Most of the documentation is more about how tauri is working under the hood, which is not of our interest if we just want to quickly build an app using this framework.
We start by executing
1yarn create tauri-app
then we can follow the CLI to create a project using React in Typescript.
4. About the Tauri Application
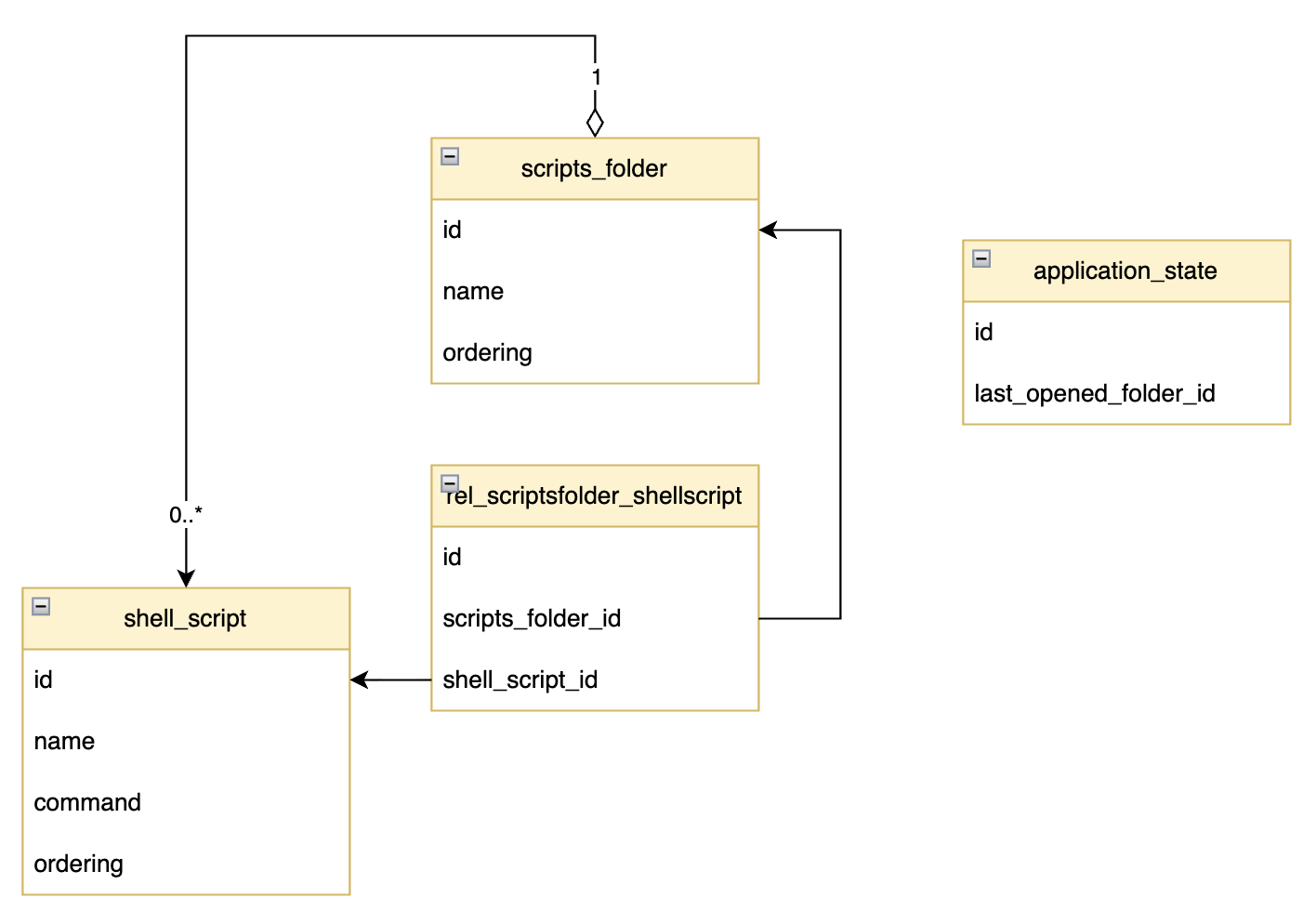
4.1. Class and Entity Relational Diagram (Combined)
We use redux-toolkit/rtk-query to manage our server (backend) state and use slices in redux-toolkit to manage our app state (like the selected folder, boolean to trigger UI animation, etc).
We also bring shadcn into the application as it provides us with customizable fancy components.
This backend is in charge of OS-level interaction bewteen our desktop application and the system.
For example, the menu bar, the tray icons, and even the permission to drag our custom title bar, etc, are configed in our Tauri backend.
It also handles commands sent from the frontend when there is system-level request from the frontend (e.g., I need to execute shell script displayed in the frontend).
4.2.3. The spring boot backend structure
1├── backend-spring/ # Spring Boot backend2│ ├── src/main/kotlin/
3│ │ └── com/scriptmanager/
4│ │ ├── controller/ # REST API endpoints5│ │ ├── common/
6│ │ │ ├── entity/ # JPA entities7│ │ │ └── dto/ # Data transfer objects8│ │ └── repository/ # Spring Data repositories9│ └── build.gradle.kts # Gradle build configuration
4.2.3.1. Tedious association table manipulation in Rust
This spring boot layer is previously a basic CRUD repository layer in Tauri backend. However, doing CRUD without good ORM in rust is very tedious, even with query builder it eventually looks:
Handling domain models is not the strength of rust, instead our good old friend JPA in Spring Boot shines in this area.
4.2.3.2. No more assocation manipulation in JPA with DDD
Therefore we add a new layer to handle state-related domain logic. We don't even need to write query when our @OneToMany and @ManyToOne are properly written:
Each request to a controller should have been handled by an application service layer (some may call it usecase in the dotnet community). For now since our application is in POC stage, the ugly pattern here will be refactored when our application grows.
Because of Spring Boot, now we can bring Domain Model and Value Object into the application, which is beneficial in maintaining the code base in the long run.
4.3. Communication between React Frontend and Tauri Backend
4.3.1. Dispatch command from React frontend
Suppose that I want to execute a command displayed in the frontend, we execute:
1import{ listen }from"@tauri-apps/api/event";23consthandleRun=async()=>{4try{5// Opens terminal and executes script6awaitinvoke("run_script",{ command: script.command});7}catch(error){8console.error("Failed to run script:", error);9}10};
This is because the popular serialization and deserialization crate in Rust serde expects the inputs to be in camal case, and it will automatically translate the variables into snake_case.
5. Schema Managment and LLM Tooling
5.1. Schema Definition
5.1.1. What LLM can do
For existing schema migration tools in spring boot ecosystem we mainly have
Flyway
Liquibase
Both require manual scripting for any changes in the database schema and make corresponding code changes in the entity model.
But with prisma we can focus on schema design, we benefit from this approach by now being able to:
Feed LLM model our clear schema definition;
Let LLM generate/modify our entity model in spring boot and;
Let prisma generate the script of database migration for the incremental update of the schema
5.1.2. Define schema and embed it into Rust script
Now our schema.prisma serves as a good documentation for LLM model of all of our tables:
As long as we understand what is the auto-generated sql migration script doing, it is no harm to let the framework generate it. We can even refine the sql to match what we need.
This will create an embedded SQL migration method in the prisma.rs file, and we can execute it to instantiate/update the database (see init_db below) in the startup script of our Tauri backend:
1modprisma;23pubfninit_db(app_handle:&tauri::AppHandle)->Result<(),String>{4let db_path =get_database_path(app_handle)?;5let database_url =format!("file:{}", db_path);6std::env::set_var("DATABASE_URL",&database_url);7let rt_handle =RT_HANDLE8.get()9.ok_or_else(||"Runtime not initialized".to_string())?;1011 rt_handle.block_on(asyncmove{12let client =prisma::new_client_with_url(&database_url)13.await14.expect("Failed to create Prisma client");15println!("Syncing database schema...");16 client
17._db_push()18.accept_data_loss()19.await20.expect("Failed to sync database schema");21...
5.3. Let LLM Generate Entity Classes from schema.prisma
Now simply ask our agent to generate the entity classes. For example:
Here we manually add the @ManyToOne annotations as well as the aggregate relations as LLM cannot easily understand it without knowing the class diagram (which we draw in section 〈4.1. Class and Entity Relational Diagram (Combined)〉).
6. Bundling of the Application with Spring Boot Integration
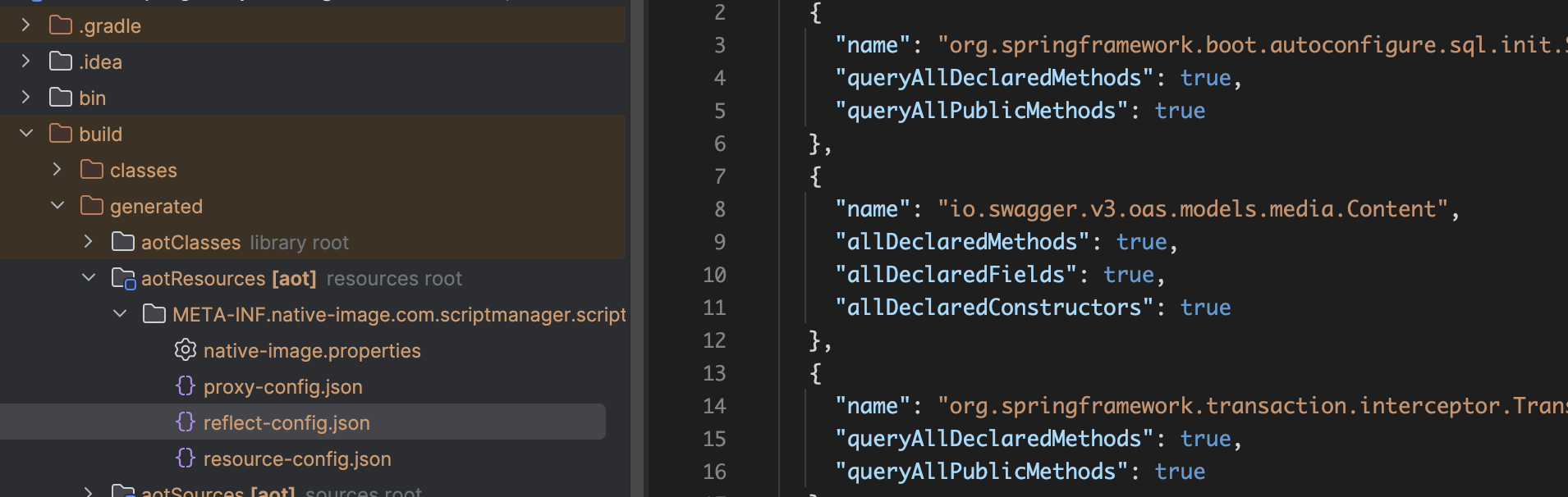
These are the external library that spring's (Ahead-of-Time) processing cannot see at compile time. By adding these classnames into reflect-config.json, we are telling GraalVM:
"Please include the actual compiled machine code for this class AND keep all the metadata needed for reflection"
6.3.2.2. What is already included in the native version of reflect-config.json?
Spring Boot's AOT (Ahead-of-Time) processing sees the annotations and generates reflection configuration automatically:
1@RestController // <--- Spring sees this annotation
2@RequestMapping("/scripts")3class ScriptController( // <--- Spring sees this class name directly!4 private val scriptRepository: ShellScriptRepository, // ← Direct reference!5 private val folderRepository: ScriptsFolderRepository // ← Direct reference!6){7 @GetMapping // <--- Spring sees this
8 fun getAllScripts(): ApiResponse<List<ShellScriptDTO>>{ // ← Direct return type!9 val list = scriptRepository.findAllByOrderByOrderingAsc().map { it.toDTO()}10return ApiResponse(list) // ← Direct class usage!11}12}
GraalVM can see the spring-managed reflect-config.json at compile time:
When combining two reflect-config.json's, we have registered: