







1.Socket Creation — How TCP Gets Bound to the Socket
Socket Creation — How TCP Gets Bound to the Socket
From user space:
1.1.struct sock and struct socket
struct sock and struct socket
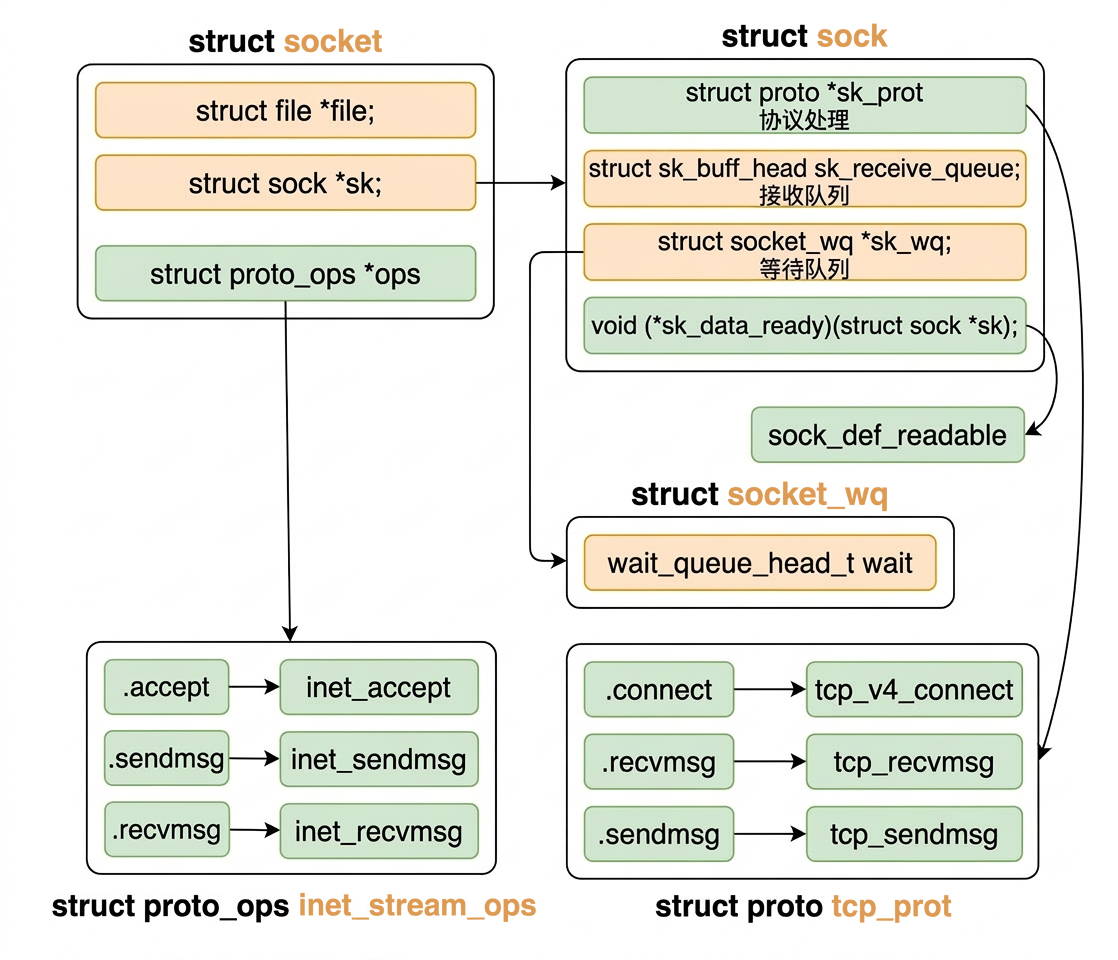
We will be explaining the components in this image throughout the article.
1.2.System Call Entry
System Call Entry
SYSCALL_DEFINE3(socket, ...) is the kernel's definition of the socket system call. It executes at the moment user-space code calls socket(AF_INET, SOCK_STREAM, 0). Here's the exact sequence:
- User space calls
socket(AF_INET, SOCK_STREAM, 0)(from glibc / a C program). - glibc issues a
syscallinstruction (on x86-64:mov $SYS_socket, %rax; syscall). - CPU switches to kernel mode; the trap handler looks up the system call table entry for
__NR_socket(syscall number 41 on x86-64). - Kernel dispatches to the function registered for that number — which is exactly what
SYSCALL_DEFINE3(socket, ...)expands to:__x64_sys_socket(...). - That function body runs — calling
sock_create()→__sock_create()→inet_create()etc., as described below.
The macro itself is a registration shorthand that:
- Generates a properly-named kernel function (
__x64_sys_socket). - Inserts a pointer to it into the kernel's syscall dispatch table at boot time.
- Handles argument copying from user-space registers into kernel-space variables.
Everything after that (the sock_create → inet_create chain) happens within the same synchronous kernel execution context before control returns to user space with the file descriptor.
Which leads to:
Remark. In linux kernel whenever a function is prefixed by __, then certain kind of invariants have been maintained before the exectution of this function.
1.3.Core Socket Construction
Core Socket Construction
1.3.1.On rcu_dereference(net_families[family]
On rcu_dereference(net_families[family]
net_families is a global array of pointers (struct net_proto_family)* indexed by address family number (e.g., AF_INET = 2).
This struct is the address-family-level factory registered with the generic socket layer. Its sole job is to provide the .create function pointer — inet_create — so that when the caller specifies AF_INET, the kernel knows how to construct the socket.
When socket(AF_INET, SOCK_STREAM, 0) is called, __sock_create() looks up net_families[AF_INET] to get &inet_family_ops, then calls pf->create(...) which resolves to inet_create(). The latter then does the real work:
- Allocating
struct sock - Binding
inet_stream_opsandtcp_prot - Calling
sock_init_data(), etc.
1.3.2.What is RCU (Read-Copy-Update)?
What is RCU (Read-Copy-Update)?
The rcu_dereference() wrapper is an RCU (Read-Copy-Update) mechanism. Since net_families can be updated at runtime (e.g., a kernel module registering or unregistering a protocol family), RCU ensures:
- The pointer read is memory-barrier-protected so you never see a partially-written pointer;
- Readers don't block writers — the old pointer stays valid until all current readers finish their RCU read-side critical section;
- A compiler barrier prevents the compiler from re-loading the pointer a second time after it may have changed.
Without rcu_dereference, a concurrent sock_unregister() could free the struct while __sock_create is still using pf->create, causing a use-after-free crash.
1.4.inet_create() — Binding TCP
inet_create() — Binding TCP
1.4.1.Implementation Detail
Implementation Detail
The key lookup is &inetsw[sock->type] (line 10).
Here sock->type is SOCK_STREAM, the offset from the pointer inetsw is exactly the index represeting the socket type, so inetsw[SOCK_STREAM] is the list of all registered protocols that serve stream sockets under AF_INET.
The loop walks that list until it finds the matching entry (e.g., IPPROTO_TCP). From the matched entry (struct inet_protosw *answer) two bindings are made:
| Assignment | Source field and Bound to | What it carries |
|---|---|---|
sock->ops = answer->ops | from inet_protosw.ops to inet_stream_ops | socket-level callbacks (recvmsg, sendmsg, …) |
sk->sk_prot = answer->prot | from inet_protosw.prot to tcp_prot | protocol-level callbacks (tcp_recvmsg, tcp_sendmsg, …) |
After sock_init_data() returns, the socket is fully wired:
- A call to
sock->ops->recvmsgdispatchesinet_recvmsg; - Which in turn calls
sk->sk_prot->recvmsg=tcp_recvmsg.
1.4.2.Protocol Operation Tables
Protocol Operation Tables
inet_stream_ops:
tcp_prot:
1.4.3.sock_init_data() — Critical Initialization
sock_init_data() — Critical Initialization
At this point the binding is complete:
2.TCP Connection Lifecycle: The Lookup Table tcp_hashinfo.ehash
TCP Connection Lifecycle: The Lookup Table tcp_hashinfo.ehash
__inet_lookup_skb (called by tcp_v4_rcv on every arriving packet) searches tcp_hashinfo.ehash — the kernel's global hash table of all established TCP connections, keyed by 4-tuple (src_ip, src_port, dst_ip, dst_port). There are two natural questions:
- When is a socket inserted into the table?
- When
close()is called, does the kernel remove it?
Both answers turn on the TCP state machine, not on any user-space call.
2.1.Insertion — During the Three-Way Handshake
Insertion — During the Three-Way Handshake
The insertion happens at the third packet of the handshake, long before accept() or recvfrom() is ever called.
Server-side path:
By the time the application calls accept(), the struct sock is already in the hash table. accept() just dequeues it from the backlog and returns a file descriptor — it does not modify the hash table at all.
Client-side path:
The client side is inserted even earlier — before the SYN goes out — so that the incoming SYN-ACK can be routed back to the correct socket.
2.2.inet_ehash_insert() — How the 4-Tuple Becomes Searchable
inet_ehash_insert() — How the 4-Tuple Becomes Searchable
When a packet later arrives and tcp_v4_rcv calls __inet_lookup_skb, it hashes the packet's 4-tuple identically and walks that same bucket, typically in , to find the match.
2.3.Removal — close() calls inet_unhash()
Removal — close() calls inet_unhash()
When close(conn_fd) is called the kernel removes the socket from the hash table, but not immediately at the close() call. It happens when the TCP state machine transitions to TCP_CLOSE:
After inet_unhash() returns, no arriving packet with that 4-tuple can be routed to this socket. Any late-arriving packets hit the goto no_tcp_socket path in tcp_v4_rcv and trigger an RST reply, where RST means Reset (a control flag in the TCP header used to abruptly terminate a connection).
TIME_WAIT. The socket is not removed from the table at the instance close() is called, the removal happens after the FIN-ACK exchange completes and any queued data is flushed. Furthermore, after the socket itself is freed, a lightweight tcp_timewait_sock takes its place in tcp_hashinfo.ehash for 2×MSL seconds (typically 60 s on Linux). This TIME_WAIT entry absorbs any late duplicate packets that arrive after the connection is logically closed, preventing them from being misdelivered to a future connection that reuses the same 4-tuple.
2.4.Summary
Summary
| Event | Hash table operation | Called by |
|---|---|---|
Client calls connect() | inet_ehash_insert() | __inet_hash_connect() |
| Server receives final ACK | inet_ehash_insert() | inet_csk_complete_hashdance() |
accept() in user space | none | — |
recvfrom() in user space | none | — |
close() → TCP_CLOSE | inet_unhash() | tcp_close() → tcp_set_state() |
| 2×MSL timer fires | Remove TIME_WAIT entry | tcp_time_wait_kill() |
3.Blocking IO
Blocking IO
3.1.Flow
Flow
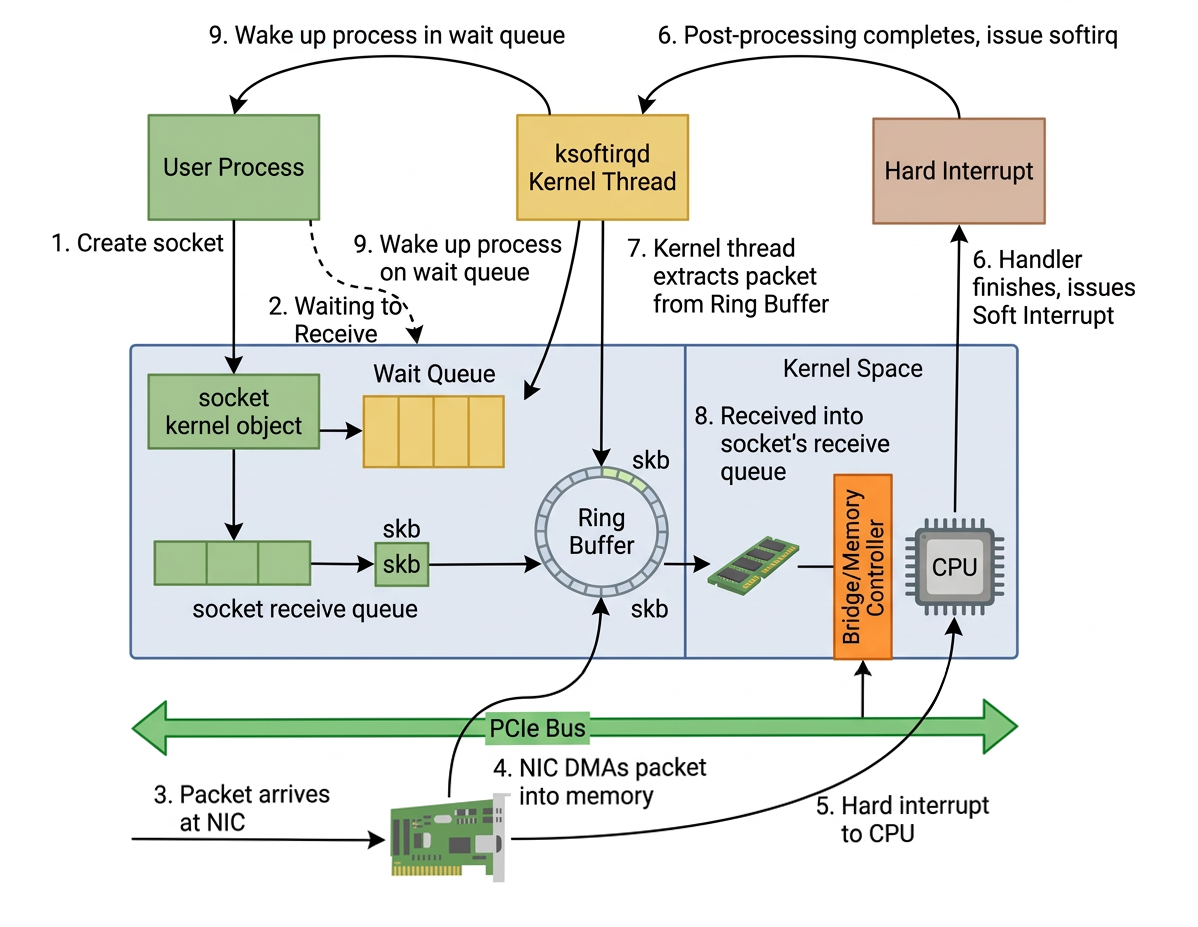
For simple commands in linux networking in C such as int sk = socket(AF_INET, SOCK_STREAM, 0), bind, accept, listen, etc, both the user process and the kernel perform a considerably significant amount of work together.
First, the user process issues a command to create a socket, which causes a switch to kernel mode where the kernel initializes the necessary kernel objects.
When receiving network packets in Linux, the handling is performed by hardware interrupts and the ksoftirqd thread. After ksoftirqd finishes processing the packet, it notifies the relevant user process.
From
The moment a socket is created
to
When a network packet arrives at the NIC and its data is finally read by the user process
The overall workflow of synchronous blocking I/O follows the sequence illustrated in the diagram below:
3.2.recvfrom() Execution Path
recvfrom() Execution Path
After a socket is created and a connection is established, either via connect() on the client side or accept() on the server side, the user process calls recvfrom() to read incoming data:
Remark. recvfrom() is called on the connected socket (conn_fd), not the listening one. The listening socket (server_fd) has no TCP connection state — its only job is to accept new clients. It has no sk_receive_queue carrying application data.
When a client connects, the kernel creates a new struct sock for that specific client connection with its own TCP state machine, its own sequence numbers, and its own sk_receive_queue.
accept() returns conn_fd, which is an integer file descriptor that indirectly reaches this struct sock through the chain: fd → struct file → struct socket → struct sock → sk_receive_queue.
Note that both accept() and recvfrom() are blocking calls, but they block for different reasons:
| Call | Blocks waiting for |
|---|---|
accept() | a client to complete the TCP three-way handshake |
recvfrom() | data to arrive on an already-established connection |
3.2.1.System Call Entry
System Call Entry
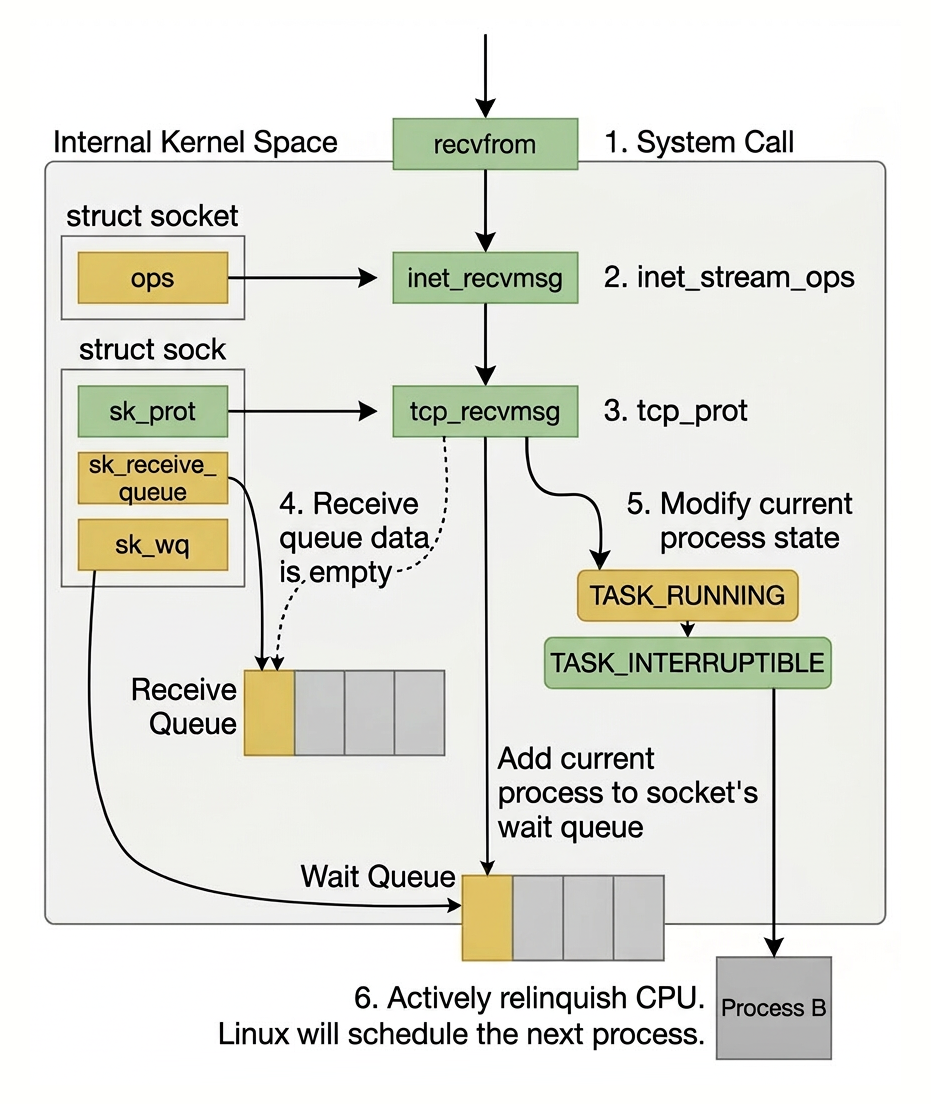
Let's look at the underlying implementation that the recv function relies on. First, by tracing with the strace command, we can see that the C library function recv executes the recvfrom system call.
After entering the system call, the user process enters kernel mode and executes a series of kernel protocol layer functions.
It then checks the receive queue of the socket object (sk->sk_receive_queue) to see if there is any data; if not, it adds itself to the wait queue corresponding to the socket.
Finally, it yields the CPU, and the operating system will select the next process in the ready state to execute. The entire process is shown in the following figure:
3.2.2.Layered Dispatch
Layered Dispatch
Remark. sock_recvmsg first calls security_socket_recvmsg() — an LSM (Linux Security Module) hook that lets SELinux / AppArmor / etc. deny the call before any data is touched.
The _nosec suffix on sock_recvmsg_nosec means "the security check has already been done; skip it".
This two-step pattern appears throughout the kernel socket layer.
3.2.3.inet_recvmsg()
inet_recvmsg()
Earlier we have mentioned that sock->ops was bound to inet_stream_ops during inet_create(), and inet_stream_ops.recvmsg = inet_recvmsg. So sock->ops->recvmsg resolves to inet_recvmsg:
sk->sk_prot was bound to tcp_prot during inet_create() via
sk_alloc(..., answer->prot, ...)andtcp_prot.recvmsg = tcp_recvmsg
So sk->sk_prot->recvmsg resolves to tcp_recvmsg:
3.2.4.tcp_recvmsg() and skb_queue_walk: The Core Receive Logic
tcp_recvmsg() and skb_queue_walk: The Core Receive Logic
skb_queue_walk is a macro that expands to a for loop iterating over every struct sk_buff in sk->sk_receive_queue, which is a doubly-linked list:
Each sk_buff holds a TCP segment's payload. Inside the loop body,
copies the payload bytes from the kernel skb into the user-space buffer, and copied += chunk accumulates the total. The walk stops naturally when the queue is exhausted (the sentinel node is reached).
If copied has not yet reached target bytes at that point, the else branch calls sk_wait_data to block until more data arrives.
Remark (What is Sentinel?). sk_receive_queue is a circular doubly-linked list where the queue head itself is the sentinel, a dummy node embedded in struct sock that carries no data. The walk stops when skb laps back and equals the head:
When the queue is empty, head->next == head, so the loop body never executes. This is the standard Linux list_head idiom used throughout the kernel.
3.2.5.What's Happening when Copying Data from the List of skb's
What's Happening when Copying Data from the List of skb's
There are several layers involved, and only the last one is a real CPU copy:
-
NIC → DMA → kernel pages (no CPU copy). The NIC writes packet bytes directly into kernel-allocated memory pages via DMA. No CPU is involved.
-
Ring buffer descriptor →
sk_buff(no CPU copy). The NAPI/softIRQ driver wraps the ring buffer entry into ansk_buffby storing a pointer (skb->data) into those same DMA-written pages. No bytes are moved. -
IP/TCP header stripping (no CPU copy). The IP/TCP layers strip headers by advancing the
skb->dataand enqueue thesk_buffof the forminto
sk->sk_receive_queue.Note that by strip we simply mean doing pointer-arithmatics to ignore the consumed headers.
-
skb_copy_datagram_msg→ user buffer (actual CPU copy). This is the only real copy. It reads fromskb->data(ultimately pointing to the DMA pages) and writes across the kernel/user boundary into the user-space buffer.
3.2.6.Why CPU copy is Necessary in skb_copy_datagram_msg?
Why CPU copy is Necessary in skb_copy_datagram_msg?
The kernel/user boundary is enforced by the CPU's MMU (Memory Management Unit). Every process's virtual address space is split into two halves:
- Kernel Space (ring 0 only) and
- User Space (ring 3)
The MMU marks kernel pages as supervisor-only:
Because of this separation, a raw pointer to skb->data cannot be handed to user space, the process's page table has no mapping for that kernel address, so accessing it from ring 3 would immediately fault.
The kernel equally cannot write to a user pointer without first validating it. copy_to_user() is the sanctioned path: it validates the destination pointer, handles any page faults safely, and physically copies bytes from the kernel page to the user page via CPU load/store instructions.
This is why the skb_copy_datagram_msg → user-buffer step is the performance bottleneck in classic socket receives — every byte must be touched by the CPU a second time. Zero-copy technologies (MSG_ZEROCOPY, io_uring, splice, kernel TLS, RDMA) exist specifically to eliminate or reduce this crossing.
3.3.What Happens If No Data?
What Happens If No Data?
3.3.1.sk_wait_data
sk_wait_data
When there is no data, from line 22 in the first code block of 〈3.2.4. tcp_recvmsg() and skb_queue_walk: The Core Receive Logic〉 we are blocked by sk_wait_data to await for new incoming data.
The definition of sk_wait_data relies on the following macros:
First, under the DEFINE_WAIT macro, a wait queue entry wait is defined:
In this newly created wait queue entry:
- The callback function
autoremove_wake_functionis registered (for what are being removed, see 〈3.5. Wake-Up Path〉), and - The current process descriptor
currentis associated with its private member:
Now sk_wait_data is defined as follows, in which we focus on sk_sleep first:
3.3.2.sk_sleep
sk_sleep
In sk_wait_data, the function sk_sleep is called to obtain the wait queue head wait_queue_head_t under the sock object.
The source code of sk_sleep is as follows:
3.3.3.prepare_to_wait() — What Actually Happens
prepare_to_wait() — What Actually Happens
This does two critical things:
- Adds current process to the socket wait queue.
- Changes process state to
TASK_INTERRUPTIBLE.
3.3.4.sk_wait_event
sk_wait_event
sk_wait_event can expand roughly to:
So the actual CPU yield happens at schedule_timeout() → schedule().
The process is removed from the run queue here. More precisely, schedule() sets task_struct->state to TASK_INTERRUPTIBLE (a flag, not a physical removal) so the scheduler will skip it when selecting the next task to run. It remains suspended until sock_def_readable() wakes it up.
Remark (schedule() is Blocking). When schedule() is called, the process is blocked from the caller's perspective, but the CPU is not. schedule() performs a context switch: it saves the current process's registers and stack pointer, then loads another task's. Execution of the current process is frozen at that instruction until try_to_wake_up() sets its state back to TASK_RUNNING and re-enqueues it. The CPU runs other tasks in the meantime. In short: schedule() blocks the calling process, never the CPU.
Note also that release_sock / lock_sock bracket the sleep — the socket lock is dropped while the process sleeps so incoming softIRQ work can enqueue skbs, then reacquired before checking the condition again.
3.4.Hardware → Kernel → Socket Queue: The SoftIRQ Receive Path
Hardware → Kernel → Socket Queue: The SoftIRQ Receive Path
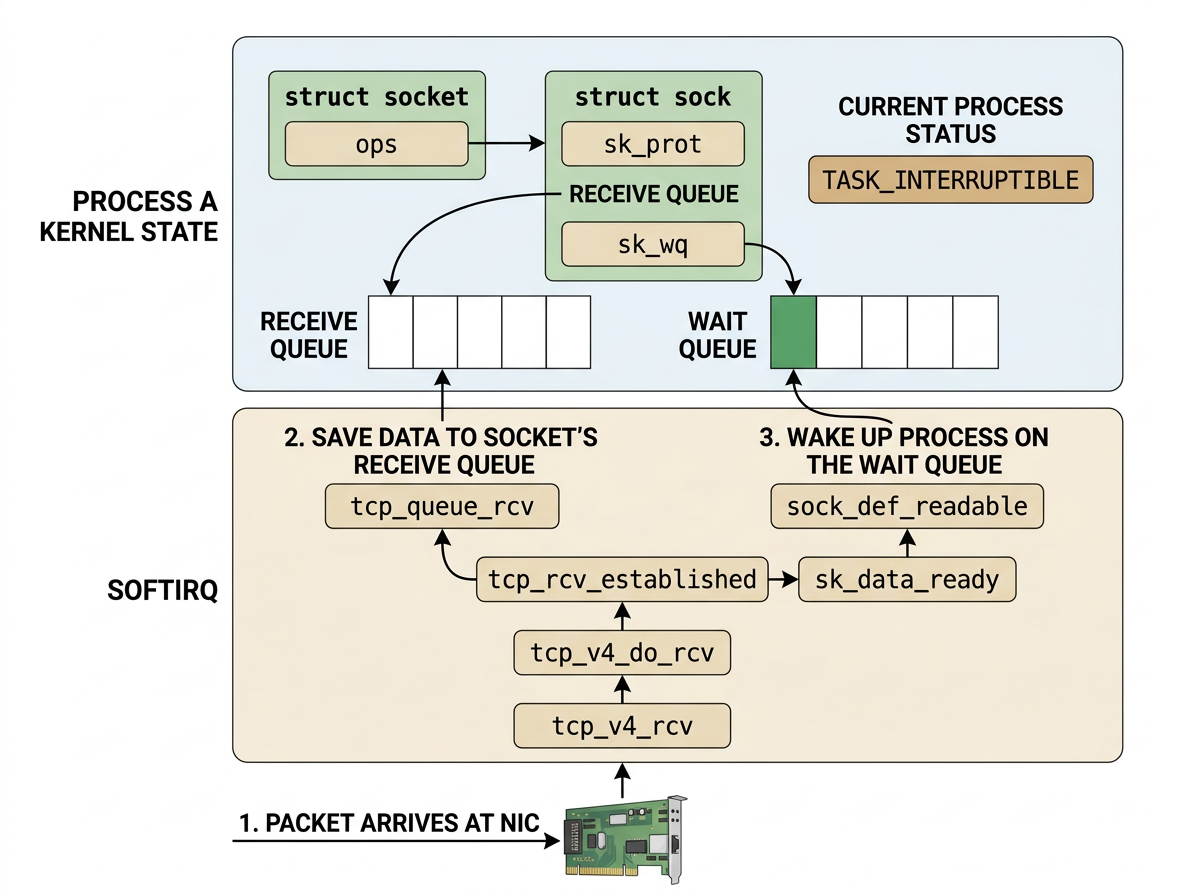
While the user process is asleep inside schedule():
- The NIC fires a hardware interrupt
- The kernel's NAPI/softIRQ machinery processes the packet up through the IP layer
- And then TCP takes over.
The entry point for every incoming IPv4 TCP segment is tcp_v4_rcv.
3.4.1.tcp_v4_rcv — Entry Point
tcp_v4_rcv — Entry Point
The hash table lookup __inet_lookup_skb finds the exact struct sock that accept() returned. This is how the kernel routes an arriving packet to the correct connection out of potentially thousands.
3.4.2.tcp_v4_do_rcv — Dispatch by Connection State
tcp_v4_do_rcv — Dispatch by Connection State
For an already-established connection receiving payload data, the fast path tcp_rcv_established is taken.
3.4.3.tcp_rcv_established — Fast Path for In-Order Data
tcp_rcv_established — Fast Path for In-Order Data
Two things happen at the end:
tcp_queue_rcvpushes theskbonto the socket's receive queue.sk->sk_data_ready(set tosock_def_readableduringsock_init_data) wakes the sleeping process.
3.4.4.tcp_queue_rcv — Enqueue to sk_receive_queue
tcp_queue_rcv — Enqueue to sk_receive_queue
After this returns, sk->sk_receive_queue is no longer empty — the skb_queue_walk loop in tcp_recvmsg will find data on its next iteration.
3.5.Wake-Up Path
Wake-Up Path
Because sock_init_data() set sk->sk_data_ready = sock_def_readable, when data is queued:
Internally, wake_up_interruptible_sync_poll expands through three layers:
__wake_up_common_lock acquires the wait queue spinlock and delegates to __wake_up_common:
__wake_up_common is where the actual traversal and per-entry wake happens:
nr_exclusive = 1 was passed from __wake_up_sync_key, so the loop stops after the first successfully woken exclusive waiter — exactly one sleeping recvfrom() caller is woken per data-ready event.
curr->func is autoremove_wake_function — the callback registered by DEFINE_WAIT — which does three things in sequence:
- Removes the wait queue entry from the list (the "autoremove" part), so the process won't be woken again.
- Calls
try_to_wake_up(), which:- Sets
task_struct->stateback toTASK_RUNNING. - Selects an appropriate CPU run queue and enqueues the task onto it.
- Sets
- Returns
1, which satisfies theWQ_FLAG_EXCLUSIVEbreak condition above, stopping the walk.
The process is now on a run queue but not yet executing — the softIRQ context that called sock_def_readable is still running.
Since wake_up_interruptible_sync_poll uses the _sync variant, it explicitly defers the reschedule: it sets a TIF_NEED_RESCHED flag on the target CPU instead of triggering an immediate context switch. The scheduler will perform the actual switch once the softIRQ exits and the CPU returns to the normal kernel/user preemption point.
3.6.Process Resumes
Process Resumes
When the softIRQ exits, the CPU checks TIF_NEED_RESCHED and calls schedule(). The scheduler picks our process off the run queue and resumes it — execution continues from exactly where it left off inside schedule_timeout() → schedule(), unwinding back up through sk_wait_event.
lock_sock(sk) reacquires the socket lock, then sk_wait_event re-evaluates the condition !skb_queue_empty(&sk->sk_receive_queue) — which is now true since tcp_queue_rcv already enqueued the skb. The condition is satisfied, so sk_wait_data falls through to finish_wait:
finish_wait sets the process state back to TASK_RUNNING (in case it was woken by a signal rather than autoremove) and removes the wait queue entry if it wasn't already removed by autoremove_wake_function.
Control returns to the do { } while loop in tcp_recvmsg. This time skb_queue_walk finds data in sk_receive_queue, skb_copy_datagram_msg copies the payload across the kernel/user boundary via copy_to_user, and recvfrom() eventually returns the byte count to user space.
4.Full End-to-End Flow
Full End-to-End Flow
5.References
References
- 張彥飛, 深入理解 Linux 網絡, Broadview