











1. Setup Environment
We uv init and uv sync with the following pyproject.toml.
There is langgraph included but we can exclude them whenever we want because our implementation is direct application of agents imported from openai.
1[project] 2name = "app" 3version = "0.1.0" 4description = "Add your description here" 5readme = "README.md" 6requires-python = "==3.12.8" 7dependencies = [ 8 "anthropic>=0.69.0", 9 "beautifulsoup4>=4.14.2", 10 "chromadb>=1.1.0", 11 "datasets==3.6.0", 12 "feedparser>=6.0.12", 13 "google-genai>=1.41.0", 14 "google-generativeai>=0.8.5", 15 "gradio>=5.47.2", 16 "ipykernel>=6.30.1", 17 "ipywidgets>=8.1.7", 18 "jupyter-dash>=0.4.2", 19 "langchain>=0.3.27", 20 "langchain-chroma>=0.2.6", 21 "langchain-community>=0.3.30", 22 "langchain-core>=0.3.76", 23 "langchain-openai>=0.3.33", 24 "langchain-text-splitters>=0.3.11", 25 "litellm>=1.77.5", 26 "matplotlib>=3.10.6", 27 "nbformat>=5.10.4", 28 "modal>=1.1.4", 29 "numpy>=2.3.3", 30 "ollama>=0.6.0", 31 "openai>=1.109.1", 32 "pandas>=2.3.3", 33 "plotly>=6.3.0", 34 "protobuf==3.20.2", 35 "psutil>=7.1.0", 36 "pydub>=0.25.1", 37 "python-dotenv>=1.1.1", 38 "requests>=2.32.5", 39 "scikit-learn>=1.7.2", 40 "scipy>=1.16.2", 41 "sentence-transformers>=5.1.1", 42 "setuptools>=80.9.0", 43 "speedtest-cli>=2.1.3", 44 "tiktoken>=0.11.0", 45 "torch>=2.8.0", 46 "tqdm>=4.67.1", 47 "transformers>=4.56.2", 48 "wandb>=0.22.1", 49 "langchain-huggingface>=1.0.0", 50 "langchain-ollama>=1.0.0", 51 "langchain-anthropic>=1.0.1", 52 "langchain-experimental>=0.0.42", 53 "groq>=0.33.0", 54 "xgboost>=3.1.1", 55 "python-frontmatter>=1.1.0", 56 "pgvector>=0.4.2", 57 "psycopg2-binary>=2.9.11", 58]
2. Prepare Custom Data
2.1. Basic Imports
1from pathlib import Path 2from openai import OpenAI 3from dotenv import load_dotenv 4from pydantic import BaseModel, Field 5from chromadb import PersistentClient 6from tqdm import tqdm 7from litellm import completion 8import numpy as np 9from sklearn.manifold import TSNE 10import plotly.graph_objects as go 11import os 12from typing import TypedDict
2.2. Constants
1load_dotenv(override=True) 2 3DB_NAME = "preprocessed_db" 4collection_name = "docs" 5embedding_model = "text-embedding-3-large" 6KNOWLEDGE_BASE_PATH = Path("knowledge-base") 7AVERAGE_CHUNK_SIZE = 2500 8KNOWLEDGE_GLOB_EXPRESSION = "../src/mds/articles/**/*.md" 9RETRIEVAL_K = 10 10 11os.environ["AZURE_API_KEY"] = os.getenv("AZURE_OPENAI_API_KEY") 12os.environ["AZURE_API_BASE"] = os.getenv("AZURE_OPENAI_ENDPOINT") 13 14MODEL = f"azure/{os.getenv('AZURE_OPENAI_MODEL')}"
2.3. Modified print for Jupyter Notebook
This is to display text with fixed width in jupyter notebook:
1import textwrap 2 3def printw(text: str): 4 wrapped = textwrap.fill(text, width=100) 5 print(wrapped)
2.4. Custom models before vectorization
2.5. Model for vectorization
1class CustomDocument(TypedDict): 2 tags: str 3 title: str 4 text: str
2.6. Models for semantic chunking
1class Result(BaseModel): 2 page_content: str 3 metadata: dict 4 5class Chunk(BaseModel): 6 headline: str = Field( 7 description="A brief heading for this chunk, typically a few words, that is most likely to be surfaced in a query. This headline must be in English") 8 summary: str = Field( 9 description="A few sentences summarizing the content of this chunk to answer common questions, this ummary must be in English") 10 original_text: str = Field( 11 description="The original text of this chunk from the provided document, exactly as is, not changed in any way") 12 13 def as_result(self, document): 14 metadata = {"title": document["title"], "tags": document["tags"]} 15 return Result(page_content=self.headline + "\n\n" + self.summary + "\n\n" + self.original_text, metadata=metadata) 16 17class Chunks(BaseModel): 18 chunks: list[Chunk]
2.7. Get title and tags from blog markdown
Our markdowns are of the following format:
-
1--- 2title: some title 3tags: a, b, c 4--- 5 6## Title 7 8Contents ...
We get the title and tags from markdowns as follows:
1def get_tags_and_title_from_blogpost(filepath: str) -> tuple[str, str]: 2 try: 3 blog_post = frontmatter.load(filepath) 4 except Exception as e: 5 print(f"Error loading {filepath}: {e}") 6 raise 7 8 tags = blog_post.get("tag", "") 9 title = blog_post.get("title", "") 10 11 if isinstance(tags, list): 12 tags = ",".join(sorted(tags)) 13 elif isinstance(tags, str) and "," in tags: 14 tags = ",".join(sorted([t.strip() for t in tags.split(",")])) 15 return tags, title
2.8. fetch_documents
Finally we prepare all documents:
1import frontmatter 2import glob 3import os 4import re 5 6def fetch_documents(knowledge_glob_path: str) -> list[CustopmDocument]: 7 """A homemade version of the LangChain DirectoryLoader""" 8 9 documents: list[dict] = [] 10 11 for file in glob.glob(knowledge_glob_path, recursive=True): 12 # Load with frontmatter to automatically strip the --- section 13 blog_post = frontmatter.load(file) 14 tags, title = get_tags_and_title_from_blogpost(file) 15 16 # Get content without frontmatter 17 text = blog_post.content 18 19 # Remove <style>...</style> blocks (including multiline) 20 text = re.sub(r'<style[^>]*>.*?</style>', '', text, flags=re.DOTALL | re.IGNORECASE) 21 22 # Clean up extra whitespace 23 text = text.strip() 24 25 documents.append(CustomDocument(tags=tags, title=title, text=text)) 26 27 print(f"Loaded {len(documents)} documents") 28 return documents 29 30documents = fetch_documents(KNOWLEDGE_GLOB_EXPRESSION)
3. Start of Semantic Chunking
3.1. make_user_prompt and make_user_messages
1def make_user_prompt(document: CustomDocument): 2 how_many = (len(document["text"]) // AVERAGE_CHUNK_SIZE) + 1 3 return f""" 4 You take a document and you split the document into overlapping chunks for a KnowledgeBase. 5 6 The document is from the articles from Blog of James Lee. 7 The document is of tags: {document["tags"]} 8 The document has title: {document["title"]} 9 10 A chatbot will use these chunks to answer questions about the articles and retrieve a related list of articles for the reader. 11 You should divide up the document as you see fit, being sure that the entire document is returned in the chunks - don't leave anything out. 12 This document should probably be split into {how_many} chunks, but you can have more or less as appropriate. 13 There should be overlap between the chunks as appropriate; typically about 25% overlap or about 50 words, so you have the same text in multiple chunks for best retrieval results. 14 15 For each chunk, you should provide a headline, a summary, and the original text of the chunk. 16 Together your chunks should represent the entire document with overlap. 17 18 Here is the document: 19 20 {document["text"]} 21 22 Respond with the chunks. 23 """ 24 25def make_user_messages(document: CustomDocument): 26 return [ 27 {"role": "user", "content": make_user_prompt(document)}, 28 ]
3.2. Example of the chunks
1messages = make_user_messages(documents[1]) 2response = completion(model=MODEL, messages=messages, response_format=Chunks) 3reply = response.choices[0].message.content 4doc_as_chunks = Chunks.model_validate_json(reply).chunks
Here the model_validate_json method from pydantic.BaseModel will convert a json string into the corresponding class object in Python.
Let's print a summary from Chunk as an example (recall the definition of Chunk from 〈2.6. Models for semantic chunking〉):
1summary=doc_as_chunks[0].summary 2printw(summary)
which results in:
1This article from James Lee's blog reflects on his illustrations drawn during middle school. Despite 2some drawings being embarrassing, he shares a series of images that capture his early artistic 3efforts, documenting his personal history and growth in art.
3.3. Start Chunking
3.3.1. create_chunks
1import pickle 2import os 3 4@retry(wait=wait) 5def process_document(document): 6 messages = make_user_messages(document) 7 response = completion(model=MODEL, messages=messages, response_format=Chunks) 8 reply = response.choices[0].message.content 9 doc_as_chunks = Chunks.model_validate_json(reply).chunks 10 return [chunk.as_result(document) for chunk in doc_as_chunks] 11 12def create_chunks(documents): 13 chunks = [] 14 for doc in tqdm(documents): 15 chunks.extend(process_document(doc)) 16 return chunks
3.3.2. Save the chunks locally
1import pickle 2 3chunks = create_chunks(documents) 4with open("chunks.pkl", "wb") as f: 5 pickle.dump(chunks, f)
3.3.3. Retrieve the chunks
1def get_chunks(documents, cache_file="chunks.pkl", force_refresh=False): 2 """Get chunks from cache or create new ones.""" 3 4 if os.path.exists(cache_file) and not force_refresh: 5 print(f"Loading chunks from {cache_file}...") 6 with open(cache_file, "rb") as f: 7 return pickle.load(f) 8 9 print("Creating chunks...") 10 chunks = create_chunks(documents) 11 12 with open(cache_file, "wb") as f: 13 pickle.dump(chunks, f) 14 print(f"Saved {len(chunks)} chunks to {cache_file}") 15 16 return chunks
Now we start with
1chunks = get_chunks(documents)
4. Vector Embeddings and Chroma Database
4.1. create_embeddings
1from openai import AzureOpenAI 2import os 3 4client = AzureOpenAI( 5 api_key=os.getenv("AZURE_OPENAI_API_KEY"), 6 api_version=os.getenv("AZURE_API_VERSION"), 7 # https://shellscriptmanager.openai.azure.com 8 azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT") 9) 10 11EMBEDDING_MODEL = "text-embedding-ada-002" 12 13 14def create_embeddings(batch_of_texts: list[str]) -> list[list[float]]: 15 response = client.embeddings.create( 16 model=EMBEDDING_MODEL, 17 input=batch_of_texts 18 ) 19 print(response) 20 print(response.data[0]) 21 return [e.embedding for e in response.data]
Since it is impossible to upload the batch of all texts conversion into embeddings, although the API allows us to do so, we soon get an error due to rate limit.
Therefore we come up with the next slightly modified approach to get the embeddings:
4.2. create_embeddings_batched
1import time 2from typing import List 3 4def create_embeddings_batched(texts: List[str], batch_size: int = 100) -> List[List[float]]: 5 """Create embeddings in batches to avoid rate limits""" 6 all_embeddings = [] 7 8 for i in tqdm(range(0, len(texts), batch_size), desc="Creating embeddings"): 9 batch = texts[i:i + batch_size] 10 11 try: 12 response = client.embeddings.create( 13 model=EMBEDDING_MODEL, 14 input=batch 15 ) 16 all_embeddings.extend([e.embedding for e in response.data]) 17 except Exception as e: 18 if "rate limit" in str(e).lower(): 19 print(f"Rate limit hit, waiting 60 seconds...") 20 time.sleep(60) 21 # Retry the same batch 22 response = client.embeddings.create( 23 model=EMBEDDING_MODEL, 24 input=batch 25 ) 26 all_embeddings.extend([e.embedding for e in response.data]) 27 else: 28 raise 29 30 # Add delay between batches to avoid rate limits 31 if i + batch_size < len(texts): 32 time.sleep(2) # 2 second delay between batches 33 34 return all_embeddings
4.3. Save vectors into local chroma db
For quick experiment we first save everything into a local sqlite db. Once all the experiments are done, we will upload these vectors onto PostgreSQL.
1def save_vector_embeddings(chunks): 2 chroma = PersistentClient(path=DB_NAME) 3 if collection_name in [c.name for c in chroma.list_collections()]: 4 chroma.delete_collection(collection_name) 5 6 texts = [chunk.page_content for chunk in chunks] 7 8 # Use batched version instead 9 vectors = create_embeddings_batched(texts, batch_size=50) 10 11 collection = chroma.get_or_create_collection(collection_name) 12 13 ids = [str(i) for i in range(len(chunks))] 14 metas = [chunk.metadata for chunk in chunks] 15 16 collection.add(ids=ids, embeddings=vectors, 17 documents=texts, metadatas=metas) 18 print(f"Vectorstore created with {collection.count()} documents")
The creation of embedding does not take very long:
1Creating embeddings: 100%|██████████| 29/29 [05:15<00:00, 10.86s/it] 2 3Vectorstore created with 1411 documents
4.4. Graph plotting for the embeddings in 3D
1chroma = PersistentClient(path=DB_NAME) 2collection = chroma.get_or_create_collection(collection_name) 3result = collection.get(include=['embeddings', 'documents', 'metadatas']) 4vectors = np.array(result['embeddings']) 5documents = result['documents'] 6metadatas = result['metadatas'] 7doc_tags = [metadata['tags'] for metadata in metadatas]
Outcome:
1tsne = TSNE(n_components=3, random_state=42) 2reduced_vectors = tsne.fit_transform(vectors) 3 4# Create the 2D scatter plot 5fig = go.Figure(data=[go.Scatter3d( 6 x=reduced_vectors[:, 0], 7 y=reduced_vectors[:, 1], 8 z=reduced_vectors[:, 2], 9 mode='markers', 10 marker=dict(size=5, opacity=0.8), # Removed color parameter 11 text=[f"Tags: {m['tags']}<br>Title: {m['title']}<br>Text: {d[:100]}..." 12 for m, d in zip(metadatas, documents)], 13 hoverinfo='text' 14)]) 15 16fig.update_layout(title='2D Chroma Vector Store Visualization', 17 xaxis_title='x', 18 yaxis_title='y', 19 width=800, 20 height=600, 21 margin=dict(r=20, b=10, l=10, t=40) 22 ) 23 24fig.show()
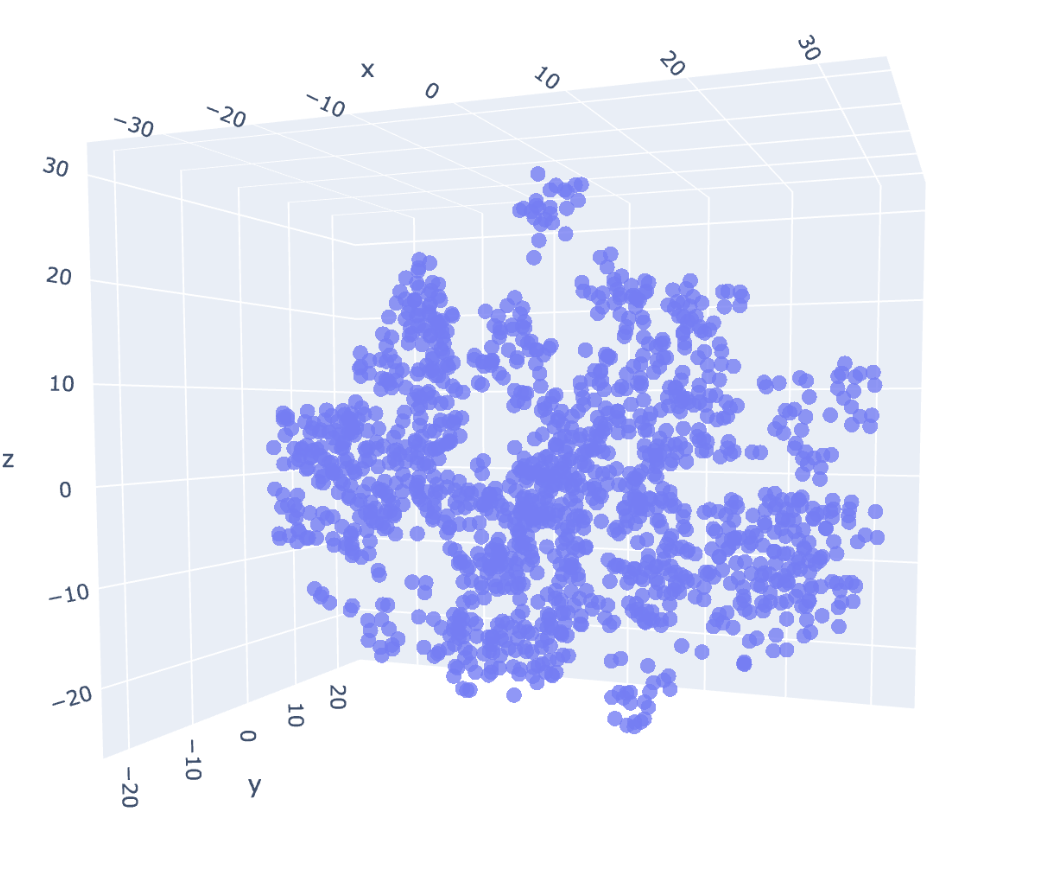
5. Fetch and Rerank results from Vector DB According to the Question
5.1. fetch_context_unranked
1def fetch_context_unranked(question): 2 # query = openai.embeddings.create(model=embedding_model, input=[question]).data[0].embedding 3 query = create_embeddings([question]) 4 results = collection.query(query_embeddings=query, n_results=RETRIEVAL_K) 5 chunks = [] 6 for result in zip(results["documents"][0], results["metadatas"][0]): 7 chunks.append(Result(page_content=result[0], metadata=result[1])) 8 return chunks
5.2. rerank
1class RankOrder(BaseModel): 2 order: list[int] = Field( 3 description="The order of relevance of chunks, from most relevant to least relevant, by chunk id number" 4 ) 5 6def rerank(question, chunks): 7 system_prompt = """ 8You are a document re-ranker. 9You are provided with a question and a list of relevant chunks of text from a query of a knowledge base. 10The chunks are provided in the order they were retrieved; this should be approximately ordered by relevance, but you may be able to improve on that. 11You must rank order the provided chunks by relevance to the question, with the most relevant chunk first. 12Reply only with the list of ranked chunk ids, nothing else. Include all the chunk ids you are provided with, reranked. 13""" 14 user_prompt = f"The user has asked the following question:\n\n{question}\n\nOrder all the chunks of text by relevance to the question, from most relevant to least relevant. Include all the chunk ids you are provided with, reranked.\n\n" 15 user_prompt += "Here are the chunks:\n\n" 16 for index, chunk in enumerate(chunks): 17 user_prompt += f"# CHUNK ID: {index + 1}:\n\n{chunk.page_content}\n\n" 18 user_prompt += "Reply only with the list of ranked chunk ids, nothing else." 19 messages = [ 20 {"role": "system", "content": system_prompt}, 21 {"role": "user", "content": user_prompt}, 22 ] 23 response = completion(model=MODEL, messages=messages, 24 response_format=RankOrder) 25 reply = response.choices[0].message.content 26 order = RankOrder.model_validate_json(reply).order 27 print(order) 28 return [chunks[i - 1] for i in order]
We combine to get:
5.3. fetch_reranked_context
1def fetch_reranked_context(question): 2 chunks = fetch_context_unranked(question) 3 return rerank(question, chunks)
6. Prompts to Answer Question with Agentic Reranking
6.1. rewrite_query
1SYSTEM_PROMPT = """ 2You are a knowledgeable, friendly assistant to search for articles in the blog of James Lee. 3You are chatting with a user about finding related articles. 4Your answer will be evaluated for accuracy, relevance and completeness, so make sure it only answers the question and fully answers it. 5If you don't know the answer, say so. 6For context, here are specific extracts from the Knowledge Base that might be directly relevant to the user's question: 7{context} 8 9With this context, please answer the user's question. Be accurate, relevant and complete. 10""" 11 12def make_rag_messages(question, history, chunks): 13 context = "\n\n".join( 14 f"Extract from article titled '{chunk.metadata['title']}':\n{chunk.page_content}" for chunk in chunks) 15 system_prompt = SYSTEM_PROMPT.format(context=context) 16 return [{"role": "system", "content": system_prompt}] + history + [{"role": "user", "content": question}] 17 18def rewrite_query(question, history=[]): 19 """Rewrite the user's question to be a more specific question that is more likely to surface relevant content in the Knowledge Base.""" 20 21 sys_message = f""" 22 You are in a conversation with a user, answering questions about the articles from the blog of James Lee. 23 You are about to look up information in a Knowledge Base to answer the user's question. 24 25 This is the history of your conversation so far with the user: 26 {history} 27 28 And this is the user's current question: 29 {question} 30 31 Respond only with a single, refined question that you will use to search the Knowledge Base. 32 It should be a VERY short specific question most likely to surface content. Focus on the question details. 33 IMPORTANT: Respond ONLY with the knowledgebase query, nothing else. 34 """ 35 response = completion(model=MODEL, messages=[ 36 {"role": "system", "content": sys_message}]) 37 return response.choices[0].message.content
6.2. answer_question
1def answer_question(question: str, history: list[dict] = []) -> tuple[str, list]: 2 """ 3 Answer a question using RAG and return the answer and the retrieved context 4 """ 5 query = rewrite_query(question, history) 6 print(query) 7 chunks = fetch_reranked_ontext(query) 8 messages = make_rag_messages(question, history, chunks) 9 response = completion(model=MODEL, messages=messages) 10 return response.choices[0].message.content, chunks
7. Local Experiments
7.1. rewrite_query
1rewrite_query("find me an article about the departure / resignation of staffs in a company", [])
Outcome:
1'article about staff resignation or departure in a company'
7.2. answer_question
1answer_question( 2 "find me an article about the departure / resignation of staffs in a company", [])
1('You can refer to the article titled **"下一站,中國銀行"**, which covers the topic of challenges and turnover leading to resignations in a company. Specifically, it discusses the period from October 2024 to December 2025 when multiple key developers resigned or were laid off due to increased workload, management using AI tools in a complicated way, limited salary increases, and a company focus shift towards Australia. This prompted James Lee himself to resign in December 2025.\n\nThe article highlights:\n\n- Loss of desired opportunities and being forced to do more front-end and cloud work.\n- Issues caused by "No Code" project management that complicated developers\' workload.\n- Key colleagues leaving around mid to late 2025.\n- The company’s strategy to limit salary raises to encourage natural attrition of staff from Hong Kong and China.\n- The resignation of James Lee and subsequent departures impacting the front-end team workload significantly.\n\nThis article provides a detailed account of staff departures and the underlying reasons within that company context.\n\nIf you want, I can provide you with specific excerpts or sections from this article.', 2 [Result(page_content='Challenges and Turnover Leading to Resignation (Oct 2024 - Dec 2025)\n\nFrom October 2024 to August 2025, James experienced loss of desired opportunities, increased workload with front end and cloud tasks, and management using AI tools to accelerate but also complicate development. Key developers left under layoffs or resignation. The company shifted focus to Australia, limited salary increases, prompting James to seek new opportunities, and he eventually resigned in December 2025.\n\n#### 2024 年 10 月 ~ 2025 年 8 月 (離職念頭的萌芽)\n\n\n\n##### 失去很多想要的機會\n\n在這些 developer 中,有些人是幾乎在前端幫不上忙,愈幫愈忙的,就被派去做後端。而我這種六邊形戰士,甚麼都可以做的,就被迫做更多前端的工作。久而久之,我變成主力做 cloud 加前端,都不是我想要做的工作。\n\n##### Lovable UI 之亂,No Code Manager 之變本加厲\n\nAI 工具令 project manager 更輕鬆,同時令 developer 更忙更難受。\n\n以前這位 no code manager 會在 figma 畫原型,當半個 ui designer。會用 lovable UI 後,直接整個生成出來。但是需求不停變,他也沒辦法用咒語把他 "想要的" 的呈現到 lovable UI 的預覽中,導致需求跟預覽沒辦法統一,根本不知道要不要再參考這個***預覽***。\n\n正常一間公司,都會有 ui designer 在產品開發的最初期跟 project manager 緊密聯系,做出一個可以模疑整個 business flow 的假貨,在早期就把邏輯,ux,都確定好。現在這公司嘗試 skip 掉這個 ui designer,來折磨 developer。\n\n其次,他想要我們從 lovable UI 的原碼開始改,要做到跟他一模一樣,可是 lovable UI 的 code 動輒 4000 行.....,甚麼 logic 都塞進同一個檔案。我可是花了很大力氣把它 refactor 成 1000 行,且重新綁定成我們處理 state 的套路。\n\n後來他乾脆 ui 都不弄了,要我們通靈,我們做好後他再想怎麼改。所以我們要以 "會被改掉" 前提下去做新的 UI。這算是這公司的一大特色,大開眼界了。\n\n#### 各自離職,前端將成缺口\n\n- 2025 年 7 月底大陸同事被辭退;\n\n- 2025 年 8 月底一位前端同事有其他機會而離職。\n\n各方溝通後能看出公司想以限制加薪的方式讓 香港/大陸 職員自然流失,把重心放在澳洲。這也促使我尋找更好的發展機會。經過 [#find_job] 後︰\n\n- 2025 年 12 月中旬 我離職;\n\n- 2026 年 1 月中旬 新 Tech Lead 離職。\n\n\n```mermaid\ngraph TD;\nA["5 Dev + 1 AI (HK)"] --> |1年後| B["<span style=\'color: blue\'>1 New Dev (Australia)</span> + 1 Dev (China) + 1 AI (HK)"]\n```\n\n9 月份新聘的澳洲 developer 不會前端,也就是 2026 年 1 月後所有***極為繁重***的 frontend (手機 + 網頁) 工作將全推給***一個人***承擔。\n\n而公司最近 interview 的下一任新 Tech Lead 非常會 Cloud,但只會 Angular,也就等於在這公司的前端上沒有任何輸出能力。前端這工作量沒有兩個人來分擔基本上是啃不下的。尤其是手機端需要 Android + iOS 同時維護,還要理解 Expo Ecosystem 和 App Store Connect 跟 Google Play Console 的各種 configuration,不是隨便找個 React Developer 就能夠應付的。\n\n看來前端部分將成為一個極大的流失缺口,都是被工作量和不恰當人才聘用迫走的。\n\n\n#### 公司最大的問題\n\n\n\n<spacer></spacer>\n\n> <spacer height="0"></spacer>\n> 由沒有編程經驗的人來做 Product Manager。\n\n\n<spacer height="0"></spacer>\n\n他們一天沒有意識到這個問題,基本上公司都不會走得遠。\n\n沒有編程經驗的 PM ,或者是說,沒有在 IT 公司***受聘過***的 no code PM,真的應該每天下班拿個一小時出來學習怎樣寫程式,不然這種 PM 只會把一個又一個 developer 趕走。\n\n要不要看看對岸台灣的 no code PM 都在幹甚麼的?\n\n- https://www.threads.com/@paullwc/post/DRomZ-zk4pf\n\n再看看我們現在公司那位?\n\n我們耐性非常高的新 Tech Lead 也跟他對不上嘴,更何況是我這種性格比較剛烈的 developer?我不在乎錢,你有種可以跟我對着幹,我是隨時就能離職那種。\n\n其實我幹了一年就想跑路了,累得跟狗一樣。可是新增聘的人手確實不錯所以再待個一年看看,這樣一待就是兩年半。基本上到這階段 (9 月份) 都把所有責任都分散出去了,是隨時都能離開的狀態。', metadata={'title': '下一站,中國銀行', 'tags': 'personal'}), 3 Result(page_content='Joining and Early Experiences at Startup (May-Nov 2023)\n\nJames Lee joined the startup in May 2023, initially working on fixing features and backend endpoints. The company had a small team with one senior Tech Lead and an AI engineer. The Tech Lead lacked experience with React and mobile development, leading James to take initiative on the mobile React Native project. Several issues with the Tech Lead\'s approach, like ignoring TypeScript, problematic database migration to MongoDB, lack of CI/CD, and poor backend architecture, caused dissatisfaction.\n\n### 談談工作了兩年半的初創公司\n\n#### 時間線\n\n```mermaid\ngraph TD;\n A["<div style=\'padding-bottom: 10px\'><span style=\'border-radius: 4px; border: 1px solid rgba(0,0,0,0.4); padding: 0px 4px\'>2023年05月中</span> 加入公司</div>"]\n --> B["<div style=\'padding-bottom: 10px\'><span style=\'border-radius: 4px; border: 1px solid rgba(0,0,0,0.4); padding: 0px 4px\'>2023年05月~08月</span> 扭螺絲,加 backend endpoint,加 ui</div>"]\n --> C["<div style=\'padding-bottom: 10px\'><span style=\'border-radius: 4px; border: 1px solid rgba(0,0,0,0.4); padding: 0px 4px\'>2023年09月~11月</span> 開始移動端 Project</div>"]\n --> D["<div style=\'padding-bottom: 10px\'><div style=\'padding-bottom: 4px\'><div><span style=\'border-radius: 4px; border: 1px solid rgba(0,0,0,0.4); padding: 0px 4px\'>2023年11月</span> Intern 入職</div><div><span style=\'border-radius: 4px; border: 1px solid rgba(0,0,0,0.4); padding: 0px 4px\'>2023年12月末</span> \'\'Tech Lead (?)\'\' 離職</div></div>"]\n --> E["<div style=\'padding-bottom: 10px\'><span style=\'border-radius: 4px; border: 1px solid rgba(0,0,0,0.4); padding: 0px 4px\'>2024年01月~06月</span> 我 + 半年的實習 + 1 個月的本地 Developer</div>"]\n --> F["<div style=\'padding-bottom: 10px\'><div><span style=\'border-radius: 4px; border: 1px solid rgba(0,0,0,0.4); padding: 0px 4px\'>2024年07月~09月</span> 開始擴充人手至 5 Dev Developer + 1 AI developer,</div><div>新 Tech Lead 加入</div></div>"]\n --> |1 年後| G["<div style=\'padding-bottom: 10px\'><span style=\'border-radius: 4px; border: 1px solid rgba(0,0,0,0.4); padding: 0px 4px\'>2025年08月</span> 同事有的被裁,有的離職</div>"]\n --> H["<div style=\'padding-bottom: 10px\'><span style=\'border-radius: 4px; border: 1px solid rgba(0,0,0,0.4); padding: 0px 4px\'>2025年12月中</span> 我離職</div>"]\n```\n\n#### 2023 年 5 月 ~ 2023 年 11 月\n\n##### 對 "Tech Lead" 的不信任\n\n大概二年半前我剛加入現在的公司的時候,剛好是當時公司主力項目的最終階段。我主要都在修他們已有的 feature,加加功能,扭扭螺絲。那個時段正好是人力交替周期,辭職的辭職,各有不同的出路。IT 相關的職員只剩下一個 senior 的 "Tech Lead" 跟一個 AI engineer。\n\n三個月後,公司展開一個新的手機項目。這領域對這位 "Tech Lead" 來說非常陌生。\n\n其一,他不熟 React;其二,他沒有幹過 native mobile application 的項目。以致他沒有任何基礎在新項目上作出任何技術上的決策。而作為 react developer 的我,理所當然決定使用 react-native 來開發新項目了。\n\n因為我有參與舊 project 的一些短期維護,所以看到這位 Lead 帶領下 project 的一些慘況以及他的行為令我對他抱有極為負面的看法。\n\n###### ❌ 都 2023 年了還沒在用 Typescript ?\n\n我不了解他們的技術選型是如何做到 3 人合作 (我入職前的 team size),但堅持使用 `js` 來跑這個網頁 project。到我接手的時候,他只是一個到處都是 `any` type 的炸彈。我要花很多時間從 chrome debugger (source 頁面) 把 data type 弄清楚,再把重點要改的頁面變成 `.ts` 檔才有辦法改下去。\n\n這年頭不選 `typescript` 是根本沒有 nodejs 生態的知識嗎?\n\n\n###### ❌ 不合理地從 MySQL 遷移到 MongoDB\n\n後端用的 Spring Boot,原本是使用 MySQL,然後有一半已經改為 MongoDB。詢問轉換原因,"Tech Lead" 認為 business 經常改變,所以 MongoDB 這種沒有 schema 的 persistence solution 更適合,因為 schema 更具彈性(蛤?)。\n\n這絕對是一個***嚴重的 Skill Issue***。\n\n2023 年年底的新 React Native Project 我直接從 MongoDB 改成使用 Prisma + PostgreSQL。這個新 project 至今跑了兩年,還是走得好好的,business 還一直改,用的是 (從 Nodejs Express 變成) Spring Boot。\n\n###### ❌ 允許沒有 CI/CD\n\n簡單的一個 React Application,原來是在 EC2 上跟 Spring Boot Backend 綁在一起,順便在 EC2 上 host 的。Deployment 方法是使用純手工的精美 shell script,連到 EC2 上作一輪精彩的操作 (打斷 spring,上傳 zip,unzip,啟動,...)。這是我第一家公司沒在用 CI/CD 的,也是太精彩了。\n\n作為 "Tech Lead" 竟然允許公司做的是手動 deploy?無論是前端還是後端,`DEV` 應該是 merge 了就立刻 deploy,所有爆炸性問題應盡早在 `DEV` 找到。UAT 同理。\n\n\n###### ❌ 沒有 Repository 的 Spring Boot\n\nSpring Boot 以齊全的腳手架而聞名。\n\n這個舊 Spring Boot Project 有一個絕妙的點,整個項目 ***完全沒有*** repository 的概念。你都使用 mongo 了,不是有 `spring-data-mongodb` 可以用嗎?難道所有簡單的 "query" 都要自己手擼出來嗎。\n\nNodejs 的話好歹還是有個 `Model` (from `mongoose`) 的概念,這個 Spring Boot Project 直接用 `MongoTemplate` 硬幹到底。還滿佈沒有 Type 的 `bson.Document` object,比 `js` 還更 `js`。\n\n如何在 Spring Boot 正確使用 MongoDB,請參看本 blog 文章: [Spring Data MongoDB](/blog/article/Spring-Data-MongoDB)。\n\n###### ❌ 不學無術,愛擺架子\n\n抱有過份的階級觀念。他技術不行,但又死愛面子。在我這些認真好學,經常鑽研技術的 developer 眼中,根本沒辦法跟這種不好好做學問的人相處。我記得我進公司第 4 個月吧,我差點要鬧辭職了。\n\n後來如我所料,它在離職後在自己的 Linkedin 自我介紹加上跟他完全沒關係的工作經驗 (整個 React Native 關他屁事呢?)。\n\n\n\n我早已看清這個人沒甚麼學術誠信,我從直覺上就覺得跟這種人合不來。', metadata={'tags': 'personal', 'title': '下一站,中國銀行'}), 4 Result(page_content='Tech Lead\'s Departure and Increased Responsibilities (Nov 2023 - Jun 2024)\n\nThe Tech Lead resigned in late 2023, giving James the opportunity to lead backend architecture, deployment strategy, schema design, and build all necessary infrastructure and CI/CD pipelines. He worked with interns and other developers, used various deployment methods including Lambda functions and ECS, and improved cloud infrastructure management with Terraform and secure access.\n\n#### 2023 年 11 月 ~ 2024 年 6 月\n\n##### "Tech Lead" 的離去\n\n十月份左右,他終於覺得自己可以做的貢獻太少,所以提出離職了。他的通知期是兩個月,12 份月離開。\n\n\n當時的 Tech Lead 偏愛 MongoDB,而因為他即將離去所以選擇我當時熟悉的 Tech Stack。為了開發效率我們嘗試 Express + MongoDB (最終變成 Spring Boot + PostgreSQL,這又是另一個故事了)。工作這幾年都由更 senior 的人來***從零***建立後端,這方面我沒甚麼 hands-on 經驗,也只好邊學邊做。\n\n\n後來我們使用 MongoDB 的方式根本與 relational db 方式沒差別,所以在 2023 年年底從 MongoDB 遷移到 PostgreSQL 去了。這遷移工作自然也是由我來做的。\n\n\n##### 得來不易的決策機會\n\n\n\n<spacer></spacer>\n\n\n"Tech Lead" 的離開令我不得不從後端,Schema Design,上 Cloud,走 Lambda Function,CI/CD,一手包辦。這是一個很好的機會,在 "有一位比你更 senior 的人存在" 下,以下\n\n- Deployment Strategy\n- Backend Architecture\n- Schema Design\n\n根本不可能讓 "更 junior" 的人隨便做決策的。Senior 很大機會把最有價值的工作搶來做的 (更何況有些人單純只會邀功的?) 。\n\n正好這位 "Tech Lead" 的離開令我有隨意發揮的機會。同時我的發揮令到公司的原型產品能如期推出。我敢肯定這位 "Tech Lead" 繼續留下來的話,原型開發進度不可能有那麼快。\n\n\n##### 建立 Development Team 所有基礎設施\n\n\n在小公司,當公司***缺人***的時候,你就可以得到這種中等或以上規模的公司得不到的機會。託賴公司對我的信任,加上我自己私人時間的研究,我在公司建立了\n\n1. **所有 CI/CD Workflow.** \\\n 包括所有 backend (Python, Spring Boot, Nestjs, Express) 其 pipeline (workflow) 所需的 `yml` file,以及提倡 Github Action 作為 CI/CD 工具 (後來 Gitlab 才宣佈不再支援香港)。\n\n2. **兩㮔 Deployment 模式.** \\\n CI/CD workflow 有兩種 deployment 模式,一種是經 Lambda Function,一種是經 ECS。\n\n Lambda Function 也有很多種類︰\n - 有 python 的;\n - 有 nodejs 的;\n - 有 spring boot (snap-started) 的;\n - 有 unzipped size 超過 250 mb,經 docker image 跑的。\n\n 每一種都經過很多時間研究。\n\n3. **完整的 Database Schema Migration 制度.** \\\n 這對多人合作建立 Backend 非常重要,每位成員 migrate schema 時都確保是當前最新狀態 (不然報錯)。\n\n4. **所有必需的 Cloud Infrastructure.** \\\n 包括 rds, rds-proxy, load-balancer, private load-balancer, cloudfront, ..., 應有的都有。以及後來使用 Terraform 來達成整個 Infrastructure 的可重覆性。\n\n5. **完善的 Cloud Infrastructure 網頁.** \\\n 讓團隊成員可以取得所有 Infrastructure 的資訊 (從 terraform export 出來的)。例如\n - Websocket endpoints;\n - Loadbalancer 每一個 port 對應的 service;\n - 各 service 的 cloudwatch log 連結\n\n 等等。以上的內容都是從一個 backend endpoint 取得,並建立了一個簡單的 Google Authentication (只有本公司 email 可登入成功),只有登入成功後才可以從 endpoint 取得資訊,以確保內容保密。\n\n\n##### 幾乎獨撐的半年,人事小變動\n\n\n\n###### 一位半年的實習生\n\n為了減輕我的工作量,公司試驗性地增聘人手。在 2023 年 11 月公司請了一位實習生,很會用 AI(我當時還不怎麼用),交付給實習生的任務大都能處理好。儘管我們後端用的是直接用 SQL 跟 database 交互的方式,都可以很快上手然後處理後台的 business logic。\n\n後端方面,他主要是負責 UI 的新頁面,有需要甚麼 data 的話,他都可以自己去聯一下表弄一個 `GET` endpoint。因為沒有 ORM,完全沒有 N+1 問題的包袱,寫出來的東西在 query builder 加持下也鮮有 performance 問題。\n\n前端日常我會偶爾指導一下 AI 不會提到,但實作時才會發現的問題。最典型就是修改 list 的內容時瘋狂 `useState` 導致的效能問題。用 redux 精準控制需要 rerender 的組件即可解決。這是一類遇不到就很難解釋清楚的前端陷阱。\n\n最後這半年的成果也成功幫他後來在恒生銀行取得另一份實習工作。\n\n###### 一位待了一個月的本地 Developer,Domain Driven Design 的啟蒙老師\n\n這半年間 (4月還是5月份) 我們也面試了一位本地的 Developer,跟我一樣是念數學系的。Domain Driven Design (DDD) 這種概念都是從他那邊學的,研究過 DDD 更加能發現現在 Nodejs Backend 的問題 (我們在 [#backend_failed] 再討論)。\n\n只可惜 DDD 是很吃 framework 的一種設計模式。現存的 nodejs + express 是不可能做到的。就算使用 NestJS + TypeORM 還是會有一定的困難,例如︰\n\n1. 沒有一個對標 Spring Boot 的 `ApplicationEventPublisher`;\n\n2. 沒有機制能對標 Spring Boot 的 Proxy 來處理 `@OneToMany`,`@ManyToMany` 等 annotation。\n\n 你沒有明確寫 left join,他會變成 `undefined`。而 maintain 那條 left join list 也會演變成一場悲劇。\n\n3. 沒有 `@Transactional` 等通用的 annotation (如何模仿 Spring Boot 的 `@Transactional`,詳見 [For Transactions](/blog/article/Fundamentals-of-Nestjs#9.1.1.-decorator-to-set-metadata)) 。\n\n4. 沒有 `@Embedded` 跟 `@Embeddable` 來自然地把 Entity class 跟 Value Object 綁定 (在 Spring Boot 以外強行使用這個 Pattern 是徒增 Project Complexity) 。\n\n由於這位 Developer 的知識對這公司來說有點超前,而他又花太多時間在這方面,以致新的 feature 做得很緩慢甚至比實習生更差。所以被老闆一個月後勸退了。\n\n這對我來說是一個***示例***,如果想帶來創新及改變,必須先在 Personal Project 做,再對團隊提出 (也不要自己偷偷做在公司 Project 做,其他人不認同只會空辛苦一場) 。不用實例說明的話只會變成讓公司在你的 idea 上*賭時間*。\n\n明顯***帶來改變***是費力不討好的,你沒有一定要熱情和想法很難為公司帶來改變,何況有很多不願意改變的人,~~但我就愛推動改變~~。\n\n現在我很習慣用 Spring Boot 跑 DDD 這套 Methodology 了,也希望有機會可以再跟他合作。因為有認知要使用 DDD 人真的不多,實在是太多把第一年經驗重覆 10 年的人,也很難找到對 DDD 有同樣研究程度的人。', metadata={'title': '下一站,中國銀行', 'tags': 'personal'}), 5 Result(page_content="Team Expansion and Interviewer Experience (Jul-Sep 2024)\n\nBetween July and September 2024, James took on interviewing responsibilities to help expand the team with 5 developers plus one AI developer. He filtered out candidates with false claims and lack of essential skills. The team comprised full-stack, frontend, and senior tech lead developers including an Android developer, but some didn't fit well with technologies or roles.\n\n#### 2024 年 7 月 ~ 2024 年 9 月\n\n\n\n##### 第一次擔當 Interviewer 這角色\n\n因為缺人,公司終於認真擴充人手。同時我是公司唯二的 developer,所以就由我來尋找未來的伙伴了。因為當時我只有五年的經驗,我沒自信能帶領一個項目走向成功,所以要老闆盡可能也找一些資深的人來帶領我們。\n\n不想踩雷,所以要求比較嚴謹。有前端需要的話,***必須***有 Portfolio。有後端需要的話,會由我旁邊的 AI engineer 補充我沒問到的問題。有的 candidate 讀書成績好但沒甚麼經驗的,也會被老闆抓來讓我們看看。\n\n面試問題大概是從 CV 的工作內容中選幾項我感興趣的追問下去,看是不是我們需要的和有沒有在撒謊(學術誠信也是能力一部分)。除了 CV 外,我會問問自己遇到的痛點(討教嘛)。\n\n總結而言,一個好的 interview 不單是快樂的,面試雙方可以互相指導大家不熟悉的地方,互相學習。我面試了兩類人,這兩類人我們要求的能力都不同︰\n\n1. **跟我一樣做 Feature 為主的 Contributor.**\n\n 在我面試過的 candidate 之中,確實有很多地雷被我成功 filter 走。具體例子︰\n - **地雷 1.** 說自己手機 FYP 在校拿了個 A grade,但沒辦法 demo (那你當時怎樣拿評分的?CV 上有就有機會問啊 ...,我們也在找做手機應用的人啊 ...)。\n\n - **地雷 2.** CV 說會 Tensorflow。問他項目裏 model 是幹甚麼,他說是 image classification。問他這個 model 用過甚麼 layer,答不出來。我黑人問號???\n\n - **地雷 3.** 我的 interview 有 live-coding 環節,跟我一起修改一個 hack.md 的檔案來達成某個 UI。\n\n 我們要找有 react 經驗的,candidate CV 上也寫有 react 經驗,但怎麼組件寫好了,會出現好幾個\n\n ```ts\n const { state1, state2 } = useState()\n const { state3, state4 } = useState()\n ...\n ```\n\n 之類的怪東西,花括號是甚麼鬼 ...。在 `<input />` box 利用 `onChange` 或 `useRef` 來 紀錄/拿取 輸入內容也做不到。\n\n - **地雷 4.** 問後台有甚麼方法確認 request user 身份,竟然完全沒經驗,答不出任何方案(例如可以經 header / cookie 傳訊息 ...),更不用問要傳甚麼訊息了。\n\n 說來真的很神奇,十個 applicant 裡面,真的只有 1, 2 個會有 Portfolio。這明明是引導 interviewer 問你熟悉的問題的好機會。\n\n2. **Tech Lead,了解老闆需要,做決策,分派任務的.**\n\n 這類 candidate 就跟老闆一起 interview,到了這程度我們就不看 Portfolio 了。我問我遇到的問題,老闆問管理團隊的問題。最後老闆跟 candidate 閉門討論比較私密的問題。\n\n 感覺到這階段我只是頭緝毒犬???\n\n##### 正式成員的編成\n\n原型建立好後,老闆便開始持續招聘,最後把整個團隊擴展到 5 個 developer + 1 個 AI developer。有在香港本地的大陸人,有在大陸 fully remote 的。\n\n而在這公司中,我是唯一一個香港人 ...。這其中\n\n- 有 Full-Stack 的\n- 有專門做 Frontend 的\n- 有從業快 20 年的新 Tech Lead\n- 有資深的 Android Developer(這比 iOS developer 更有優勢,因為可以寫 Kotlin Spring Boot)\n\n陣容在當時來說非常全面了。只可惜這位 Android Developer 學不動 expo 生態,最終也用不上他的 android 知識來為 expo project 添加功能。而且他的前端能力完全沒辦法在 react 生態下表現出來 ...。", metadata={'title': '下一站,中國銀行', 'tags': 'personal'}), 6 Result(page_content='Notice Period Complexity and Departure\n\nDuring his two and a half years at the startup, James experienced multiple salary raises and contract renewals. Unexpectedly, he discovered his official notice period was two months, though he had stated one month when job searching. Fortunately, his boss supported a one-month notice upon resignation. He is grateful for the opportunity and hopeful for future cooperation.\n\n#### 小插曲︰甚麼?我的通知期是兩個月?\n\n在這間初創公司 兩年半 內經歷過 3 次加薪。加上最一開始的合約,這 4 次簽約我不知道甚麼時候通知期開始變成 兩 個月,但我在外面求職都寫自己通知期是 1 個月。\n\n天 ...,我不是甚麼 Lead Role,跟人事提出離職意願時他幫我查一下才發現我的真實通知期。萬幸的是老闆也很支持我到外面闖一闖,而且信任我寫文檔交接的能力(整間公司會瘋狂寫文檔的就我了,而且為了方便閱讀我的文檔都 deploy 成一個 frontend,經 cloudfront share 出去),所以允許我變成正常的一個月通知期。\n\n感謝一直以來提供的機會,他日技術變強了,頭也禿了,看有沒有機會再跟這間公司合作。\n\n', metadata={'title': '下一站,中國銀行', 'tags': 'personal'}), 7 Result(page_content='Job Search Strategy and Offers in 2025\n\nIn September 2025, James began searching for a new job focusing on full-stack or backend roles using Spring Boot, Node.js, or Rust, and rejecting frontend-only roles to align with his career plan. He emphasized the importance of a personal website showcasing portfolios, desain concepts, and a truthful CV. He received two offers: one from I-Charge Solutions (which he considered a rejection) and an attractive one from Bank of China, which he awaited with anticipation.\n\n### 求職 (2025 年 9 月) {#find_job}\n\n#### 策略\n\n\n\n<spacer></spacer>\n\n最後工作找了一個多月,因為我一路以來(無論是上班時,或者是下班後)都在不斷思考和不斷作出新的嘗試,我把這些嘗試總結成 [Portfolio](/portfolio),或者是 [Blog](/blog) 中的文章,方便以後重塑同一塊知識點。\n\n展示這些 "作品" 後面試機會還挺多的。我的方向是 全端/純後端,技術棧方面,後端找的是 Spring Boot, Nodejs 或者是 Rust,前端找的是 React / React-Native,且***拒絕所有***純前端的工作,因為這與我的職涯規劃相沖。\n\n我個人認為一個合格的 application 需要有\n\n- **能展示你能力的個人網站.** \\\n 其中包括 Portfolio,前後端的設計理念 (如技術選型,其原因),***能用***的 Deployment,相關的 Github project。\n\n- **一份容易閱讀的 CV.** \\\n 這吃一點點美術。你要有能力***突出重點***,包括︰\n 1. ***用心的排版***,資訊量控制(美術的虛實,在排版中就是留白,字的疏密度)\n\n \n\n 2. ***講重點***,不要加上\n - "令系統少了 85% error"\n - "令前端提昇了 30% 速度"\n\n 等等。這些沒辦法被證明的陳述遠比想像中虛。如實說出你幹過甚麼就好。\n\n 3. ***不要說謊***,你沒有做過就誠實面對,面試官很愛從你的工作內容把細節問到底。\n \n 每一個工作上的決策背後都有前因後果的,如果你的工作內容是***編***出來的很容易就被問出來。\n\n 這次求職過程有面試過 Axa 香港(保險業的),被 4 個 Team Lead 連番轟炸 ...,真的把 CV 連同平常 工作/合作 方式都問得很徹底。\n\n \n\n#### 兩個 Offer\n\n\n\n<spacer></spacer>\n\n尋尋覓覓,有些公司還在做那種我不想碰的 AI wrapper 所以沒有談下去,最後得到兩個 offer︰\n\n1. I-Charge Solutions International (ICS) 的 Analyst Progammer\n2. 中國銀行的 System Analyst\n\nI-Charge 如其說是一個 offer,他更像是一個 rejection。其實我薪金加幅寫了 HKD 5000,是留一個空間讓對方壓價,你但凡加個 HKD 3000 到 HKD 4000 我都會立刻接受,畢竟我真的很想轉環境。I-Charge 出 offer 的時候直接把加幅壓到只剩 HKD 1000。\n\n這就像跟我開一個玩笑,我花時間請個假去面試,但對他們來說原來我就像一個小丑一樣,用來打發他們的時間,用來浪費我的 annual leave。\n\n收到電話通知後從有 offer 到 reject offer 整個過程不到 1 分鐘,心裏只道:「好傢伙。」\n\n另一邊面試中國銀行後,過了兩個禮拜我才收到中國銀行對我有興趣的消息,並從獵頭那邊知道他們想給我 offer。再 3 個禮拜後才正式通知我可以去簽約 ...(太多不確定性了,我完全不知道中國銀行對我的 case 進行到哪一個地步)。\n\n整個等待的過程非常的煎熬,因為我很期待這份工作,且薪金的加幅也很理想。', metadata={'title': '下一站,中國銀行', 'tags': 'personal'}), 8 Result(page_content='Problems in Controller-Service-Repository Architecture\n\nThe Controller-Service-Repository (CSR) architecture presents several backend development challenges. Problem 1 relates to unclear separation of responsibilities among services, causing domain logic to scatter or duplicate. Problem 2.1 highlights the difficulty of managing side effects like database changes or notifications spread across multiple services, leading to broken open-closed principles and poor documentation. Problem 2.2 addresses challenges with transactional side effects, such as sending emails only after successful transactions, which are complex to implement in CSR.\n\n### Problems of Controller-Service-Repository (CSR) Architecture\n\n\nIn the course of development several backend problems in CSR-architecture pop up easily that I always feel painful:\n\n<Example>\n\n**Problem 1 (Not easy to have clear separation of responsibility among services).** From CSR point of view, a service is just an interface to handle a request, and *nothing more*, that causes the problem.\n\nAs time goes by, developer is easy to build *multiple services* serving a similar purpose. \n\nSuppose I have a project system, now I want to design a service to let project owner add someone as a member. You can go either way:\n\n- `ProjectService.addMember`\n\n- `MemberService.joinProject`\n\nThere is no true or false among the choices, but our domain logic now *can go anywhere*, or even *repeatedly defined* like the `join-project` example above. \n\n</Example>\n\n<Example>\n\n**Problem 2.1 (Side Effects Become a Mess).** When dealing with side effects, namely:\n- Some change in a table will cause other events to happen, such as another change in another table or sending notification, etc.\n\nThe only way the CSR-architecture can handle it is to add the handling of extra logics at the end or even at the middle of *ALL existing related services*. Problems arise:\n\n- First, the Open-Closed principle is easy to break and maintaining this chain of side effects is exhausting. \n\n- Second, this kind of side effect is *not easy to be documented*, the domain logic involved is hard to be traced and hard to be understood by new team members trying to participate in adjusting that domain logic.\n\n</Example>\n\n\nWorse still:\n\n<Example>\n\n**Problem 2.2 (Side Effect can be Transactional).** There are two kinds of side effects:\n\n- Atomic\n\n- Non-atomic\n\nDo you want the whole successful transaction be ruined and rollbacked by the failure of sending an email notification? \n\nIt is not trivial to implement a "transactional" side effect (e.g., send the email only when a transaction has been commited), especially when that side effect is dispatched in the middle of a chain of transaction script.\n\n</Example>', metadata={'title': 'Problems in Controller-Service-Repository That are Solvable by Tactical Design in DDD (Domain Driven Design)', 'tags': 'DDD,kotlin'}), 9 Result(page_content="New Side Project: Commercial Timetable System for Art School\n\nThis article from James Lee's blog announces the addition of a new side project to his portfolio which involves a Commercial Timetable System designed for an Art School. The project utilizes Domain-Driven Design (DDD) principles, implemented with Kotlin and Spring Boot, and includes considerations for system design. Readers are invited to learn more via the provided link.\n\nPlease check this link:\n\n- [Commercial Timetable System for an Art School](/portfolio/Commercial-Timetable-System-for-an-Art-School)", metadata={'title': 'New Side Project using DDD was Added to Portfolio!', 'tags': 'DDD,kotlin,springboot,system-design'}), 10 Result(page_content='Career Attempts and Transition Away from Art 2017-2018\n\nIn 2017, James Lee engaged in various art-related collaborations, including working on local games and visual novels. Though applying to many game companies with an Art Portfolio, he received little response, prompting doubts about connections or skills. Eventually, he moved to Shenzhen with a game development team for an underpaid art position in 2017, facing challenging conditions. By 2018, his artistic dreams concluded, and he transitioned into software development as reflected on his website.\n\n### 2017 年\n\n\n#### 奇怪的合作機會\n\n\n在求職其間偶然地遇到奇怪的合作,例如︰\n\n- [Hilton Yuen](https://www.hiltonyuen.com/) 的桌遊,但我忘記名子了。\n- [Oice 視角小說 (可先關掉聲音)](https://oice.com/story/8237eaf90ee94ba68e113aa2449a4704)\n\n <customimage src="/assets/img/2025-10-08-22-20-28.png" width="500"></customimage>\n\n#### 投履歷,CV.pdf\n\n每月都在追求進步,只是還沒到可以找到工作的地步。那時後已經開始對各遊戲公司投履歷,基本上都沒有回音。我都開始懷疑是我能力問題還是沒有 connection 的問題了。\n\n那時基本上都是投這個用 [InDesign 製作的 PDF](/assets/portfolios/pdfs/ArtPortfolio.pdf)。\n\n#### 2017年底,到大陸發展\n\n我也忘記甚麼原因跟一個本地獨立遊戲勾搭上了。當時跟遊戲 [龍之氣息](https://play.google.com/store/apps/details?id=com.Company.BreathofDragons&hl=zh_HK) 的作者合作。\n\n<Example>\n\n**題外話.** 我也沒想到到了 2024 年我以前的插圖依然活躍在遊戲中 ...\n\n[](/assets/img/2025-10-08-22-32-09.png)\n\n</Example>\n\n\n還記得當時薪金說好是 $x$ 港幣,成團後 (集齊其他美術,策劃,等等) 我的薪金直接砍成 $\\frac{1}{3}x$ 人民幣。\n\n因為要往內地發展,這個 $\\frac{1}{3}x$ 其實是深圳當時的平均薪金。應該是"老闆"當時也不清楚深圳的巿價。也擺了,反正缺的是經驗,做美術也不求溫飽,忍着微薄的薪金幹下去,祈求未來能打出一個新天地 (最後當然是不行)。\n\n整個團隊最後移居深圳龍岡當黑奴。\n\n### 2018 年 1 月 - 2018 年 12 月初,正式結束美術夢\n\n渾沌的美術生活,充實 (爆肝) 卻不寫意,就不着墨了。等我回憶突然回來可能寫另外一篇曰記講講這一年發生了甚麼。說實話不太願意回憶起來。\n\n往後的生涯規劃也跟美術沾不上邊了。如同你到這個人網頁所見,變成了一隻小碼農。', metadata={'tags': 'art,personal', 'title': '不工作學畫畫,3 年的美術人生'}), 11 Result(page_content='Video Demonstration and Overview\n\nThe article begins with a video demonstrating Server-Sent Events (SSE) in action, showing that a server can send events back to a client and detect client disconnection.\n\n### Video Demonstration\n\n<Center>\n<iframe width="560" height="315" src="https://www.youtube.com/embed/gMSWdAZhupY" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>\n</Center>\n<p></p>\nThis demonstrated:\n\n- We can send event back to client;\n- We can determine whether a client is disconnected.', metadata={'tags': 'SSE,express,java,nodejs,springboot', 'title': 'Server Sent Event in Java and Node.js Backend'})])
7.3. The Blog Exploer
Actually I have deployed the model which works amazingly well! You can play around with my chatbot to ask me about some technical questions.

But the main purpose of this chatbot is to find out articles using natural languages, which is super helpful for me as a routine blogger!
8. Reference
- Ed Donner, AI Engineer Core Track: LLM Engineering, RAG, QLoRA, Agents, Udemy