







1.Introduction
Introduction
1.1.Overview
Overview
When we deal with thousands of concurrent connections we need a mechanism that avoids scanning every file descriptor one by one. epoll is among one of the the answers in Linux to this problem. It creates a kernel object that tracks sockets on our behalf and notifies us only when something interesting happens, so we never waste CPU cycles polling idle connections.
epoll is not the only way to achieve single I/O multiplexing, interested reader can read section 〈7.2. Alternatives to epoll〉 for more detail.
In this article we will be understanding what happens to the follwing calls in kernel level:
epoll_createepoll_ctlandepoll_wait
Let's start from a heuristic example on the logical order of how they are called:
1.2.Objective
Objective
This article aims at understanding every component in the following diagram:
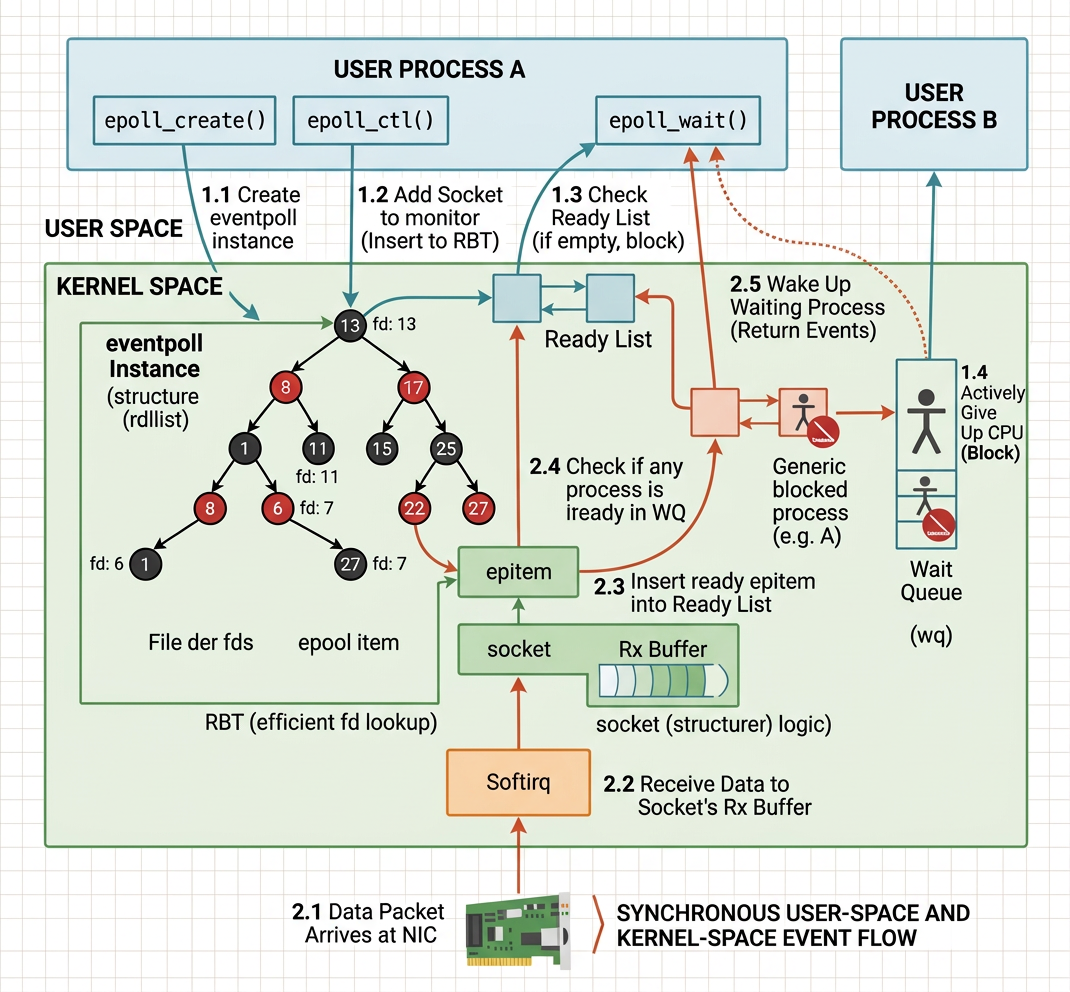
This essentially captured every single detail how an eventpoll object (also called epoll object informally) works in a high level.
2.The eventpoll Struct
The eventpoll Struct
When we call epoll_create, the kernel invokes
in fs/eventpoll.c.
Inside this system call the kernel allocates an eventpoll struct via ep_alloc. This struct is the heart of the whole mechanism:
Three fields deserve special attention:
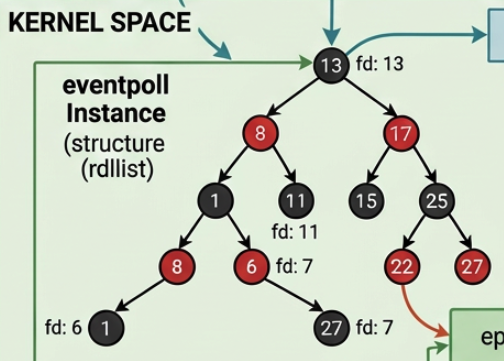
2.1.struct list_head rdllist — The Ready List
struct list_head rdllist — The Ready List
-
rdlliststands for ready list. It is a doubly-linked list that holds every file descriptor whose socket currently has a pending event. -
When a soft-interrupt delivers data to a socket, the kernel moves that socket's
epitemonto this list. -
When we later call
epoll_wait, the kernel checksrdllistfirst. If it is non-empty, it simply walks the list and copies events to userspace without scanning every registered fd. If it is empty, there is nothing ready yet and the process is put to sleep onep->wquntilep_poll_callbackfires and adds an item tordllist.
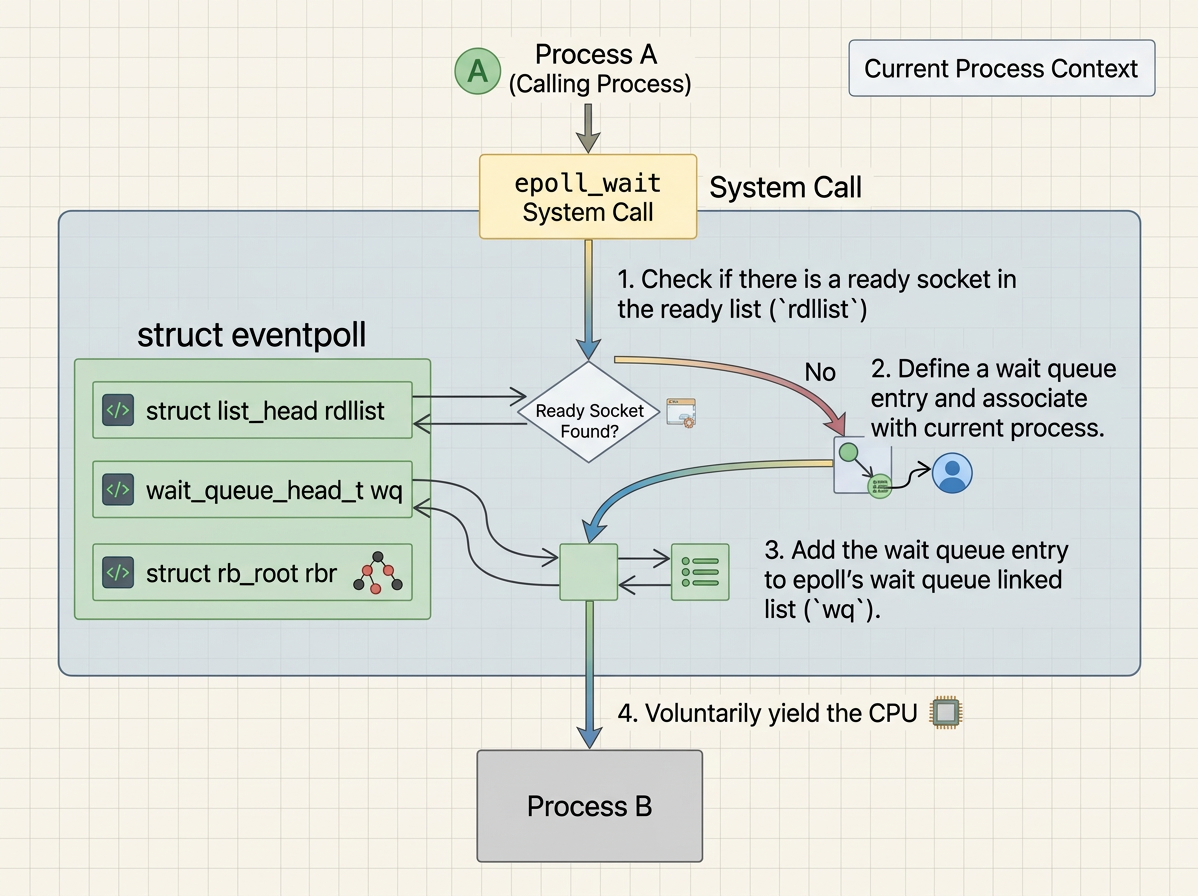
2.2.wait_queue_head_t wq — The Epoll Wait Queue
wait_queue_head_t wq — The Epoll Wait Queue
The purpose of wq is to bridge two sides of the kernel that cannot directly see each other. The interrupt handler that fires ep_poll_callback only has a pointer to the eventpoll struct — it has no knowledge of which process, if any, is waiting for events.
-
wqis the meeting point: whenrdllistis empty, the calling process adds a wait queue entry containing a pointer to its owntask_struct(current) intowq, then callsschedule()to go to sleep. When an NIC interrupt later firesep_poll_callback, that function walkswq, finds the entry, and puts the sleeping process back on the CPU run queue. In short,rdllistholds ready events whilewqholds sleeping callers — they are the two halves of a producer-consumer handshake across the kernel/interrupt boundary. -
wqis used bysys_epoll_wait. When a process callsepoll_waitand there is nothing onrdllist, the process is put to sleep on this wait queue. -
Later, when a soft-interrupt fires
ep_poll_callbackfor any socket, the callback first adds theepitemtordllist, then checks whetherwqhas any sleepers viawaitqueue_active(&ep->wq). If so, it callswake_upto resume them. The woken process then walksrdllistinsideepoll_waitand copies the ready events to userspace. If nobody has calledepoll_waityet,wqis empty and the wakeup is simply skipped.
The simplified flow inside ep_poll (the internal implementation of epoll_wait) is:
So wq has a sleeper in exactly one situation: our process called epoll_wait but rdllist was empty at that instant, so the kernel had nothing to return yet. Rather than spinning, it puts our process to sleep on ep->wq and schedules something else on the CPU. When any registered socket later receives data, ep_poll_callback wakes wq and our process resumes. If rdllist is already non-empty when we call epoll_wait, we never sleep on wq at all — the events are copied and returned immediately.
2.3.struct rb_root_cached rbr
struct rb_root_cached rbr
2.3.1.What Does rbr Store?
What Does rbr Store?
rbr is a red-black tree (detailed in 〈2.3.2. A Brief Introduction to Red-Black Tree〉 below) that stores every epitem we registered via epoll_ctl. Each node in the tree is keyed by (file *, fd), which lets the kernel quickly look up, insert, or remove any socket from the epoll instance. This is the structure that manages the mapping between our process's watched sockets and their corresponding epitem nodes.
2.3.2.A Brief Introduction to Red-Black Tree
A Brief Introduction to Red-Black Tree
A red-black tree is a self-balancing binary search tree (紅黑樹 in Chinese). Every node is coloured either red or black, and the tree enforces a set of invariants:
- Every node is red or black.
- The root is black.
- Every leaf (NIL) is black.
- If a node is red, both its children are black.
- For each node, all simple paths from that node to descendant leaves contain the same number of black nodes.
These rules guarantee that the longest path from root to leaf is at most twice the shortest path, giving us time for search, insertion, and deletion. The kernel uses this tree rather than a hash table for epoll because:
- It provides worst-case for insertion, deletion, and lookup, with no risk of hash collision degradation.
- It uses no extra pre-allocated bucket array, so memory consumption scales linearly with the number of registered fds.
- It keeps entries in sorted order by
(file *, fd), which makes range-based lookups and ordered traversal straightforward.
In short, a red-black tree balances the needs for fast query, fast insertion, and predictable memory usage.
3.epoll_ctl
epoll_ctl
3.1.Register a Socket
Register a Socket
Assume we already have a socket and an epoll instance. When we call epoll_ctl to register the socket, the kernel does three things:
Task 1. Allocates an epitem node for that socket.
Task 2. Adds an entry to the socket's wait queue, with callback ep_poll_callback.
We will discuss this "wait entry" in section 〈4.5.2. ep_ptable_queue_proc — Creating the Wait Entry〉.
Task 3. Inserts the epitem into the epoll's red-black tree.
We will discuss epitem in section 〈4.1. The epitem Struct〉.
3.2.The epoll_ctl System Call Interface
The epoll_ctl System Call Interface
The four arguments are:
epfd— the file descriptor of the epoll instance (returned byepoll_create).op— the operation:EPOLL_CTL_ADD,EPOLL_CTL_MOD, orEPOLL_CTL_DEL.fd— the target file descriptor (the socket we want to watch).event— a pointer to a userspaceepoll_eventstruct describing which events to watch (e.g.,EPOLLIN,EPOLLOUT).
Inside the switch(op) block, the EPOLL_CTL_ADD case calls ep_insert, which is the function that wires everything together.
4.ep_insert — Wiring a Socket into Epoll
ep_insert — Wiring a Socket into Epoll
ep_insert lives in fs/eventpoll.c and carries out several tasks in sequence. We focus on the most important ones.
4.1.The epitem Struct
The epitem Struct
For each socket registered via epoll_ctl, an epitem is allocated. Its full structure:
Key fields include:
rbn— the red-black tree node, used to locate this item inep->rbr.rdllink— the link used to chain this item ontoep->rdllistwhen events are ready.ffd— the(file *, fd)pair identifying which socket this item tracks.ep— a back-pointer to the parenteventpoll.event— the event mask the user registered (e.g.,EPOLLIN).
4.2.Task 1: Link epitem to the Epoll Instance and the Socket
Task 1: Link epitem to the Epoll Instance and the Socket
Inside ep_insert, the line
sets the back-pointer so that when a callback fires on this item, the kernel knows which eventpoll instance to wake. This is essential because callbacks originate from the socket layer and need a path back to the epoll object.
Next, ep_set_ffd fills in epi->ffd:
We need this because the red-black tree is keyed by (file *, fd). Without storing the socket's file pointer and its fd number inside the epitem, the kernel would have no way to locate or compare nodes in the tree. ep_set_ffd simply copies these two values into the epitem's ffd field.
4.3.Task 2: Register a Callback on the Socket's Wait Queue
Task 2: Register a Callback on the Socket's Wait Queue
The second task of ep_insert is to place the socket onto a waiting queue so that the kernel can notify epoll when data arrives. This is accomplished through init_poll_funcptr and ep_item_poll.
The purpose of ep_item_poll is to set ep_poll_callback as the function to invoke when the socket becomes ready. Its implementation calls into the socket's file operations:
vfs_poll eventually calls file->f_op->poll, which for sockets resolves to sock_poll.
4.4.sock_poll and tcp_poll
sock_poll and tcp_poll
sock_poll is the poll handler for socket file descriptors. It delegates to the protocol-specific poll function. For TCP sockets this means tcp_poll:
Inside tcp_poll, the call sock_poll_wait retrieves the socket's wait queue via sk_sleep(sk). This returns the wait_queue_head_t associated with the socket. Our waiting entry is about to be inserted into this queue.
4.5.sock_poll_wait — Connecting the Dots
sock_poll_wait — Connecting the Dots
sock_poll_wait invokes the qproc callback pointer that was previously set by init_poll_funcptr. Back in ep_insert, we called:
Let's explain
init_poll_funcptrin 〈4.5.1.init_poll_funcptr〉 andep_ptable_queue_procin 〈4.5.2.ep_ptable_queue_proc— Creating the Wait Entry〉
4.5.1.init_poll_funcptr
init_poll_funcptr
The implementation is straightforward:
It stores the callback function pointer and sets the key to match all events.
4.5.2.ep_ptable_queue_proc — Creating the Wait Entry
ep_ptable_queue_proc — Creating the Wait Entry
The wait entry added to the wait queue of the socket is an eppoll_entry struct:
wait— await_queue_entry_twithfunc = ep_poll_callback. This is the node that gets linked into the socket's wait queue list.base— a pointer back to theepitem, so the callback knows which fd became ready.whead— a pointer to the socket's wait queue head, used for cleanup when the fd is later removed from epoll.
The socket itself has no knowledge of epoll. It simply walks its wait queue and calls the func of each entry, which in this case happens to be ep_poll_callback.
It is worth contrasting this with the entries that live in ep->wq:
| Wait queue | Entry func | Entry private | Purpose |
|---|---|---|---|
Socket's sk->sk_wq | ep_poll_callback | NULL | Notify epoll when a socket event fires |
ep->wq | default wake function | current (task_struct *) | Wake the sleeping epoll_wait caller |
This is the function that actually creates a new wait queue entry for our socket and wires it up with the epoll callback. We focus on the two key operations:
The two critical calls are:
-
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback)— initializes the wait queue entry. Unlikerecvfromwhich setsq->private = current(the calling process), hereq->privateis set toNULL. We do not need to record which process to wake at this level because that responsibility belongs to theeventpollobject's ownwq. The important part isq->func = func, which sets the wake function toep_poll_callback. Later, when a soft-interrupt delivers data to the socket and wakes its wait queue,ep_poll_callbackis the function that gets called. -
add_wait_queue(whead, &pwq->wait)— inserts the wait entry into the socket's wait queue. From this moment on, any event on the socket will triggerep_poll_callback.
When the soft-interrupt fires (e.g., after the NIC receives a packet and the kernel processes it), it walks the socket's wait queue and invokes ep_poll_callback. This callback then places the corresponding epitem onto rdllist and wakes any process sleeping in epoll_wait.
4.6.Task 3: Insert epitem into the Red-Black Tree
Task 3: Insert epitem into the Red-Black Tree
After the callback is registered, ep_insert calls ep_rbtree_insert to add the epitem into ep->rbr. The red-black tree is keyed by the (file *, fd) pair stored in epi->ffd, so future lookups (for EPOLL_CTL_MOD, EPOLL_CTL_DEL, or duplicate checks on EPOLL_CTL_ADD) are .
Using a red-black tree instead of a hash table is a deliberate choice. A hash table can degrade to in the worst case due to collisions and requires a pre-sized bucket array that wastes memory when the number of fds is small. A red-black tree guarantees for all operations regardless of input distribution, uses memory proportional to the number of items, and avoids the need for rehashing when the set grows.
5.When a Socket Receives Data — The Wakeup Path
When a Socket Receives Data — The Wakeup Path
Once epoll_wait has put the process to sleep on ep->wq and all the eppoll_entry hooks are in place on every socket's wait queue, the remaining question is: what exactly happens when a packet arrives and wakes everything up?
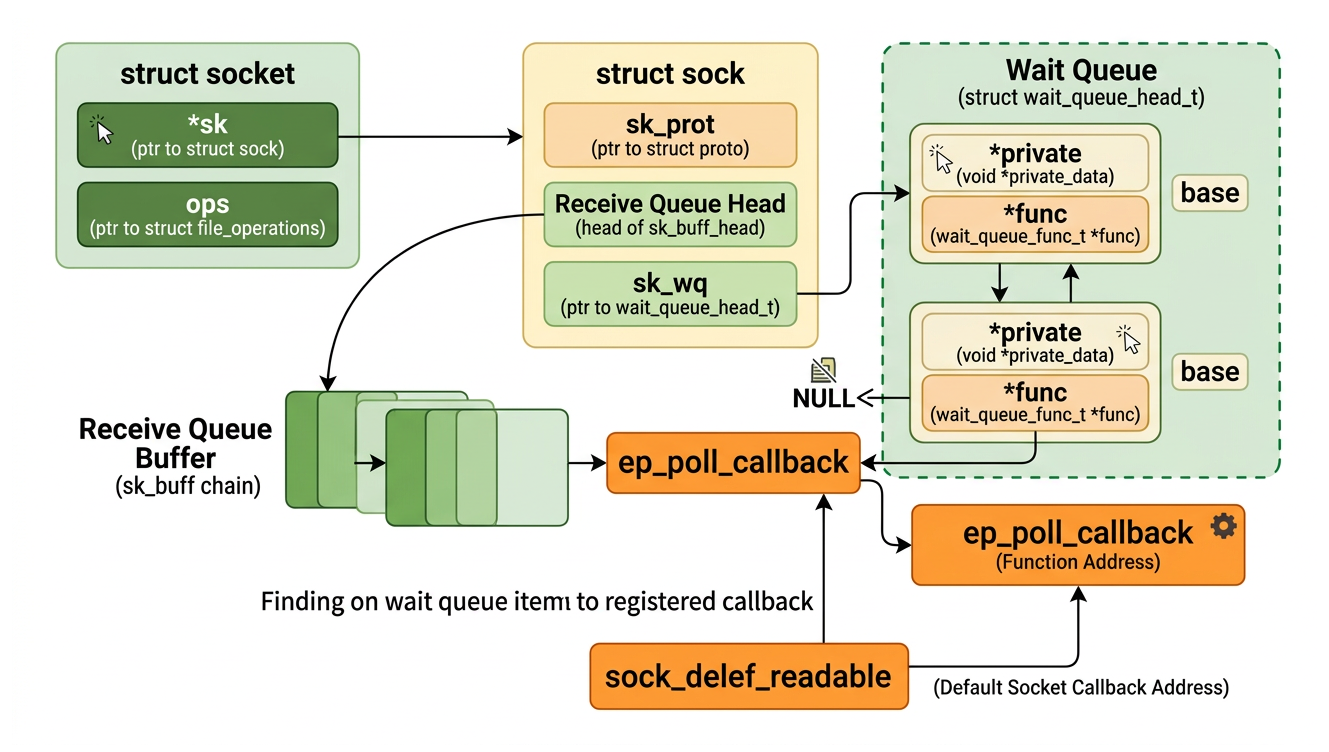
5.1.Recall the Diagram of a socket Struct
Recall the Diagram of a socket Struct
We have intensive study of struct socket and struct sock in
Let's recall the following:
5.2.Step 1: NIC Receives a Packet and Copies It into an sk_buff
Step 1: NIC Receives a Packet and Copies It into an sk_buff
When a network packet arrives, the NIC performs a DMA transfer directly into a kernel memory buffer. The kernel wraps this buffer in an sk_buff (socket buffer, commonly abbreviated skb) — a struct that carries the raw packet data along with protocol metadata (lengths, pointers to headers, etc.) as it travels up the network stack. Ownership of the skb is passed from the NIC driver to the network stack via a soft-interrupt (NET_RX_SOFTIRQ).
The network stack processes the skb layer by layer (Ethernet → IP → TCP). At the TCP layer, the payload is placed into the socket's receive buffer — a ring buffer attached to struct sock. At this point the data is in kernel memory associated with the specific sock, waiting to be read by userspace.
5.3.Step 2: TCP Wakes the Socket's Wait Queue
Step 2: TCP Wakes the Socket's Wait Queue
After copying the data into the socket's receive buffer, the TCP layer calls sk->sk_data_ready(sk), which for most TCP sockets resolves to sock_def_readable. This function walks the socket's wait queue (sk->sk_wq) and calls the func of every entry in it.
Because ep_ptable_queue_proc previously inserted an eppoll_entry with func = ep_poll_callback into that wait queue, ep_poll_callback is now invoked.
5.4.Step 3: ep_poll_callback Adds the epitem to rdllist
Step 3: ep_poll_callback Adds the epitem to rdllist
ep_poll_callback is the central link between the socket world and the epoll world. Its simplified logic is:
Two things happen here:
-
list_add_tail(&epi->rdllink, &ep->rdllist)— theepitemfor this socket is appended toep->rdllist. If multiple sockets fire before the process wakes up, each one appends its ownepitemto the same list, so nothing is lost. -
wake_up_locked(&ep->wq)— if a process is sleeping onep->wq(i.e., it calledepoll_waitand found nothing ready), it is now markedTASK_RUNNINGand placed back on the CPU run queue. The kernel scheduler will resume it at the next opportunity.
5.5.Step 4: The Process Resumes and Drains rdllist
Step 4: The Process Resumes and Drains rdllist
When the process is scheduled back onto the CPU, it returns from schedule() inside ep_poll. It then locks ep->rdllist, iterates over every epitem on the list, copies the corresponding epoll_event to userspace, and removes the item from the list. The number of events copied is bounded by the maxevents argument passed to epoll_wait.
The full round-trip — from a packet arriving at the NIC to the process waking and reading from rdllist — involves exactly two context switches for the epoll_wait caller, regardless of how many sockets fired during the sleep.
6.Summary
Summary
6.1.What Is a Context Switch?
What Is a Context Switch?
A context switch is what the kernel does when it stops running one process and resumes another. At the mechanical level it is cheap — the kernel saves the current process's CPU registers (instruction pointer, stack pointer, general-purpose registers, etc.) into its task_struct, then restores the saved registers of the next process. From that moment on the CPU is executing a completely different program.
The real cost is not the register save/restore itself, which takes only a few hundred nanoseconds. The real cost is the cold cache that follows. While the old process was running, the CPU's L1 and L2 caches were filled with that process's working set — its stack frames, hot data structures, frequently accessed code. When the new process starts, it needs entirely different data, so almost every memory access is a cache miss that must be satisfied from L3 or main RAM. A RAM (re)fetch takes roughly 60–100 ns compared to roughly 1 ns for an L1 hit — a factor of ~100. For a server handling thousands of connections, paying this penalty per connection per I/O event adds up quickly.
| Memory level | Approximate latency |
|---|---|
| L1 cache | ~1 ns |
| L2 cache | ~4 ns |
| L3 cache | ~10–20 ns |
| Main RAM | ~60–100 ns |
Each sleep/wake cycle of a thread is exactly one context switch out (process goes to sleep → scheduler picks another) and one context switch in (data arrives → scheduler resumes the thread). That is 2 context switches per sleep/wake cycle, each carrying a cold-cache penalty.
6.2.Why epoll Is Efficient
Why epoll Is Efficient
The efficiency of epoll comes down to how it handles sleeping and waking relative to the number of connections.
With the traditional blocking IO model — one thread per connection — each thread blocks on its own socket. When data arrives on any connection, that thread's sleep/wake cycle fires independently. With connections all receiving data simultaneously, the kernel performs context switches (one to sleep, one to wake per thread), and each woken thread starts with a cold CPU cache.
epoll replaces this with a single thread that calls epoll_wait in a loop. Inside epoll_wait, the kernel checks rdllist (the ready list):
-
If
rdllistis non-empty. There are already sockets with pending events. The kernel returns them immediately without sleeping at all. -
If
rdllistis empty. The thread sleeps once onep->wq. While it sleeps, any number of sockets can fire: each NIC interrupt runsep_poll_callback, which appends the socket'sepitemtordllistwithout waking the thread yet.The thread is woken only once, after which it loops over the entire
rdllistin a single pass and collects all ready events.
The result is that epoll_wait incurs at most 2 context switches per call — regardless of how many connections have data. Where blocking IO pays context switches for active connections, epoll amortizes that cost across the entire batch of ready connections.
7.Appendix
Appendix
7.1.What is SYSCALL_DEFINEn in Linux?
What is SYSCALL_DEFINEn in Linux?
The number n in SYSCALL_DEFINEn counts the number of arguments, not the number of comma-separated tokens. The macro uses comma-separated type, name pairs, so int, flags is a single argument whose type is int and whose name is flags.
The reason type and name are split into separate macro tokens (instead of writing int flags as one parameter) is so the macro can extract each type individually, cast the raw register value to long, and then back to the declared type — this is what provides the sign-extension safety that prevents bugs like CVE-2009-0029 on 64-bit kernels.
More broadly, SYSCALL_DEFINEn exists to maintain a set of invariants that every system call in the kernel must obey. By funnelling every syscall through one macro family, the kernel guarantees these properties structurally, namely, a new syscall cannot accidentally skip them because the macro enforces them for the author:
- ABI (Application Binary Interface) safety. Every argument is sign-extended to
longbefore the real function body runs, preventing garbage in the upper 32 bits of a 64-bit register when userspace passes a narrower type. - Uniform tracing metadata. The macro emits
__syscall_meta_*structs and ftrace/perf tracepoints automatically, so every syscall is observable without any per-author wiring. - Compat-layer consistency. On kernels that support 32-bit userspace on a 64-bit host, the macro generates matching compat stubs with the same argument layout rules.
This is the same philosophy behind other kernel abstractions like container_of or the red-black tree API: encode the invariant once in a macro or helper so that individual call sites cannot violate it.
7.2.Alternatives to epoll
Alternatives to epoll
Alternatives of epoll includes select and poll for single I/O multiplexing with very concret code implementation demonstrating how they are used by creating a simple socket server (code repositories included). Interested reader can read:
7.3.Level-Triggered vs Edge-Triggered Mode
Level-Triggered vs Edge-Triggered Mode
Both modes use exactly the same ep_poll_callback / rdllist / wq machinery described in this article. The difference is a policy applied on top of it: under what condition is the epitem kept on (or re-added to) rdllist?
The shared mechanic: removal then conditional re-queue. When epoll_wait returns events to userspace, it always removes every reported epitem from rdllist — in both LT and ET mode. The difference comes immediately after:
- LT. The kernel re-checks the socket; if data still remains in the receive buffer, the
epitemis re-queued back ontordllistbefore the nextepoll_waitcall. - ET. No such re-check happens — the
epitemstays offrdllistuntilep_poll_callbackfires again because a new packet arrives andsk_data_readyis called.
This is why partial reads are prone to error under ET: the epitem has already been removed from rdllist, and without a new packet triggering ep_poll_callback, it will never be re-added.
The mode is set per-fd when calling epoll_ctl via the events field:
7.3.1.Level-Triggered (LT), The Default
Level-Triggered (LT), The Default
epoll_wait re-reports an fd on every call as long as its socket receive buffer still has unread data. After returning a ready event, the kernel checks the socket again; if data remains, the epitem is re-queued onto rdllist for the next epoll_wait.
In short, LT has the following advantages:
- Its behaviour is similar to
selectandpoll. - It is safe and forgiving, even if you read only part of the data, you will be notified again in the next call.
- It is suitable for most servers where simplicity matters more than maximum throughput.
7.3.2.Edge-Triggered (ET)
Edge-Triggered (ET)
epoll_wait notifies an fd only once per new data arrival, i.e., only when ep_poll_callback fires because sk_data_ready was called (a state transition: buffer empty → non-empty).
If you read only some of the data and return to epoll_wait, the remaining data sits silently in the receive buffer and you will not be notified again until the next new packet arrives.
7.3.2.1.Requirements when using ET
Requirements when using ET
- The socket must be in non-blocking mode (
O_NONBLOCK). - On each event you must loop
recvuntil it returnsEAGAIN/EWOULDBLOCK, draining the buffer completely.
7.3.2.2.When to use ET
When to use ET
- High-performance servers (nginx, Redis) that need to minimise redundant
epoll_waitwakeups. - Multi-threaded dispatch with
EPOLLONESHOT— the fd is automatically disarmed after a single delivery, so exactly one thread handles it, then re-arms withepoll_ctl(EPOLL_CTL_MOD)when done. This prevents two threads from racing on the same fd under LT.
| Level-Triggered (LT) | Edge-Triggered (ET) | |
|---|---|---|
| Default? | Yes | No, opt-in with EPOLLET |
| Fires when | Data remains in buffer | New data arrives (sk_data_ready) |
| Partial read safe? | Yes, notified again | No — must drain until EAGAIN |
| Socket mode required | Blocking or non-blocking | Non-blocking (O_NONBLOCK) |
| Typical users | Simple servers | nginx, Redis, libuv |
8.References
References
- 張彥飛, 深入理解 Linux 網絡, Broadview