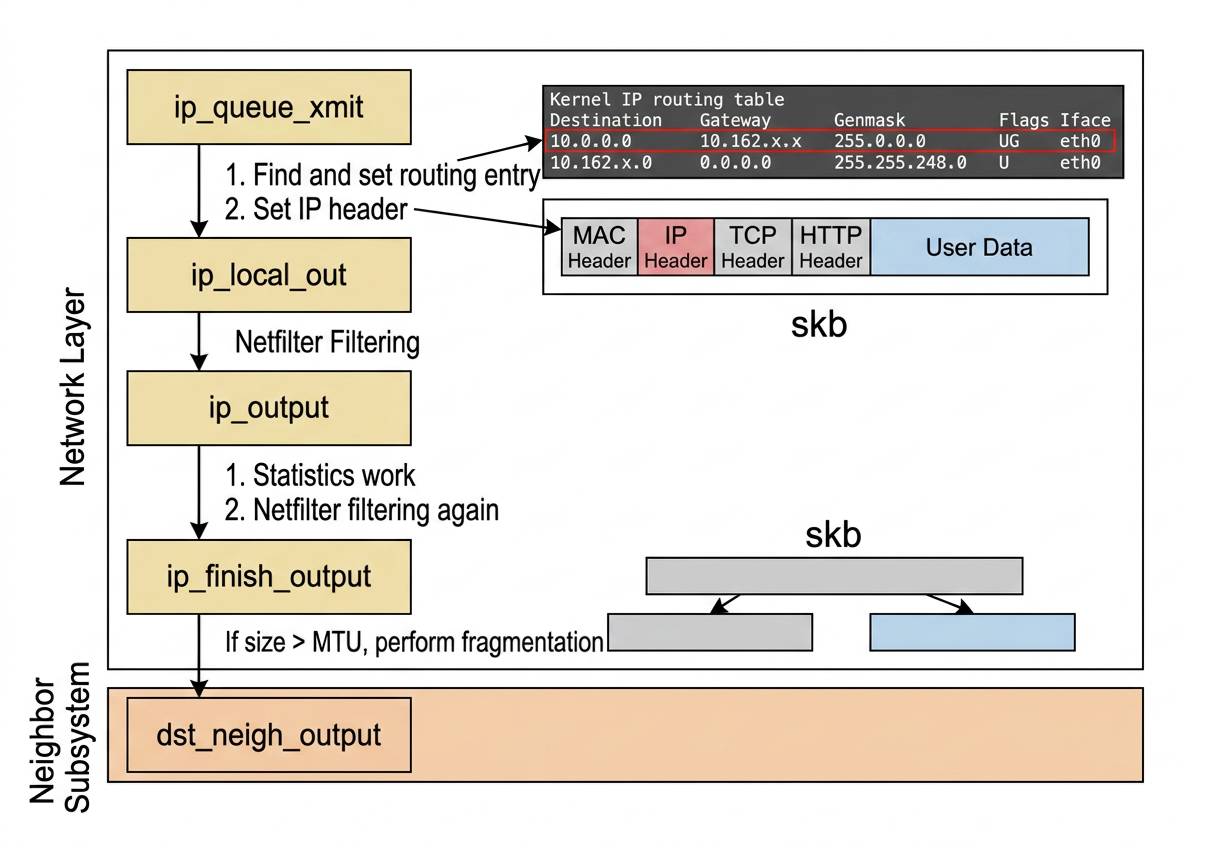
5.1.ip_queue_xmit
ip_queue_xmit
ip_queue_xmit is responsible for routing lookup and IP header construction (in net/ipv4/ip_output.c):
-
The kernel first checks whether the socket has a cached route entry.
-
If not, it calls
ip_route_output_portsto find which interface and gateway to use, then caches the result in the socket for future packets.
The routing table on a Linux machine (seen via route -n) looks like this:
Each row tells the kernel
- which NIC (
Iface) to use and - which gateway to route through
for a given destination. The selected route entry (the single row in the routing table) is stored in skb via the _skb_refdst field:
5.2.ip_local_out
ip_local_out
After setting the routing destination and constructing the IP header, ip_queue_xmit calls ip_local_out (also in net/ipv4/ip_output.c):
-
The call chain
ip_local_out→__ip_local_out→nf_hookpasses throughnetfilter. If rules are configured iniptables, they are evaluated here. -
Complex
iptablesrulesets can introduce significant CPU overhead at this point.
5.3.dst_output
dst_output
-
dst_output(ininclude/net/dst.h) finds the routing destination stored inskband invokes itsoutputfunction pointer. -
This function pointer resolves to
ip_output(innet/ipv4/ip_output.c):
-
Statistical accounting is done here (purely for observability that lets operators and monitoring systems see traffic volumes and detect anomalies).
-
netfilteris consulted again for post-routing rules, thenip_finish_outputis invoked (also innet/ipv4/ip_output.c):
5.4.ip_finish_output, the MTU and Fragmentation (3rd Clone of Data, Optional)
ip_finish_output, the MTU and Fragmentation (3rd Clone of Data, Optional)
-
If the packet size exceeds the MTU (Maximum Transmission Unit),
ip_fragmentsplits it into smaller pieces before continuing down the stack. -
The MTU is a limit imposed by the physical link — for Ethernet it is typically 1500 bytes. Fragmentation exists to handle packets larger than what a link can carry in a single frame.
However, fragmentation has two real costs.
-
Each fragment must be individually processed, increasing CPU usage across all intermediate hops.
-
If any single fragment is lost in a transit, the entire original packet must be retransmitted because IP reassembly has no partial-recovery mechanism.
Avoiding fragmentation reduces both computation overhead and retransmission cost.
The MTU itself is determined through Path MTU Discovery (PMTUD): we send packets with the "Don't Fragment" (DF) bit set, and if an intermediate router cannot forward the packet, it returns an ICMP "Fragmentation Needed" message specifying the maximum size it can handle.
The kernel then updates the cached MTU for that route, and future packets will be sized accordingly.
6.Neighbor Subsystem: ARP and MAC Header
Neighbor Subsystem: ARP and MAC Header
6.1.Next-hop IP Address and MAC Address
Next-hop IP Address and MAC Address
Before diving into the code, it helps to be clear on what these two addresses mean and why both are needed.
6.1.1.What is a Hop?
What is a Hop?
A hop is one leg of a packet's journey — the transit across a single network link from one device to the next. Every time a packet passes through a router, that counts as one hop. The IP TTL (Time To Live) field is decremented by 1 per hop; when it hits 0 the packet is dropped. This is exactly how traceroute works — each line of its output represents one hop:
6.1.2.IP Address and MAC Address
IP Address and MAC Address
IP address. A logical, routable address assigned in software. It identifies a host globally across the entire internet and stays the same as a packet is forwarded from router to router.
MAC address. A 48-bit hardware address burned into the NIC at manufacture time (e.g. 00:1A:2B:3C:4D:5E). It only identifies a device within a single local network segment (a broadcast domain / Layer-2 domain). Every Ethernet frame carries a destination MAC so the local switch knows which port to deliver the frame to.
The key distinction: IP addresses survive the entire journey end-to-end; MAC addresses are replaced at every hop.
The next-hop IP address is the IP of the immediately adjacent device the packet should be forwarded to on the current local link — it is not necessarily the final destination:
- Same subnet: next-hop = destination IP itself (peer is reachable directly).
- Different subnet: next-hop = gateway IP (the router on the local link that will forward the packet onward).
6.1.3.Why Is the Ethernet Destination MAC Needed?
Why Is the Ethernet Destination MAC Needed?
The switch — the device physically connecting machines on a local network — operates at Layer 2 and only understands MAC addresses. It has no knowledge of IP. When a frame arrives at a switch port, the switch looks at the destination MAC to decide which port to forward the frame out of, using a table like:
Without a destination MAC, the switch would have to flood the frame out of every port, wasting bandwidth. The full flow on a local link is:
The MAC is the switch's delivery address for the local segment; the IP is the router's delivery address for the global network.
The neighbor subsystem's job is to take the next-hop IP and find the MAC address that corresponds to it, so that the kernel can fill in the Ethernet destination MAC field before putting the frame on the wire.
6.2.ip_finish_output2
ip_finish_output2
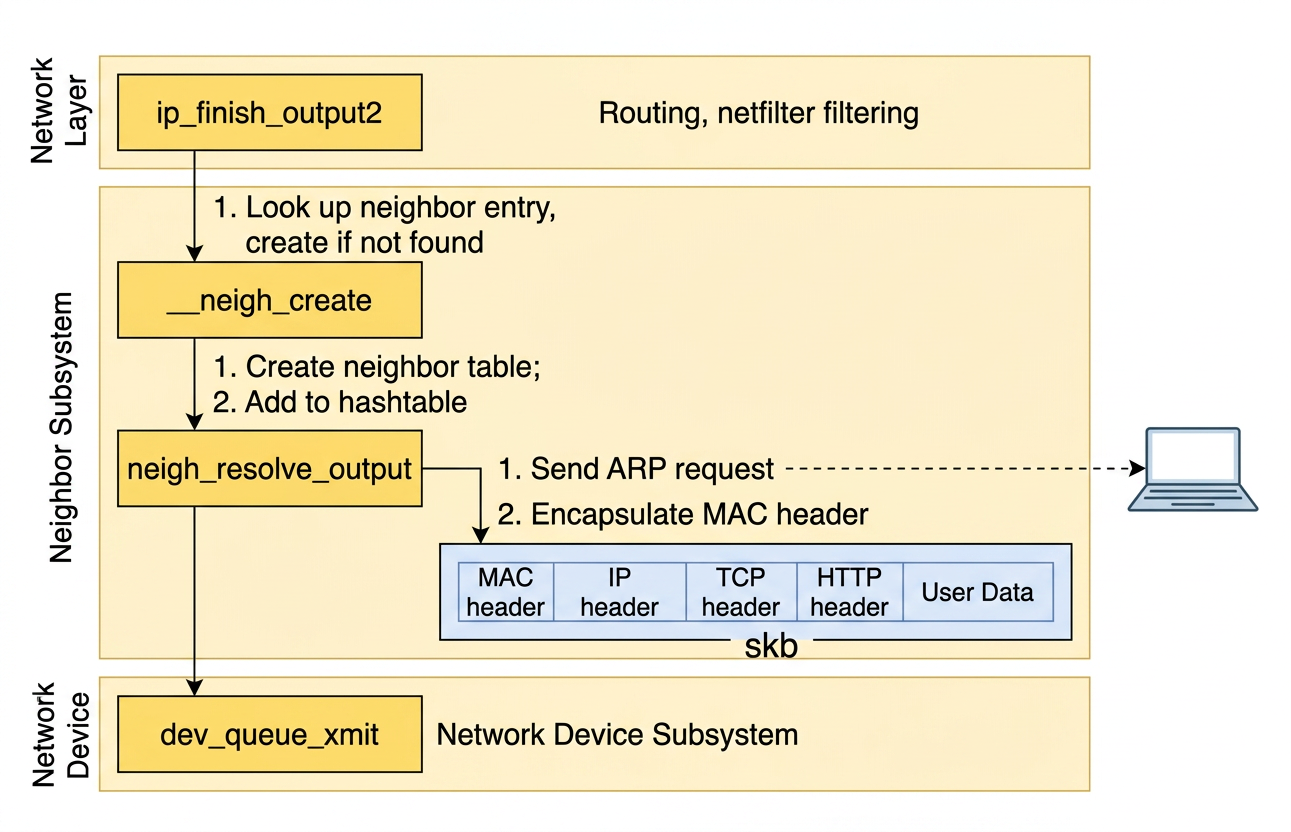
ip_finish_output2 passes the skb to the neighbor subsystem (in net/ipv4/ip_output.c):
-
The neighbor subsystem sits between the network layer and the data link layer. Its job is to resolve the next-hop IP address to a MAC (hardware) address so the kernel can construct an Ethernet frame.
-
Because this concern is shared between IPv4 and IPv6, the subsystem lives outside
net/ipv4/as a generic module that both protocol families use. This separation means neither the IP layer nor the link layer needs to contain any address-resolution logic directly.
__ipv4_neigh_lookup_noref receives the next-hop IP address (nexthop) as its second argument. This address is derived from the destination IP in the IP header — it is either the final destination itself (when the peer is on the same subnet) or the gateway address (when routing across subnets).
The function consults the ARP cache:
6.3.__ipv4_neigh_lookup_noref
__ipv4_neigh_lookup_noref
If no entry is found, __neigh_create allocates a new neighbor item (detailed in net/core/neighbour.c):
A newly-created neighbor item does not yet have a MAC address — it is in an incomplete state. ARP (Address Resolution Protocol) is used to discover the MAC address corresponding to an IP address.
When a neighbor item is first created, an ARP broadcast request is sent onto the local network, and the host with that IP responds with its MAC address. The MAC address is then stored in the neighbor entry.
6.4.dst_neigh_output
dst_neigh_output
After creation, dst_neigh_output (in include/net/dst.h) delegates to neigh_resolve_output:
The output pointer resolves to neigh_resolve_output (in net/core/neighbour.c):
neigh_event_send may trigger an ARP request if the MAC address is not yet available. Once the MAC address is known, neigh->ha holds it, and dev_hard_header attaches the Ethernet MAC header to the skb. The packet is then passed to dev_queue_xmit.
7.Network Device Subsystem: qdisc and Transmission
Network Device Subsystem: qdisc and Transmission
7.1.What is a qdisc?
What is a qdisc?
A qdisc (queueing discipline) is the kernel's traffic scheduler attached to each transmit queue of a network interface. It sits between the IP stack and the NIC driver and controls how packets are ordered, delayed, or dropped before transmission.
The application can produce packets far faster than the NIC can put them on the wire. Without a qdisc, the only options when the NIC is busy are "send immediately" or "drop immediately." A qdisc provides a managed buffer in between. More concretely, it serves three purposes:
-
Buffering / burst absorption — holds packets while the NIC is busy with a previous one, so short bursts don't cause immediate drops.
-
Traffic shaping — controls the rate at which packets leave. For example,
tbf(Token Bucket Filter) can cap an interface at exactly 100 Mbit/s regardless of how fast the kernel pushes packets down. -
Traffic prioritization / fairness — decides which packet in the queue goes next. VoIP traffic can be sent before a bulk file transfer; multiple TCP flows can be given equal throughput shares.
Common qdiscs built into the kernel:
| qdisc | Behaviour |
|---|---|
pfifo_fast | Default; simple 3-band FIFO based on ToS/DSCP |
fq_codel | Fair queuing + CoDel AQM; default on many modern distros |
tbf | Token Bucket Filter — hard rate cap |
htb | Hierarchical Token Bucket — hierarchical bandwidth allocation |
noqueue | No queuing at all; used for loopback |
The qdisc is the kernel's pluggable, per-queue packet scheduler. It is what makes tc (traffic control) possible — you can swap the qdisc on a live interface without rebooting or changing application code.
7.2.dev_queue_xmit
dev_queue_xmit
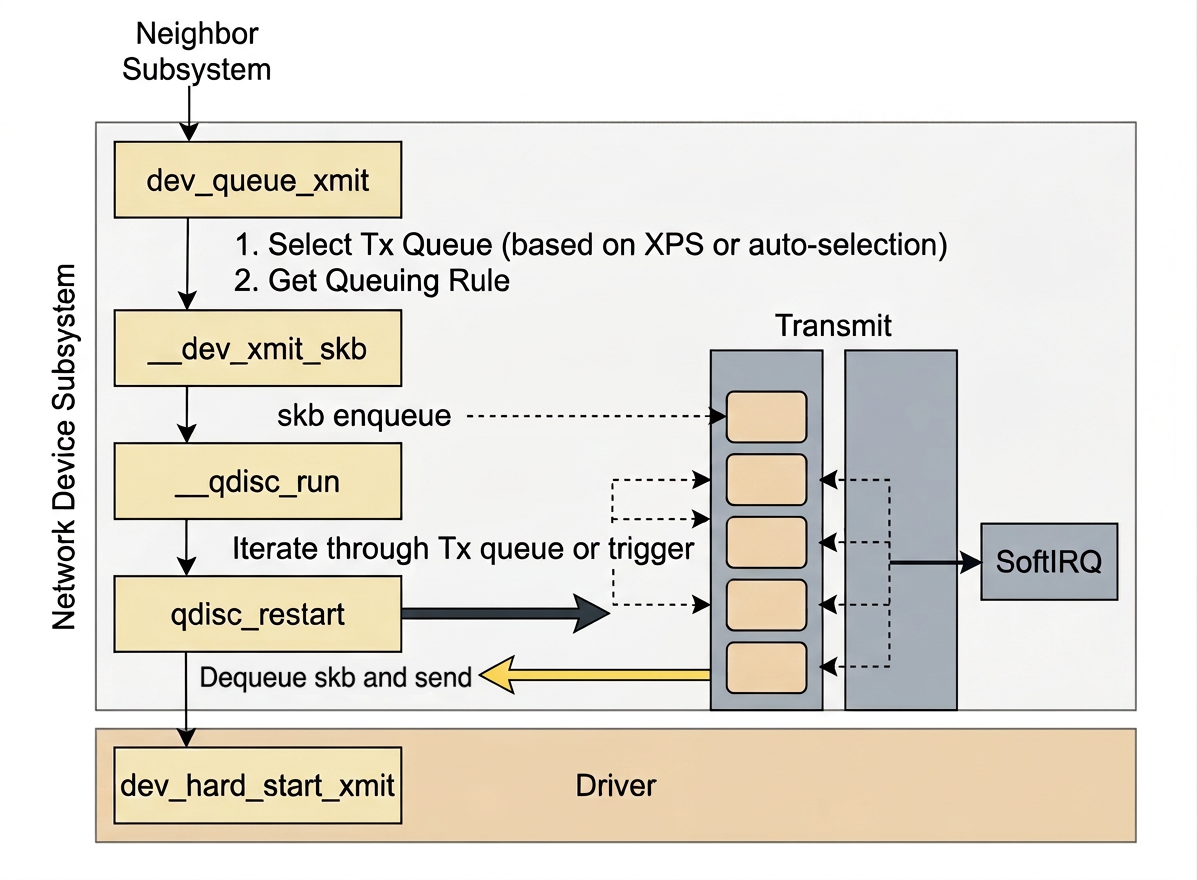
dev_queue_xmit is the entry point into the network device subsystem (in net/core/dev.c):
-
netdev_pick_txselects which of the NIC's transmit queues to use. This decision is influenced by XPS (Transmit Packet Steering) configuration. -
XPS allows us to pin specific transmit queues to specific CPU cores, reducing cache contention and improving locality. If no XPS configuration is found, the kernel falls back to computing the queue index automatically (in
net/core/flow_dissector.c):
7.3.__dev_xmit_skb
__dev_xmit_skb
After selecting the queue, we obtain the qdisc (queueing discipline) associated with it and enter __dev_xmit_skb (in net/core/dev.c):
There are two paths:
-
The queue can be bypassed entirely (if it is idle and supports bypass mode), or
-
The
skbis enqueued normally and__qdisc_runis invoked to drain it (innet/sched/sch_generic.c):
7.4.__qdisc_run
__qdisc_run
__qdisc_run loops to drain all pending skb objects from the queue, running in the context of the user process.
If the quota runs out or another process needs the CPU, the loop breaks and a NET_TX_SOFTIRQ soft interrupt is raised to continue the work outside of user process context.
This is why when we inspect /proc/softirqs, the NET_RX counter is typically much larger than NET_TX. Receiving always goes through NET_RX soft interrupts, while sending only resorts to NET_TX_SOFTIRQ when the qdisc quota is exhausted.
7.5.qdisc_restart
qdisc_restart
qdisc_restart dequeues one skb and calls sch_direct_xmit:
7.6.__netif_reschedule
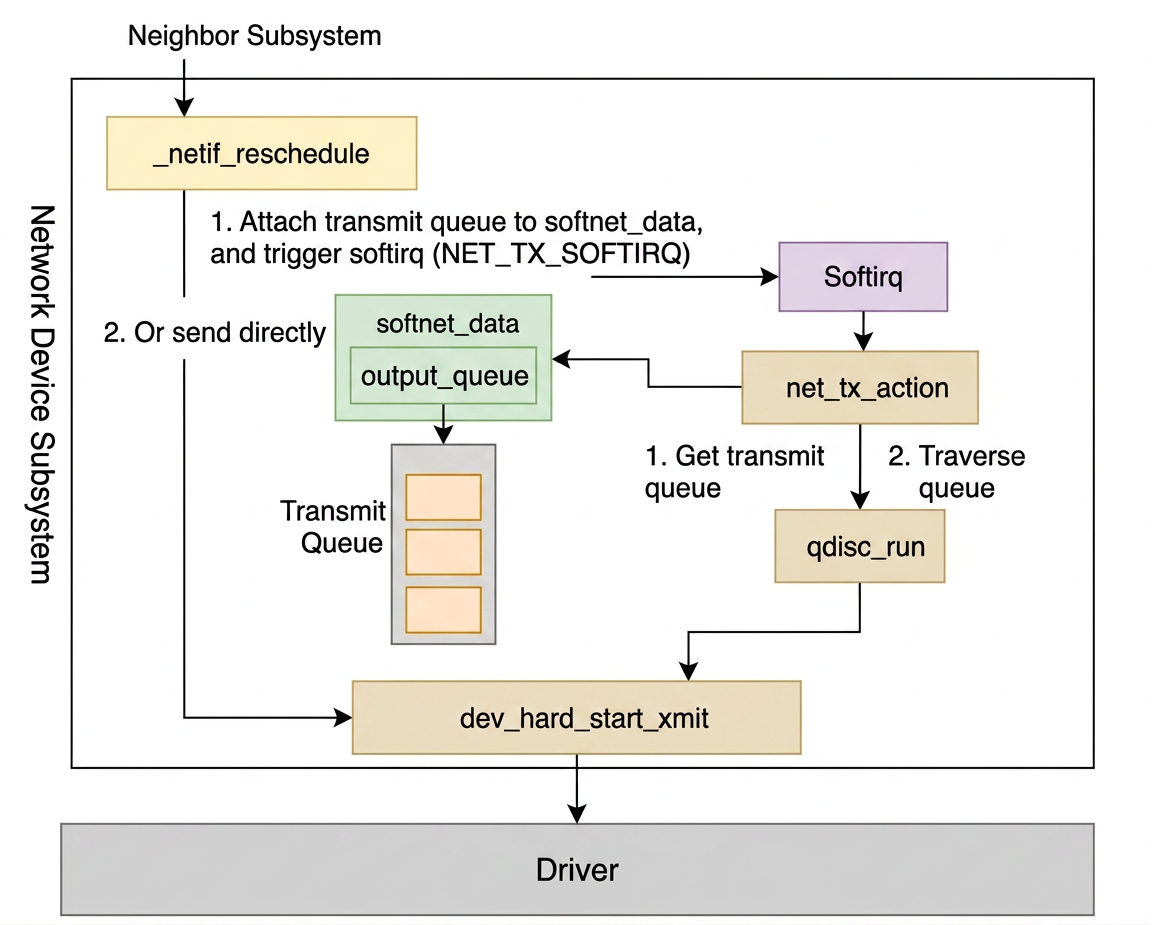
__netif_reschedule
Back to section 〈7.4. __qdisc_run〉, when the qdisc quota is exhausted, __netif_schedule calls __netif_reschedule (in net/core/dev.c):
-
softnet_dataaccumulates the queues that still have data to send. -
The registered
net_tx_actionhandler is invoked by the soft-interrupt infrastructure — outside of user process context — to continue delivering the data (innet/core/dev.c):
output_queue holds the target transmit queues.
The soft interrupt loops through them and calls qdisc_run, which goes back through __qdisc_run → qdisc_restart → sch_direct_xmit → dev_hard_start_xmit.
8.NIC Driver: Writing into the Ring Buffer
NIC Driver: Writing into the Ring Buffer
8.1.dev_hard_start_xmit
dev_hard_start_xmit
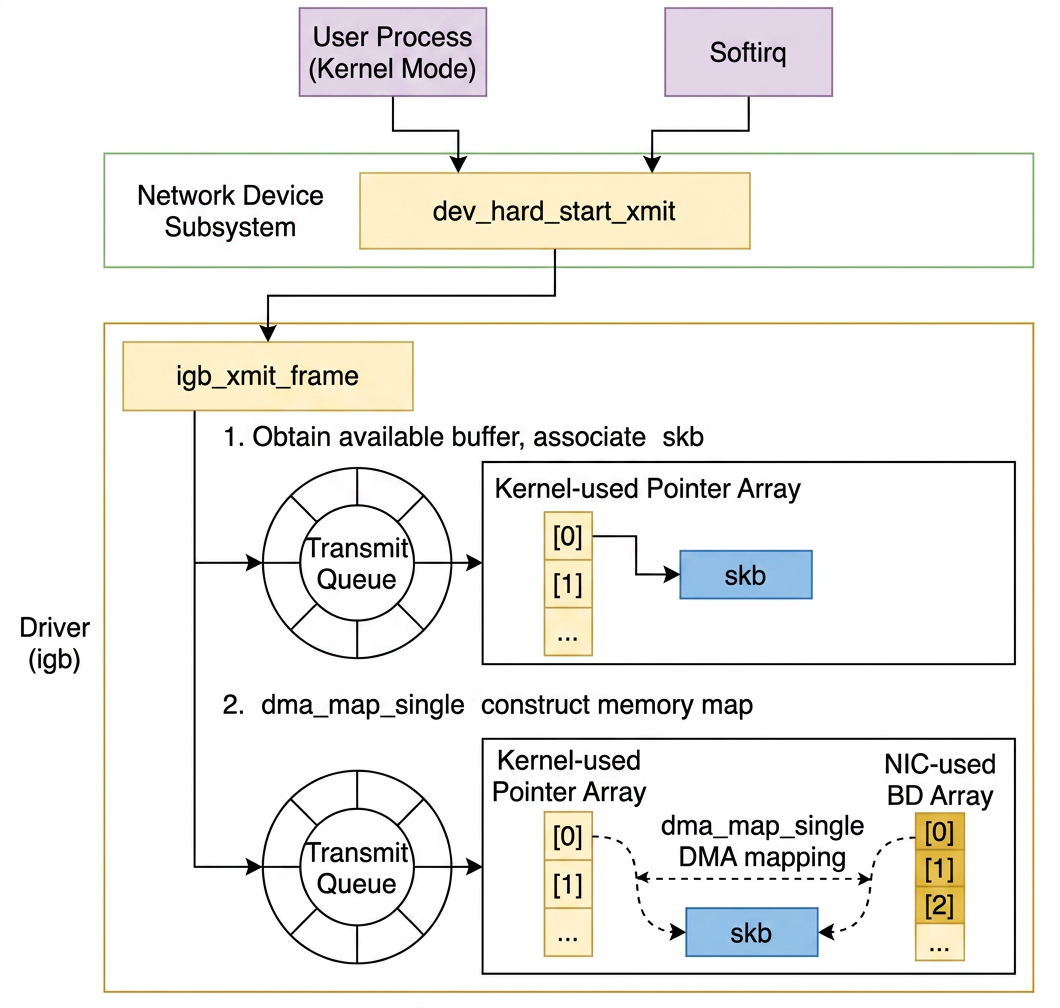
Both the user process context and the soft-interrupt context ultimately arrive at dev_hard_start_xmit (in net/core/dev.c):
ndo_start_xmit is a callback defined by the NIC driver through net_device_ops (in include/linux/netdevice.h):
In the igb NIC driver (in drivers/net/ethernet/intel/igb/igb_main.c), this is wired to igb_xmit_frame:
igb_xmit_frame selects the ring buffer and delegates to igb_xmit_frame_ring:
The transmit ring buffer picks the next available slot via next_to_use, assigns the skb, and calls igb_tx_map to create the DMA mapping (also in drivers/net/ethernet/intel/igb/igb_main.c):
dma_map_single creates a mapping between the skb's data buffer in RAM and a DMA-accessible address. The descriptor array (e1000_adv_tx_desc[]) is populated with these DMA addresses. The NIC reads the descriptors and fetches the packet data directly from RAM via DMA without involving the CPU, then transmits it onto the wire.
9.Cleanup After Transmission
Cleanup After Transmission
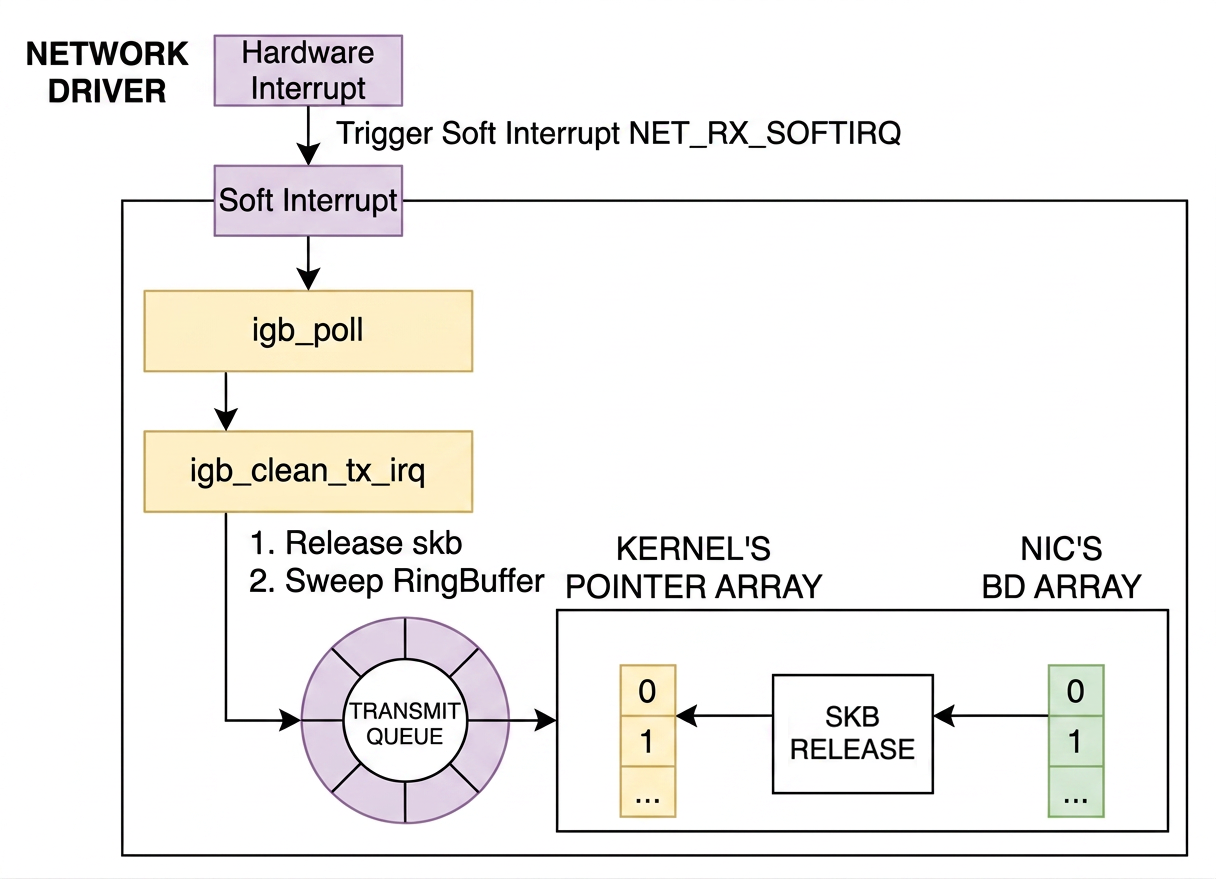
After the NIC finishes transmitting, it issues a hard interrupt to notify the kernel that the ring buffer slots can be freed. Regardless of whether the hard interrupt was caused by a receive or a transmit completion, the soft interrupt it raises is always NET_RX_SOFTIRQ (in drivers/net/ethernet/intel/igb/igb_main.c):
This is another reason NET_RX always dominates in /proc/softirqs.
The igb_poll NAPI handler handles the transmit completion cleanup:
igb_clean_tx_irq does the actual memory cleanup:
The cloned skb (the one handed down to lower layers) is freed here via dev_kfree_skb_any, the DMA mapping is removed, and the ring buffer slot is cleared.
The original skb — the one that stayed in sk_write_queue as the TCP retransmission buffer — is not freed at this point. It remains in the queue until the transport layer receives an ACK from the remote peer confirming successful delivery, at which point it is finally destroyed.
10.References
References
-
划水的猫, 网卡驱动初始化解析, 博客園
-
張彥飛, 深入理解 Linux 網絡, Broadview