






1.Introduction
Introduction
HyperLogLog is a probabilistic data structure used to estimate the cardinality (number of distinct elements) of a set with very little memory. It does not store actual elements — instead, it uses a hash function and statistical properties of a Bernoulli process to approximate the count.
2.The Bernoulli Process Behind HyperLogLog
The Bernoulli Process Behind HyperLogLog
2.1.What is a Bernoulli Process?
What is a Bernoulli Process?
A Bernoulli process is a sequence of independent binary trials, each with probability of success (1) or failure (0) — like flipping a fair coin repeatedly.
The key property: the probability of seeing consecutive failures (leading zeros) before the first success is:
2.2.The Core Intuition
The Core Intuition
When we hash an element, the output is a binary string where each bit behaves like an independent fair coin flip. HyperLogLog counts the position of the leftmost 1-bit (i.e., the number of leading zeros + 1) in this hash.
For example:
2.3.Why Leading Zeros Estimate Cardinality?
Why Leading Zeros Estimate Cardinality?
If we observe a maximum of leading zeros across all hashed elements, the probability of that happening by chance is . This means we are likely to need to hash roughly distinct elements before hitting such a rare outcome.
Formally, if is the maximum number of leading zeros seen:
where is the estimated number of distinct elements.
2.4.Example
Example
Each element has a probability of producing leading zeros. So the expected number of elements we need to hash before seeing leading zeros for the first time is .
Conversely, after hashing distinct elements, the maximum leading zeros we have observed is expected to satisfy:
For example, with distinct users:
So we'd expect the maximum leading zeros across all hashed elements to be around 20. Plugging back in:
This is close to the actual count of 1,000,000 — computed using only a few kilobytes of memory regardless of input size.
2.5.From Single Estimate to HyperLogLog
From Single Estimate to HyperLogLog
2.5.1.Dangerous Single Estimate
Dangerous Single Estimate
A single estimate has dangerously high variance. Consider this failure case:
- We have distinct elements
- By pure bad luck, the very first element we just hashed happens to have 30 leading zeros
- Our estimate: , which is a times over-estimate from one unlucky hash
The solution is to not rely on a single global max. Instead, collect many independent estimates of and average them, then the outliers (exceptionally large value) cancel out. This special average is called harmonic mean.
2.5.2.Modification 1: Multiple Hash Functions, But ...
Modification 1: Multiple Hash Functions, But ...
This is used in older algorithms like Flajolet-Martin, 1985.
For each input we run independent hash functions on each element, producing independent values of . Average them.
The downside. We must compute hash functions per element, which is expensive.
2.5.3.Modification 2: Bit Splitting, The Final Choice
Modification 2: Bit Splitting, The Final Choice
This is used in HyperLogLog, Flajolet et al. 2007 (see 〈3. Reference〉).
We use a single hash function, but split its output into two parts:
- The first bits → register index (which slot to update)
- The remaining bits → count leading zeros in this part
For example, with we have registers (one for each 2-bit value: 00, 01, 10, 11). Say each hash output is 8 bits:
Each register keeps only the max leading zeros seen so far among elements routed to it:
The final estimate combines all 4 registers via harmonic mean — instead of one unreliable global max, we now have 4 independent estimates averaged together.
Each slot independently tracks its own maximum leading zeros. Since hash bits are statistically independent, the first bits are independent from the remaining bits — this is mathematically equivalent to running separate hash functions, but only requires one hash call per element.
With
registers, the variance from any single outlier is diluted across all independent estimates. HyperLogLog combines them using a harmonic mean, which is chosen because it is less sensitive to outliers (estimates that are extraordinarily larger) than arithmetic mean:
where is the max leading zeros in register , and is a bias correction constant. We discuss the detail of the multiplicative bias term in 〈2.6. The Bias Correction Constant 〉.
The formula of is derived as follows:
-
Each register sees roughly elements (spread evenly, since we assume the hash function is purely random). Its leading-zero count estimates the local count:
-
In slot (register) we approximately estimate the global cardinality by :
-
Take the harmonic mean of all per-register estimates :
So the first is from the harmonic mean formula ( values averaged), and the second is from scaling each register's local estimate up to a global one. then corrects the remaining systematic bias.
2.6.The Bias Correction Constant
The Bias Correction Constant
The raw harmonic mean estimator is systematically biased high. Rare large values of pull the estimate up more than common small values pull it down — an asymmetry arising from Jensen's inequality applied to the convex function .
Flajolet et al. derived the correction factor analytically by modelling the expected value of the raw estimator and solving:
This integral has no closed form, but can be evaluated numerically for each . The paper provides these hardcoded values:
| 16 | 0.673 |
| 32 | 0.697 |
| 64 | 0.709 |
| ≥ 128 |
For Redis ():
Redis simply embeds 0.7213... as a hardcoded constant in its C source code:
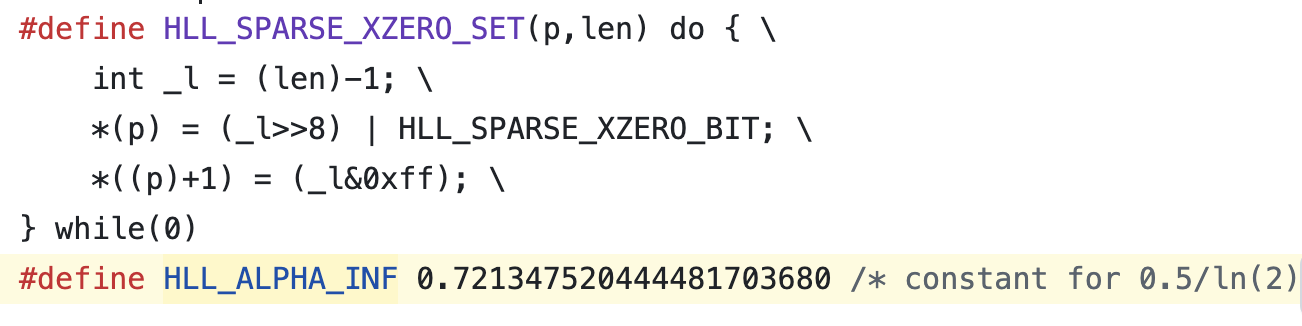
This factor is introduced in the paper [PEOF] listed in 〈3. Reference〉.
Redis uses , giving registers × 6 bits each = 12 KB of memory, with a standard error of only ~0.81%, regardless of whether we have 1,000 or 1,000,000,000 unique elements.
2.7.The Hash Function: MurmurHash2
The Hash Function: MurmurHash2
HyperLogLog doesn't need a specially constructed hash function — it just requires:
-
Uniform output. Each output bit is equally likely 0 or 1 (bits behave like independent coin flips)
-
Deterministic. Same input always produces the same output
Redis uses MurmurHash2 (64-bit variant), a fast non-cryptographic hash. The 64-bit output maps directly onto the bit-splitting scheme:
Why not SHA256 or MD5? They would work mathematically, but are far slower. HyperLogLog is called millions of times — cryptographic strength is unnecessary. MurmurHash is much faster while providing sufficient uniformity.
3.Reference
Reference