











1. Setting from Environment Variables
We convert all environment variables into public static fields of a class for type-safty.
To use dotenv, we need to install it via:
pip install python-dotenv
# src/config.py import os from dotenv import load_dotenv load_dotenv() class Settings: """Application settings loaded from environment variables""" DATABASE_URL: str = os.getenv( "DATABASE_URL", "postgresql://pguser:pguser@localhost:5432/pgdb" ) @classmethod def get_database_url_from_components(cls) -> str: """Build DATABASE_URL from individual environment variables""" host = os.getenv("DB_HOST", "localhost") port = os.getenv("DB_PORT", "5432") user = os.getenv("DB_USER", "pguser") password = os.getenv("DB_PASSWORD", "pguser") database = os.getenv("DB_NAME", "pgdb") return f"postgresql://{user}:{password}@{host}:{port}/{database}" DEBUG: bool = os.getenv("DEBUG", "false").lower() == "true" DB_POOL_SIZE: int = int(os.getenv("DB_POOL_SIZE", "5")) DB_MAX_OVERFLOW: int = int(os.getenv("DB_MAX_OVERFLOW", "10")) settings = Settings()
2. FastAPI and Uvicorn
2.1. Installation and Startup Script
We install by
pip install fastapi uvicorn
Now we create a main.py and write
# main.py from fastapi import FastAPI app = FastAPI( title="Medical API", description="API for managing doctors, clinics, and medical operations", version="1.0.0" ) @app.get("/") def read_root(): return {"message": "Welcome!"}
then we can spin up a web server locally by
uvicorn main:app --host 0.0.0.0 --port 8080 --reload
2.2. Routing
2.2.1. Router / Controller
In fastapi we don't have the concept of controllers (as in nodejs express). But we can mimic the idea by wrapping them into a class as follows:
1from fastapi import APIRouter, Depends 2from sqlalchemy.orm import Session 3... 4 5class DoctorController: 6 router = APIRouter( 7 prefix="/doctors", 8 tags=["doctors"] 9 )
Here we have created a public static attribute to DoctorController, which creates a router with which we can register a "route handler" by:
10 @router.get( 11 "/{doctor_id}", 12 response_model=ResponseDTO[List[OnDutyDoctorResponse]], 13 summary="Get all doctors with their assigned clinic centers", 14 ) 15 async def get_doctor_by_id( 16 doctor_id: int, 17 db: Session = Depends(get_db), 18 doctor_application_service = Depends(DoctorApplicationService) 19 ): 20 doctor_responses = doctor_application_service.get_doctors(db, doctor_id) 21 return ResponseDTO( 22 success=True, 23 result=doctor_responses 24 ) 25 26doctor_router = DoctorController.router
2.2.2. Typing in Swagger Docs via Pydantic
Swagger document is by defualt accessible via http://localhost:8080/docs.
Note that from the route definition:
@router.get( "/{doctor_id}", response_model=ResponseDTO[List[OnDutyDoctorResponse]], summary="Get all doctors with their assigned clinic centers", )
apart from the route /doctors/{doctor_id} we have also defined the following attributes for swagger document:
-
summaryThis is the brief introduction displayed in the swagger document

-
response_modelThis is a class extending
BaseModelfrompydantic, which provides us two functionalities infastapiframework:-
It provides a typing for
swaggerdocument -
It provides an automated conversion from class object into json format in controller response
For example I have defined a common response model
ResponseDTOas follows:from pydantic import BaseModel, Field from typing import TypeVar, Generic, List, Optional, T = TypeVar('T') class ResponseDTO(BaseModel, Generic[T]): success: bool result: T errorMessage: Optional[str] = Field(default=None, exclude=True) class Config: # Exclude None values from JSON output exclude_none = True class OnDutyDoctorResponse(BaseModel): id: int doctor_id: int doctor_name: Optional[str] price: float language: str category: str clinic_centers: ClinicCenterDTO center_phones: List[CenterPhoneDTO] center_workdays: List[CenterWorkdayDTO] discount: strHere all
ClinicCenterDTO,CenterPhoneDTOandCenterWorkdayDTOextend fromBaseModel, then we obtain a schema from the swagger document: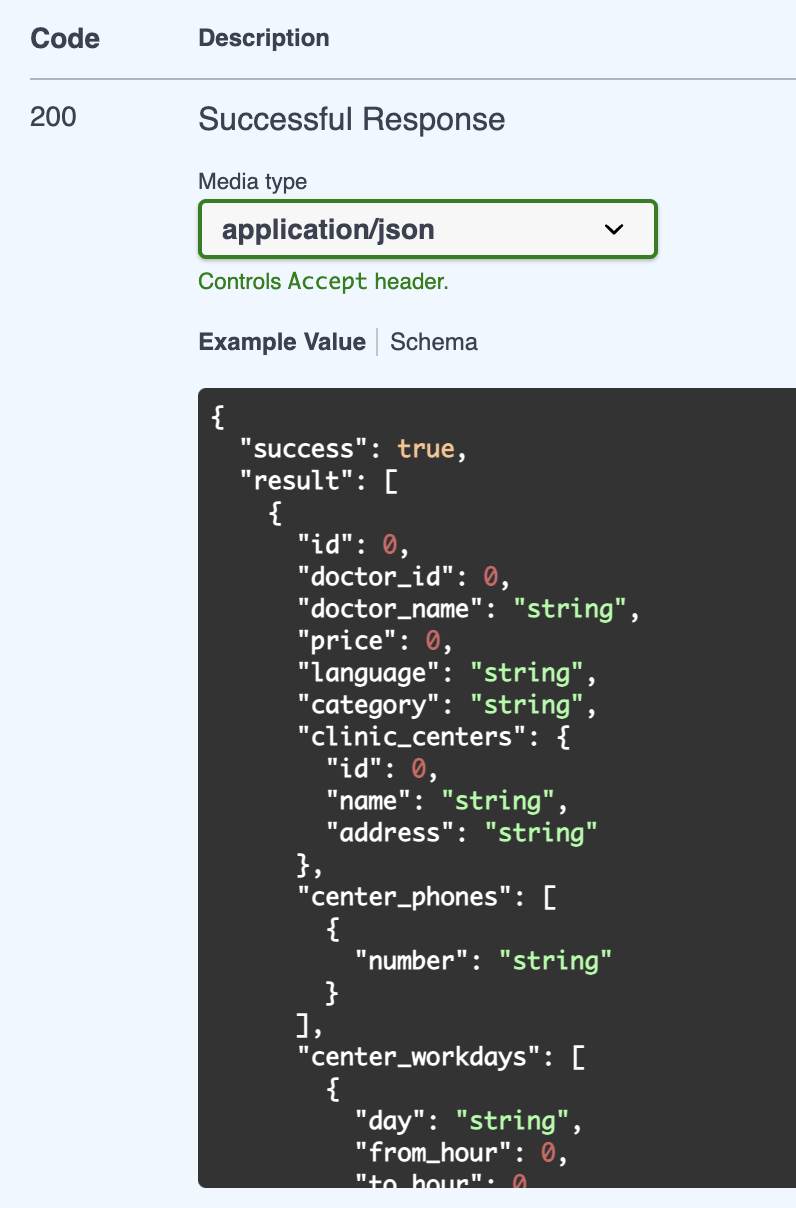
By returning this
BaseModelin a@router.getannotated method, the response is automatically transformed from class intojsonobject for the frontend. -
2.3. Register the Router
At the end of section 〈2.2.1. Router / Controller〉 we have defined
doctor_router = DoctorController.router
in src/controller/doctor_controller.py, now import it into main.py as follows:
from src.controller.doctor_controller import doctor_router app = FastAPI( title="Medical API", description="API for managing doctors, clinics, and medical operations", version="1.0.0" ) # Include the doctor controller router app.include_router(doctor_router)
2.4. Query Param
Consider the following method in a controller:
@router.get( "", response_model=ResponseDTO[List[OnDutyDoctorResponse]], summary="Get all doctors with their assigned clinic centers", ) async def get_doctors( district: Optional[str] = None, category: Optional[str] = None, price: Optional[int] = None, langauge: Optional[str] = None, db: Session = Depends(get_db), doctor_application_service: DoctorApplicationService = Depends(DoctorApplicationService) ): doctor_responses = doctor_application_service.get_doctors(db, district=district, category=category, price=price, langauge=langauge) return ResponseDTO( success=True, result=doctor_responses )
By default all positional arguments are query parameter:
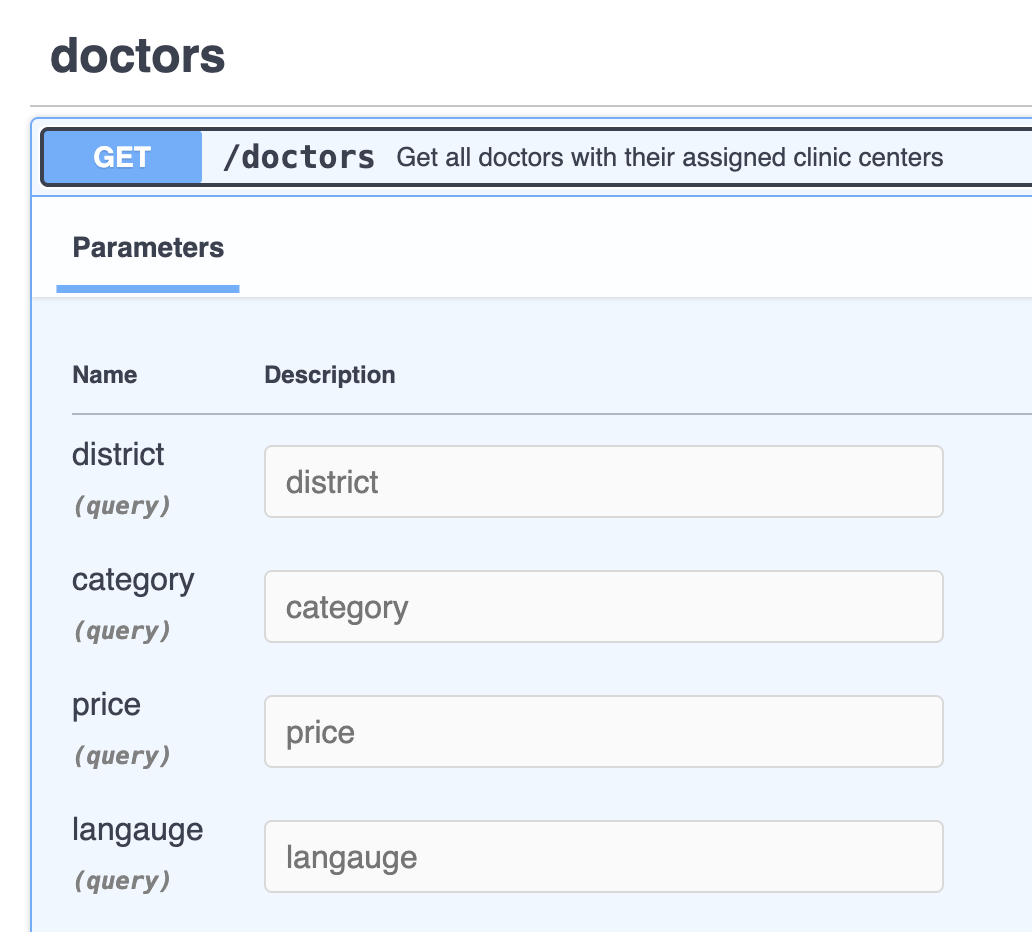
2.5. Path Variable
As in spring boot we indicate a path variable by curly braces {doctor_id}:
@router.get( "/{doctor_id}", response_model=ResponseDTO[List[OnDutyDoctorResponse]], summary="Get all doctors with their assigned clinic centers", ) async def get_doctor_by_id( doctor_id: int,
Then doctor_id in the arguments will be aumatically the path variable.
2.6. Dependency Injection
Depenency injection in fastapi is achieved by using
from fastapi import Depends
-
Dependency injection works only in method level, it cannot be used in the constructor level (so it cannot be defined once, and shared anywhere within the class).
-
Only method annotated by
@router.{get, post, put, delete, patch}can obtain a valid value fromDepends.
For exmaple:
@router.get("/{doctor_id}") async def get_doctor_by_id( doctor_id: int, db: Session = Depends(get_db), doctor_application_service = Depends(DoctorApplicationService) ): doctor_responses = doctor_application_service.get_doctors(db, doctor_id) return ResponseDTO( success=True, result=doctor_responses )
3. ORM: SqlAlchemy, a Counterpart of JPA in Spring Boot
3.1. Installation
pip install SQLAlchemy
3.2. Session Object (get_db generator)
Session object plays the same role as EntityManager in Spring Boot. We will do all the data retrival and persistence via this db: Session object.
Note that by default SqlAlchemy does not provide repository, we will need to build our own queries using db.query() method.
We have introduced how to dependency-inject a db Sesssion object in the previous session, its exact definition is as follows:
from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker from src.config import settings engine = create_engine( settings.DATABASE_URL, pool_size=settings.DB_POOL_SIZE, max_overflow=settings.DB_MAX_OVERFLOW ) SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine) def get_db(): db = SessionLocal() try: yield db finally: db.close()
3.3. Script to Reverse Engineer Existing Database into SqlAlchemy Entity Classes
-
This python script is vibe-coded and has been experimented successfully for complicated usecases.
-
It will reverse-engineer an existing database and convert all tables into entity classes (including foreign key relations) and save them into
src/model/reverse_engineered_entities/.
# scripts/generate_entities.py #!/usr/bin/env python3 import os import subprocess import sys from pathlib import Path # Add project root to path to import config project_root = Path(__file__).parent.parent sys.path.insert(0, str(project_root)) from src.config import settings def generate_entities(): """Generate SQLAlchemy models from database schema""" # Output directory and temp file output_dir = project_root / "src" / "model" / "reverse_engineered_entities" temp_file = project_root / "temp_entities.py" # Create output directory output_dir.mkdir(exist_ok=True) # Build sqlacodegen command to temp file first cmd = [ "sqlacodegen", f"postgresql+psycopg2://{settings.DATABASE_URL.replace('postgresql://', '')}", "--noinflect", # Generate relationships "--noviews", # Generate many-to-many through association tables "--noconstraints", # Don't generate constraint names "--outfile", str(temp_file) ] print(f"Generating entities from database...") print(f"Database URL: {settings.DATABASE_URL}") print(f"Output directory: {output_dir}") try: # Run sqlacodegen to temp file result = subprocess.run(cmd, check=True, capture_output=True, text=True) # Split the generated file into separate class files split_entities_into_files(temp_file, output_dir) # Clean up temp file temp_file.unlink() print("✅ Entities generated successfully!") print(f"📁 Check {output_dir}") except subprocess.CalledProcessError as e: print(f"❌ Error generating entities: {e}") if e.stderr: print(f"Error details: {e.stderr}") sys.exit(1) except FileNotFoundError: print("❌ sqlacodegen not found. Install it with: pip install sqlacodegen") sys.exit(1) def split_entities_into_files(temp_file, output_dir): """Split generated entities into separate files and add many-to-many relationships""" import re with open(temp_file, 'r') as f: content = f.read() # Extract imports section imports_match = re.search(r'^(.*?)(?=class|\Z)', content, re.DOTALL | re.MULTILINE) imports = imports_match.group(1).strip() if imports_match else "" # Add relationship import if not present if "from sqlalchemy.orm import relationship" not in imports: imports += "\nfrom sqlalchemy.orm import relationship" # Ensure ForeignKey is imported for relationship tables if "ForeignKey" not in imports: imports = imports.replace( "from sqlalchemy import", "from sqlalchemy import ForeignKey," ) # Find all class definitions - improved regex to handle multiline properly classes = re.findall(r'(class\s+(\w+).*?)(?=\nclass|\Z)', content, re.DOTALL) # Find association tables (tables that start with rel_ or have multiple foreign keys) association_tables = re.findall(r"(t_\w+|rel_\w+)\s*=\s*Table\([^)]+\)", content) # Detect many-to-many relationships from association tables many_to_many_relationships = detect_many_to_many_relationships(content) # Create __init__.py init_content = """# Auto-generated entities from database # Import all models to ensure they are registered with SQLAlchemy from .base import Base """ class_names = [] for class_content, class_name in classes: # Fix foreign key constraints for relationship tables fixed_class_content = fix_foreign_key_constraints(class_content, class_name) # Add many-to-many relationships to entity classes enhanced_class_content = add_many_to_many_relationships( fixed_class_content, class_name, many_to_many_relationships ) # Use shared base import instead of creating new Base enhanced_class_content = fix_base_import(enhanced_class_content) # Fix imports for individual files to use shared base fixed_imports = fix_imports_for_shared_base(imports) # Create individual file for each class file_content = f"""{fixed_imports} {enhanced_class_content.strip()} """ class_file = output_dir / f"{pascal_to_snake_case(class_name)}.py" with open(class_file, 'w') as f: f.write(file_content) class_names.append(class_name) print(f"📄 Created {class_file}") # Add imports to __init__.py (no __all__ needed, just for registration) for name in class_names: init_content += f"from .{pascal_to_snake_case(name)} import {name}\n" # Write __init__.py with open(output_dir / "__init__.py", 'w') as f: f.write(init_content) print(f"📄 Created {output_dir}/__init__.py") def snake_to_pascal_case(snake_str): """Convert snake_case to PascalCase (e.g., clinic_center -> ClinicCenter)""" return ''.join(word.capitalize() for word in snake_str.split('_')) def pascal_to_snake_case(pascal_str): """Convert PascalCase to snake_case (e.g., ClinicCenter -> clinic_center, OnDutyDoctor -> on_duty_doctor)""" import re # Insert underscores before uppercase letters (except the first one) # This handles cases like OnDutyDoctor -> on_duty_doctor snake = re.sub('([a-z0-9])([A-Z])', r'\1_\2', pascal_str) return snake.lower() def detect_many_to_many_relationships(content): """Detect many-to-many relationships from association tables""" import re relationships = {} # Get actual class names from the generated content actual_classes = re.findall(r'class\s+(\w+)\(Base\):', content) # Detect one-to-one association tables (usually have unique constraints) def is_one_to_one_table(table_name, content): # Look for unique constraints or unique indexes in the table definition table_pattern = rf"{table_name}.*?Column.*?unique=True" return bool(re.search(table_pattern, content, re.DOTALL | re.IGNORECASE)) # Create a mapping from table names to actual class names def find_actual_class_name(entity_name): # Try exact match first pascal_name = snake_to_pascal_case(entity_name) if pascal_name in actual_classes: return pascal_name # Try flexible matching (case insensitive) for cls in actual_classes: if cls.lower() == entity_name.lower().replace('_', ''): return cls # Fallback to pascal case return pascal_name # Find association table patterns like rel_ondutydoctor_centerphone association_pattern = r"rel_(\w+)_(\w+)" matches = re.findall(association_pattern, content) for match in matches: entity1, entity2 = match # Use actual class names from generated content class1 = find_actual_class_name(entity1) class2 = find_actual_class_name(entity2) table_name = f"rel_{entity1}_{entity2}" # Check if this is a one-to-one relationship is_one_to_one = is_one_to_one_table(table_name, content) # Convert entity names to proper snake_case for field names if is_one_to_one: # For one-to-one, use singular names field_name_1 = pascal_to_snake_case(class2) field_name_2 = pascal_to_snake_case(class1) else: # For many-to-many, use plural names with proper snake_case field_name_1 = pascal_to_snake_case(class2) + 's' field_name_2 = pascal_to_snake_case(class1) + 's' # Add bidirectional relationships if class1 not in relationships: relationships[class1] = [] if class2 not in relationships: relationships[class2] = [] relationships[class1].append({ 'target': class2, 'table': table_name, 'field_name': field_name_1, 'is_one_to_one': is_one_to_one }) relationships[class2].append({ 'target': class1, 'table': table_name, 'field_name': field_name_2, 'is_one_to_one': is_one_to_one }) return relationships def fix_foreign_key_constraints(class_content, class_name): """Add proper ForeignKey constraints to relationship tables""" import re # Only process relationship tables (tables that start with 'Rel' or contain foreign key patterns) if not (class_name.startswith('Rel') or '_id' in class_content): return class_content # Define foreign key mappings based on common patterns fk_mappings = { 'clinic_center_id': 'clinic_center.id', 'on_duty_doctor_id': 'on_duty_doctor.id', 'doctor_id': 'doctor.id', 'center_phone_id': 'center_phone.id', 'center_workday_id': 'center_workday.id' } # Find and replace foreign key column definitions for column_name, reference_table in fk_mappings.items(): # Pattern to match: column_name = Column(Integer, nullable=False) pattern = rf"({column_name}\s*=\s*Column\(Integer,)(\s*nullable=False\))" replacement = rf"\1 ForeignKey('{reference_table}'),\2" class_content = re.sub(pattern, replacement, class_content) return class_content def fix_imports_for_shared_base(imports): """Fix imports to use shared base and include ForeignKey""" import re # Remove declarative_base import imports = re.sub(r"from sqlalchemy\.ext\.declarative import declarative_base\n?", "", imports) # Remove any Base creation lines imports = re.sub(r"Base = declarative_base\(\)\n?", "", imports) imports = re.sub(r"metadata = Base\.metadata\n?", "", imports) # Add shared base import imports += "\nfrom .base import Base" # Ensure ForeignKey is in the SQLAlchemy imports if "ForeignKey" not in imports: imports = imports.replace( "from sqlalchemy import", "from sqlalchemy import ForeignKey," ) return imports def fix_base_import(class_content): """Remove any remaining Base creation from class content""" import re # Remove individual Base and metadata creation base_pattern = r"Base = declarative_base\(\)\nmetadata = Base\.metadata\n" class_content = re.sub(base_pattern, "", class_content) return class_content def add_many_to_many_relationships(class_content, class_name, relationships): """Add simplified many-to-many relationships to a class""" # Try to match class names more flexibly class_relationships = [] # Check direct match first if class_name in relationships: class_relationships = relationships[class_name] else: # Try lowercase comparison for flexible matching for key, rels in relationships.items(): if key.lower().replace('_', '') == class_name.lower().replace('_', ''): class_relationships = rels break if not class_relationships: return class_content # Add relationships before the class ends relationship_lines = [] for rel in class_relationships: # Convert back_populates to proper snake_case back_populates_name = f"{pascal_to_snake_case(class_name)}s" # Check if this is a one-to-one relationship uselist_param = "" relationship_type = "Many-to-many" if rel.get('is_one_to_one', False): uselist_param = ", uselist=False" relationship_type = "One-to-one" # Use simplified relationship definition (SQLAlchemy will infer join conditions from ForeignKeys) relationship_lines.append(f""" # {relationship_type} relationship through {rel['table']} {rel['field_name']} = relationship( "{rel['target']}", secondary="{rel['table']}", back_populates="{back_populates_name}"{uselist_param} )""") # Insert relationships before the last line of the class lines = class_content.strip().split('\n') relationships_text = '\n'.join(relationship_lines) # Add relationships at the end of the class enhanced_content = class_content.strip() + relationships_text return enhanced_content if __name__ == "__main__": generate_entities()
3.4. relationship()
3.4.1. On relationship defined in this section
In section 〈3.3. Script to Reverse Engineer Existing Database into SqlAlchemy Entity Classes〉 we have constructed a python script to reverse-engineered all the relations for us. This session is simply for better understanding of the sqlalchemy library.
3.4.2. One to one/many via direct foreign key
Suppose that an on_duty_doctor has one and only one center_discount in a table:
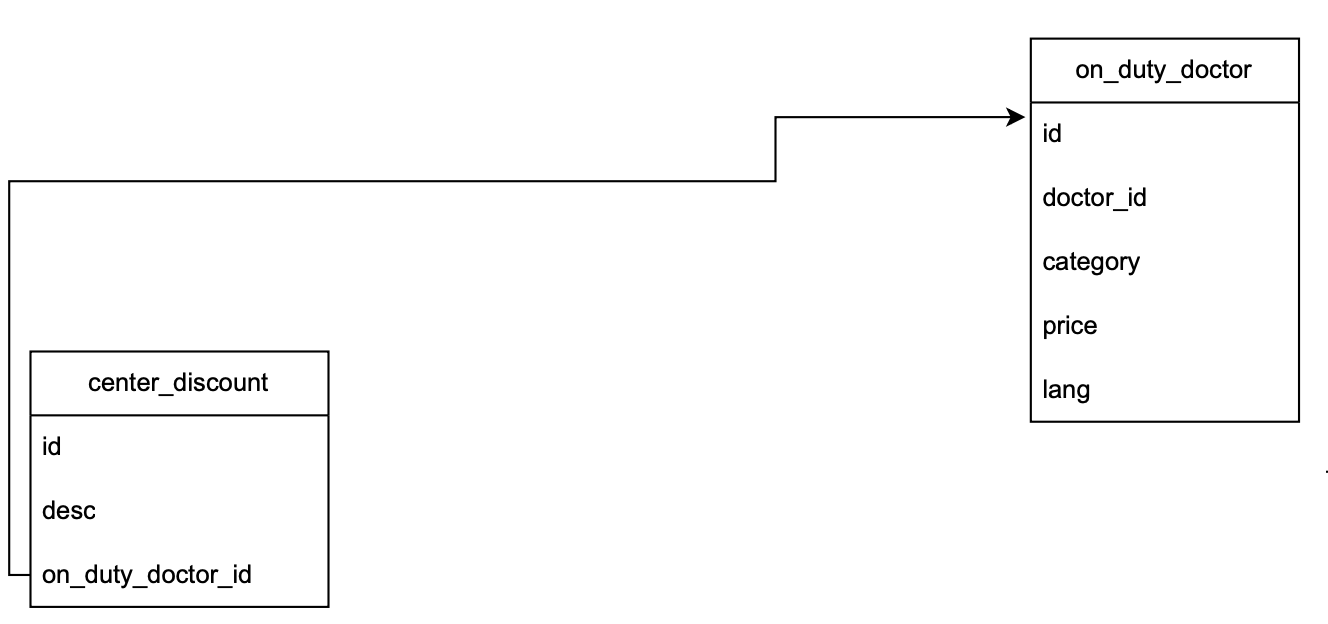
we can define it by
1class OnDutyDoctor(Base): 2 __tablename__ = 'on_duty_doctor' 3 4 id = Column(Integer, primary_key=True, server_default=text("nextval('on_duty_doctor_id_seq'::regclass)")) 5 6 center_discount = relationship( 7 "CenterDiscount", 8 back_populates="on_duty_doctor", 9 primaryjoin="OnDutyDoctor.id == CenterDiscount.on_duty_doctor_id", 10 uselist=False 11 ) 12 13class CenterDiscount(Base): 14 __tablename__ = 'center_discount' 15 16 id = Column(Integer, primary_key=True, server_default=text("nextval('center_discount_id_seq'::regclass)")) 17 on_duty_doctor_id = Column(Integer, ForeignKey('on_duty_doctor.id'), nullable=False) 18 19 on_duty_doctor = relationship("OnDutyDoctor", back_populates="center_discount")
-
In
relationshipwe use the class nameOnDutyDoctorto look for the class defining the tableon_duty_doctor. -
If we have the
ForeignKeyrelation defined, we can skipprimaryjoin.
3.4.3. One/Many to many via association table
Suppose that an on_duty_doctor has many center_workday's via an association table:
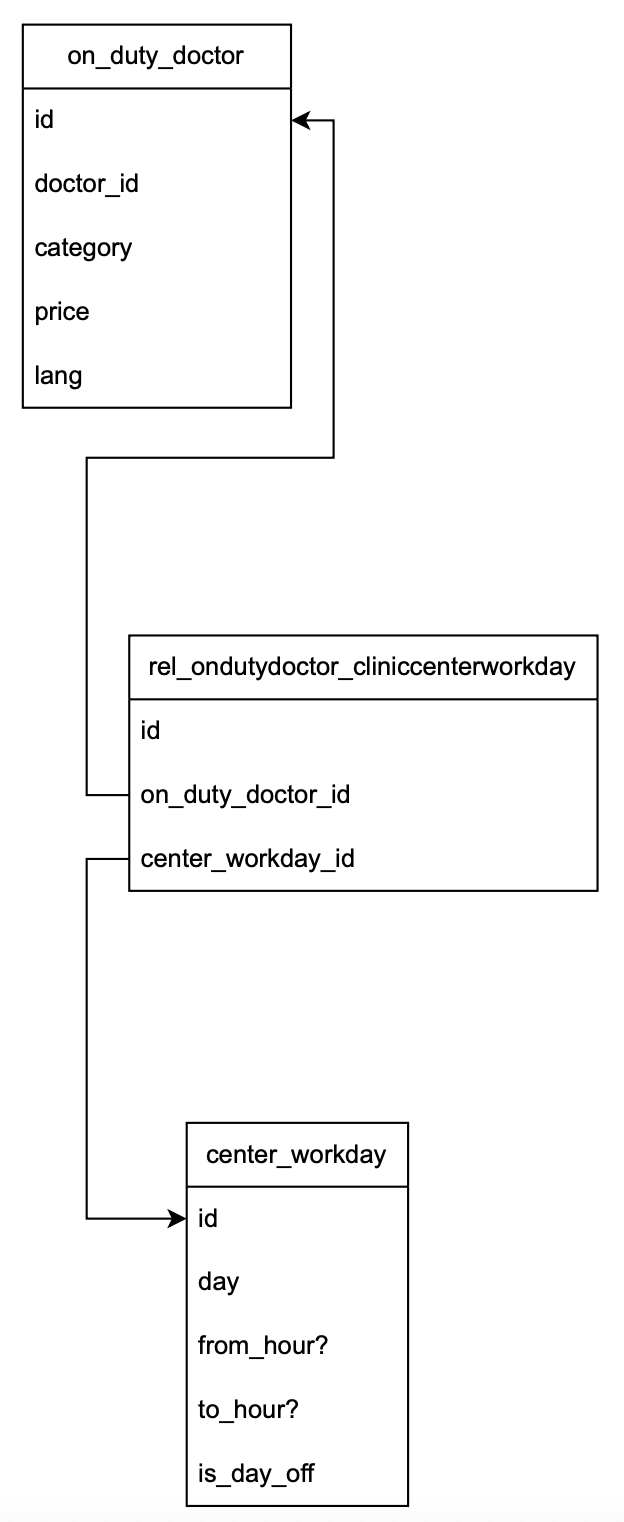
The association table is defined by
class RelOndutydoctorCenterworkday(Base): __tablename__ = 'rel_ondutydoctor_centerworkday' id = Column(Integer, primary_key=True, server_default=text("nextval('rel_ondutydoctor_centerworkday_id_seq'::regclass)")) on_duty_doctor_id = Column(Integer, ForeignKey('on_duty_doctor.id'), nullable=False) center_workday_id = Column(Integer, ForeignKey('center_workday.id'), nullable=False)
The associated entities can be defined by:
1class OnDutyDoctor(Base): 2 __tablename__ = 'on_duty_doctor' 3 4 id = Column(Integer, primary_key=True, server_default=text("nextval('on_duty_doctor_id_seq'::regclass)")) 5 6 center_workdays = relationship( 7 "CenterWorkday", 8 secondary="rel_ondutydoctor_centerworkday", 9 back_populates="on_duty_doctor" 10 ) 11 12class CenterWorkday(Base): 13 __tablename__ = 'center_workday' 14 15 id = Column(Integer, primary_key=True, server_default=text("nextval('center_workday_id_seq'::regclass)")) 16 17 on_duty_doctor = relationship( 18 "OnDutyDoctor", 19 secondary="rel_ondutydoctor_centerworkday", 20 back_populates="center_workdays", 21 uselist=True 22 )
-
Here we use
uselistto indicate whether we want anone(single object) ormany(list object) relation. -
Note that on line-18 we ask
sqlalchemyto associate entities usingOnDutyDoctorclass, which in turns associate toOnDutyDoctorusing the columnf"{OnDutyDoctor.__tablename__}_id"in the association table. Note that we have very strict naming convention to follow.
3.5. Various Query Methods
3.5.1. SELECT * from table WHERE ...;
The query
SELECT * From doctor WHERE doctor_id = 'some_doctor_id'
is equivalent to
db.query(Doctor).filter(Doctor.id == "some_doctor_id").{one, one_or_none, all}()
To see how to return data from left-joined column in a controller response, see the section 〈3.7. Conversion from Entity Class to BaseModel DTO〉 below.
3.5.2. LEFT JOIN and where clause on joined table
Unlike JPQL we can simply write
select d from Doctor d left join fetch d.on_duty_doctors odd left join fetch odd.clinic_centers center where center.address ilike concat('%', :address, '%')
in sqlalchemy we need to do the left join explicitly via the association table when we need to do conditional select clause via attributes of specific left-joined table:
query = db.query( Doctor ).join( OnDutyDoctor, OnDutyDoctor.doctor_id == Doctor.id ).join( RelCliniccenterOndutydoctor, RelCliniccenterOndutydoctor.on_duty_doctor_id == OnDutyDoctor.id ).join( ClinicCenter, ClinicCenter.id == RelCliniccenterOndutydoctor.clinic_center_id ) if district is not None: query = query.filter(ClinicCenter.address.ilike(f"%{district}%"))
If we don't need the filter (where) below, there is no need to do an explicit join.
3.5.3. Avoid $N+1$ Problem
As in left join fetch from JPA, the traditional problem can be solved by
from sqlalchemy.orm import joinedload query = db.query(OnDutyDoctor).options( joinedload(OnDutyDoctor.center_discount) )
This will make sure the center_discount table is eager-loaded and the subsequent access to center_discount will not cause an extra query for data-retrival.
3.6. Data Persistence via Dirty Checks
3.6.1. Persist New Entity
For new entity we can persist by
db = get_db() doctor = Doctor(name=doctor_data.name) db.add(doctor) db.commit() # if we throw error before commit, everything will be rollbacked db.refresh(doctor)
For new relation we can persist by
3.6.2. Persist New Entity and New Relation
doctor_on_duty = OnDutyDoctor(doctor_id=doctor_id, price=200, language=doctor_assignment_request.language.value, category=doctor_assignment_request.category.value) clinic_center.on_duty_doctors.append(doctor_on_duty) db.flush()
By default db.commit() will do db.flush() first, depending on when do we need to end the transaction. Sometimes a flush() is needed when we want to retrieve the id generated by our database.
For one-to-one and many-to-one (where uselist=False) the binding is the same:
doctor_on_duty.center_discount = center_discount db.flush()
3.7. Conversion from Entity Class to BaseModel DTO
As in JPA we cannot return the entity classes directly in the return of a controller. We need to transform all related attributes into pydantic.BaseModel classes.
Assume that our on_duty_doctor has a complete definition like:
class OnDutyDoctor(Base): __tablename__ = 'on_duty_doctor' id = Column(Integer, primary_key=True, server_default=text("nextval('on_duty_doctor_id_seq'::regclass)")) doctor_id = Column(Integer, ForeignKey('doctor.id'), nullable=False) price = Column(Integer, nullable=False) language = Column(Enum('ENGLISH', 'MANDARIN', 'CANTONESE', name='language'), nullable=False) category = Column(Enum('GENERAL', name='clinic_category'), nullable=False) doctor = relationship("Doctor", back_populates="on_duty_doctors") center_discount = relationship( "CenterDiscount", back_populates="on_duty_doctor", primaryjoin="OnDutyDoctor.id == CenterDiscount.on_duty_doctor_id", uselist=False ) clinic_centers = relationship( "ClinicCenter", secondary="rel_cliniccenter_ondutydoctor", back_populates="on_duty_doctors", uselist=False ) center_phones = relationship( "CenterPhone", secondary="rel_ondutydoctor_centerphone", back_populates="on_duty_doctors" ) center_workdays = relationship( "CenterWorkday", secondary="rel_ondutydoctor_centerworkday", back_populates="on_duty_doctors" )
Then to completely return an object with all associated entities we need to map every attribute one by one into BaseModel class:
1from typing import cast 2 3doctor_responses: List[OnDutyDoctorResponse] = [] 4 5for on_duty in cast(List[OnDutyDoctor], on_duty_doctors): 6 center = on_duty.clinic_centers 7 doctor_response = OnDutyDoctorResponse( 8 id=on_duty.id, 9 doctor_id=on_duty.doctor_id, 10 doctor_name=on_duty.doctor.name, 11 price=on_duty.price, 12 language=on_duty.language, 13 category=on_duty.category, 14 clinic_centers=ClinicCenterDTO(id=center.id, 15 name=center.name, 16 address=center.address), 17 center_phones=[CenterPhoneDTO(number=phone.number) for phone in on_duty.center_phones], 18 center_workdays=[ 19 CenterWorkdayDTO(day=workday.day, 20 from_hour=workday.from_hour, 21 to_hour=workday.to_hour, 22 is_day_off=workday.is_day_off) 23 for workday in on_duty.center_workdays], 24 discount=on_duty.center_discount.desc if on_duty.center_discount else "" 25 ) 26 doctor_responses.append(doctor_response) 27 28return doctor_responses
Consider line 19-23, we access associated entities via on_duty.center_workdays, and we map it into a list of pydantic entities using list comprehension.
Remark. By default sqlalchemy will generate a sql to retrieve the associated entities on_duty.center_workdays. With the help of joinedload (we have discussed it in Avoid Problem section) we can prevent this additional query to improve performance.
The is the same situation as if we are using left join fetch in JPQL.