







1.ksoftirqd and ksoftirqd_should_run
ksoftirqd and ksoftirqd_should_run
Each CPU core has a dedicated kernel thread called ksoftirqd/N (where N is the CPU index). It is created at boot time via smpboot_register_percpu_thread.
Once created, the thread enters a loop managed by the smpboot infrastructure: it repeatedly calls ksoftirqd_should_run to decide whether there is pending softirq work, then calls run_ksoftirqd to process it.
ksoftirqd_should_run is not an explicit while loop in user-visible code — the looping is done by smpboot's thread function. Internally ksoftirqd_should_run simply checks whether any softirq is pending:
If local_softirq_pending() returns non-zero — meaning at least one softirq bit is set for this CPU — the thread wakes up and calls run_ksoftirqd, which in turn calls __do_softirq.
__softirq_pending is a per-CPU bitmask — one bit per softirq type. local_softirq_pending() simply reads it:
This is the exact same variable that __raise_softirq_irqoff writes to inside the ISR:
So the full round-trip is: igb_msix_ring (ISR) calls
__raise_softirq_irqoff(NET_RX_SOFTIRQ)- sets bit 3 of
__softirq_pendingfor this CPU -
ksoftirqd_should_runcallslocal_softirq_pending() - reads that same bit
- returns non-zero
-
ksoftirqdwakes.
The ISR sets the bit; ksoftirqd wakes because it reads it. That function iterates over the pending softirq bits and invokes the registered handler for each one. After draining the queue, the thread goes back to sleep.
The result is a recurring, CPU-affine loop that processes soft interrupts without starving user-space.
2.The Role of poll_list
The Role of poll_list
poll_list is a linked list of napi_struct instances. When a NIC's hard interrupt is fired, the NIC driver (i.e. igb in this article — the kernel module that knows how to talk to this specific piece of hardware) adds its napi_struct to the current CPU's softnet_data.poll_list and then disables further NIC interruptions for that queue. Then, during net_rx_action, the kernel iterates over poll_list, calling each registered poll function to drain the hardware ring buffer.
After the ring is empty the NIC's interrupttion is re-enabled. poll_list is therefore the central handoff point between the hard-interrupt world and the softirq world.
3.NAPI — Polling Phase
NAPI — Polling Phase
3.1.What napi_struct Is
What napi_struct Is
napi_struct is a pure software scheduling handle. It carries no packet payload and touches no DMA memory. The three distinct things involved are:
| Thing | What it is | Where it lives |
|---|---|---|
e1000_adv_rx_desc[] | Hardware descriptor ring — physical DMA addresses the NIC writes packet bytes into | DMA-coherent memory, shared with NIC hardware |
igb_rx_buffer[] | Kernel-side mirror — struct page* and virtual addresses matching each descriptor slot | Normal kernel memory (vmalloc) |
napi_struct | Scheduling handle — tells NAPI "queue N exists, here is its poll function, here is its budget" | Embedded inside igb_q_vector, normal kernel memory |
So when igb_msix_ring calls napi_schedule(&q_vector->napi), it is not touching any packet data or DMA memory at all. It is simply putting the napi_struct onto softnet_data.poll_list — saying "please call my poll function soon".
The poll function (igb_poll) is what later actually touches the e1000_adv_rx_desc[] ring to read packet data:
3.2.Inside igb_poll and igb_clean_rx_irq
Inside igb_poll and igb_clean_rx_irq
igb_poll is the NAPI poll callback registered during igb_probe. It is called by net_rx_action with a budget — the maximum number of packets it is allowed to process in this invocation. It delegates the actual per-packet work to igb_clean_rx_irq, which walks the hardware descriptor ring:
The four key functions inside the loop:
-
igb_fetch_rx_buffer— locates theigb_rx_bufferentry matching the current descriptor, maps the DMA page into astruct sk_buff, and returns it. For multi-fragment frames it accumulates fragments into the sameskbacross iterations. -
igb_is_non_eop— checks the EOP (End-Of-Packet) bit in the descriptor status. If the bit is clear, the current descriptor is only part of a larger frame; the function advances the ring head and returnstrueso the loop continues gathering the remaining fragments before any further processing. -
igb_cleanup_headers— validates the completed frame: checks for DMA errors, bad length, and malformed Ethernet/IP headers reported by hardware. If the frame is unusable it frees theskband returnstrue, causing the loop to discard it and move on. -
igb_process_skb_fields— fills in software metadata that upper layers depend on: checksum offload result, hardware timestamp, VLAN tag, and theprotocolfield that tells the network stack which L3 handler to invoke. -
napi_gro_receive— passes the completed, validatedskbto the GRO (Generic Receive Offload) layer. Internally it resets the GRO offset, runs the coalescing logic, and then finalises the result.
3.3.Inside napi_gro_receive
Inside napi_gro_receive
Three things happen in sequence:
-
skb_gro_reset_offset— initialises the GRO bookkeeping fields inside theskb. Specifically it setsskb->data_offsetto zero andskb->lento the total data length, establishing a clean baseline so thatdev_gro_receivecan walk the packet headers from the start. Without this reset, stale offsets from previous use of theskbslab object could cause the GRO engine to misparse the headers. -
dev_gro_receive— the core coalescing logic. It iterates over the NAPI instance's GRO list (napi->gro_list), which holdsskbs that are waiting to be merged. For each candidate it calls the registered GRO receive hooks (one per protocol layer — Ethernet, VLAN, IP, TCP) to decide whether the incomingskbcan be appended to an existing entry. If a match is found, the payload is merged and the return value isGRO_MERGEDorGRO_MERGED_FREE. If no match is found, theskbis added togro_listas a new candidate andGRO_HELDis returned. If GRO decides coalescing is impossible or undesirable (e.g. non-TCP, fragmented IP), it returnsGRO_NORMAL, meaning theskbshould go straight up the stack. -
napi_skb_finish— acts on the result code fromdev_gro_receive:GRO_NORMAL— callsnetif_receive_skbimmediately, sending theskbup throughip_rcvto the transport layer.GRO_HELD— does nothing; theskbstays ongro_listwaiting for more segments.GRO_MERGED_FREE— frees the now-consumedskb(its data was appended to an existing GRO entry).GRO_MERGED— does nothing extra; the merged superframe remains ongro_list.
When
igb_pollcallsnapi_complete_doneat the end of a polling cycle, anyskbs still sitting ongro_listare flushed vianapi_gro_flush, which callsnetif_receive_skbfor each one, ensuring no data is stranded indefinitely.
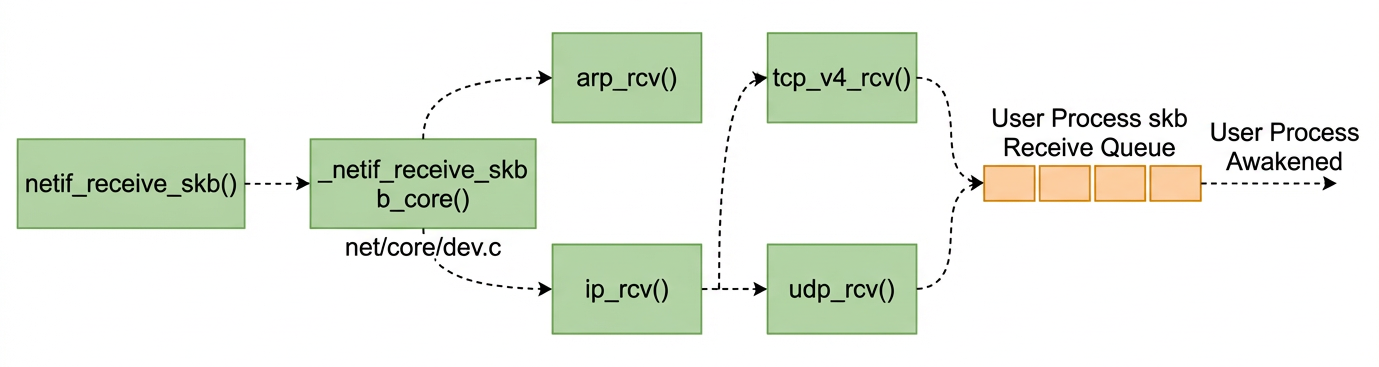
4.netif_receive_skb — Protocol Dispatch
netif_receive_skb — Protocol Dispatch
This is what netif_receive_skb doing:
4.1.How tcpdump hooks in — packet_create and register_prot_hook
How tcpdump hooks in — packet_create and register_prot_hook
When we run tcpdump, it opens a raw packet socket:
The kernel handles this via packet_create (in net/packet/af_packet.c):
packet_create allocates a packet_sock, fills in a packet_type struct embedded inside it, and then calls register_prot_hook.
4.2.register_prot_hook — why ETH_P_ALL goes to ptype_all
register_prot_hook — why ETH_P_ALL goes to ptype_all
dev_add_pack inspects pt->type. If it equals htons(ETH_P_ALL) (value 0x0003), the packet_type is inserted into the global ptype_all list. Any other protocol value goes into the hash table ptype_base, keyed by protocol number.
This split is the entire reason tcpdump sees every packet. ptype_all is walked before protocol demultiplexing happens in __netif_receive_skb_core, so every skb — IP, ARP, IPv6, anything — passes through it unconditionally, regardless of its EtherType.
4.3.deliver_skb — handing the packet to the hook
deliver_skb — handing the packet to the hook
deliver_skb does two things:
-
Increments
skb->users— takes a reference on theskbso the packet is not freed while the hook is still reading it. This is safe because the kernel uses a "lazy" delivery pattern: it remembers the previouspacket_type(pt_prev) and only delivers it when it moves on to the next one, so there is always one outstanding reference at the boundary. -
Calls
pt_prev->func— for a raw socket registered by tcpdump, this ispacket_rcv. That function copies the packet data into the socket's receive queue (sk->sk_receive_queue) so the userspace process can retrieve it withrecvfromorread. The originalskbcontinues up the normal stack unaffected.
4.4.Two loops in __netif_receive_skb_core
Two loops in __netif_receive_skb_core
The function deliberately runs two separate loops:
| Loop | List | Who registers here | What it does |
|---|---|---|---|
| First | ptype_all | tcpdump (ETH_P_ALL), other promiscuous sniffers | Delivers to every registered sniffer before any protocol decision |
| Second | ptype_base[hash] | IP (ETH_P_IP), ARP (ETH_P_ARP), IPv6 (ETH_P_IPV6), … | Delivers to exactly the handler matching the frame's EtherType |
The first loop runs unconditionally on every packet, giving sniffers a copy of the raw frame. The second loop delivers the packet to the correct L3 handler — ip_rcv for IPv4, and so on — which is the normal receive path.
5.The IP Layer — ip_rcv to ip_local_deliver_finish
The IP Layer — ip_rcv to ip_local_deliver_finish
Once netif_receive_skb dispatches the skb through ptype_base to ip_rcv, the kernel is now inside the IP layer. The job here is threefold: run Netfilter hooks, perform routing, and hand the packet off to the correct transport-layer handler.
5.1.ip_rcv — the entry point and the first Netfilter hook
ip_rcv — the entry point and the first Netfilter hook
ip_rcv performs basic sanity checks on the IP header (version, header length, checksum, total length). If anything looks wrong the packet is dropped immediately. If it passes, rather than calling ip_rcv_finish directly, it goes through NF_HOOK.
NF_HOOK is the Netfilter hook mechanism. It traverses all rules registered at the NF_INET_PRE_ROUTING hook point — this is where iptables -t raw and iptables -t nat PREROUTING rules live. Each registered hook function can return one of: NF_ACCEPT (continue), NF_DROP (discard), or NF_STOLEN (hook takes ownership). Only if the final verdict is NF_ACCEPT does NF_HOOK call the continuation function, ip_rcv_finish.
5.2.ip_rcv_finish — routing decision
ip_rcv_finish — routing decision
ip_rcv_finish does the routing lookup. skb_dst(skb) checks whether a destination cache entry (dst_entry) is already attached to this skb — for example by a previous early-demux shortcut. If not, ip_route_input_noref is called to perform a full FIB (Forwarding Information Base) lookup.
The lookup determines one of three outcomes:
- The packet is for this host (
RT_SCOPE_HOST) —dst->inputis set toip_local_deliver. - The packet must be forwarded —
dst->inputis set toip_forward. - The packet is for a multicast group we are subscribed to — handled by
ip_route_input_mc, which also setsdst->input = ip_local_deliverwhenour = 1.
After the routing decision is recorded in the dst_entry, ip_rcv_finish calls dst_input:
This is an indirect call through the function pointer stored in dst->input. For locally-destined packets that pointer is ip_local_deliver.
5.3.ip_local_deliver — reassembly and the second Netfilter hook
ip_local_deliver — reassembly and the second Netfilter hook
Two things happen here:
-
Fragment reassembly —
ip_is_fragmentchecks the MF (More Fragments) flag and the fragment offset in the IP header. If set, the packet is a fragment.ip_defragstores it in the fragment queue and returns non-zero until the last fragment arrives and the full datagram can be reassembled into a singleskb. Only then does execution continue past this block. -
NF_INET_LOCAL_INhook — a second Netfilter traversal. This is whereiptables -t filter INPUTrules are evaluated. If all rules accept the packet,ip_local_deliver_finishis called.
5.4.ip_local_deliver_finish — protocol demultiplexing
ip_local_deliver_finish — protocol demultiplexing
ip_local_deliver_finish reads the protocol field from the IP header (e.g. IPPROTO_TCP = 6, IPPROTO_UDP = 17) and uses it as an index into inet_protos[], a global array of struct net_protocol pointers populated during inet_init (via inet_add_protocol). It then calls ipprot->handler(skb), which for TCP is tcp_v4_rcv and for UDP is udp_rcv.
This is the hand-off point between the IP layer and the transport layer.
6.Full Call Chain
Full Call Chain
The full path from packet arrival to user-space delivery is:
7.References
References
- 張彥飛, 深入理解 Linux 網絡, Broadview